
how_to_build_rag_model_by_dify_and_neo4j
基于neo4j数据库和dify大模型框架的rag模型搭建
本文主要讲述关于如何从pdf文档中提取数据并用于生成知识图谱,搭建基于知识图谱的rag模型的过程。
(其实就是知识库?有一说一因为根本没上课其实我也不知道我做的是啥,但是大概是符合课设要求的)
前置准备
neo4j数据库
neo4j用于存储从pdf文档中提取的数据。
安装方式有docker或者直接安装两种方式。
可以参考https://neo4j.com/docs/operations-manual/current/installation/linux/debian/
由于我使用的是直接安装的,因此docker安装方式就不作过多介绍了。
直接安装的配置如下:
1 | 主机: Ubuntu 22.04(其实是虚拟机) |
由于neo4j是依赖于java运行的,因此需要java环境,如果之前没安装过java的话那很幸运,只需要一个java即可;如果之前已经安装过java,则需要对java版本的优先级进行调整(具体去问ai)。有一说一,其实不推荐安装最新版,因为大多数ai对最新版都不怎么熟悉,很容易出错,不会由于当时我已经装完了,所以只能硬着头皮往下干。(沉没成本不参与重大决策?)
安装流程
1 | # 检验java是否安装 |
第一步是安装java,第二步是将neo4j所在的库添加到apt源中然后用apt安装。
(其实可以用deb文件包然后dpkg安装,但是官方文档给的会显示不是一个合法的deb文件,肥肠奇怪,无法理解)
安装完之后将neo4j启动
1 | sudo neo4j start |
启动成功之后会显示
之后自动使用守护进程运行,转入后台。
在回显中可以看到plugins目录和conf目录。先进入/var/lib/neo4j/labs中,将其中的apoc开头的jar包拷贝到plugins目录中。如果有需要,还可以去apoc的github仓库中安装额外的补全插件(插件地址为:https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/2025.04.0/apoc-2025.04.0-extended.jar)。
然后进入/etc/neo4j目录中,其中存在neo4j.conf文件,先对其进行修改,修改之后如下。这个修改使得在neo4j的浏览器页面中可以调用apoc函数。
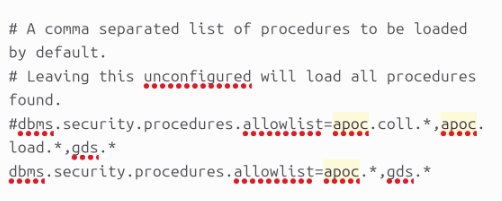
再作修改,使得其他主机能够访问neo4j。如果在容器中还可能用到host.docker.internal(只适用于macos和windows),当然直接安装就没有这种问题了。
1 | # neo4j.conf |
再在neo4j.conf的同级目录中新建一个apoc.conf,内容为
1 | apoc.import.file.enabled=true |
这样neo4j就算安装完成了。
neo4j的浏览器地址为http://ip:7474/browser/,bolt端口为7687(默认是这样)
使用docker安装的话可以使用-v将docker中的目录映射到主机中,尤其记得要将plugin目录和conf目录映射出来,不然就得使用docker exec进入docker容器中再安装插件,比较麻烦。
dify框架
dify框架的安装比较简单,直接使用docker就可以完成安装,而且和neo4j不存在端口冲突。
首先从github克隆下dify的仓库,按照readme文档中的内容去做即可。
1 | git clone https://github.com/langgenius/dify.git |
如果没有docker compose的可以试一下docker-compose,不然就是没安装。
1 | # 关闭dify的命令,在docker-compose.yaml目录下 |
dify的浏览器访问地址为ip,默认端口为80
搭建思路
1 | 提取数据 -> 建立数据结构 -> 存入数据库 -> 搭建检索系统 -> 输入llm -> 得到最终输出 |
关于提取数据、建立数据结构、存入数据库这三个部分,可将其视为一个部分,也就是将文档中的数据存入数据库。
提取数据存入数据库
提取数据
数据存储在pdf文档中,在对数据进行读取时还需要对其进行词义分析,将其分类、分段,保留它原先的意思,但是又便于检索。
好在这一步不需要我们手动完成,只需要对数据进行提取,然后交给专门的语言模型处理即可😋。
由于数据是存储在pdf文档中,可以使用pdfplumer进行读取,再使用spacy对其进行分段。
1 | 补充关于token的小知识: |
所以说将语句进行分段是必要的。
1 | # 核心代码 |
在上述代码中使用spacy中的专门处理中文的模型zh_core_web_sm对从pdf中提取出的数据进行分句,并给其标注信息,如页号等。
1 | 当然也可以使用其他的类似模型或者更好的模型,使用更好的模型得到的效果也就更好 |
生成向量索引
token的向量索引,也称为Token Embeddings。在token的向量索引中包含了token的词义信息,也可以快速的检索到token,在之后的检索系统中会用到。
1 | 如果不使用向量索引的话,也可以根据输入的关键词对数据库进行检索,这种就很好理解了。 |
生成向量索引的过程自然也是不需要我们多虑的,也有专门的模型用于创建向量索引。
生成的向量索引维度为384。
1 | model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2') |
1 | 模型选择并不唯一,但是越好的模型生成的效果肯定是更好的 |
存储到数据库
接下来将其存储到数据库中,在本文中使用的是neo4j数据库,类型为nosql,主要是用于图的存储。
在存储到数据库中时需要创建不同的节点并且指出其相关关系,例如在如下代码中就创建了book节点和chunk节点两种节点,其中chunk节点属于book节点,构成了图。还添加了一些额外的meta data,便于管理和识别。
1 | driver = GraphDatabase.driver("bolt://ip:port", auth=("neo4j", "password")) |
创建数据库索引
虽然听起来跟之前的向量索引有些相似,但是不是一个东西,之前的索引是作为节点的数据而存在,而现在要创建的数据库索引是为了提升数据库的查询效率而使用的,并且能够高效地执行语义相似度搜索,为检索系统的搭建作准备。
1 | driver = GraphDatabase.driver("bolt://ip:port", auth=("neo4j", "password")) |
(这里有一个坑,就是如果你使用低版本的neo4j的话,ai会使用apoc中跟vector相关的代码,就可以直接使用。但是由于版本太高了,vector函数被内置到neo4j里,apoc的函数就废弃了,这个函数还是从官方文档里搜出来的,肥肠难受😫)
搭建检索系统
所有对数据的前置准备已经完成,接下来要搭建的是检索系统,用于从数据库中检索出跟用户输入最相关的词条。
首先,要将用户输入的内容也转为向量索引,才好进行比较。
然后使用neo4j中内置的vector比较函数,将相关的数据从neo4j中取出,按照相关性进行排序。
为了提高相关性的准确度,这里可以使用reranker模型进行重排序,得到真正相关性更高的结果。
然后再根据得到相关内容,回到文档中原来的位置,提取其上下文,提高答案的正确率。
因此,检索系统分为四个部分。
1 | 输入转换 -> 向量检索 -> 重排序 -> 提取上下文 |
后两个步骤是可选的,在我写的代码中设置了选项,在使用时可选也可不选。只是不选的话得到的答案比较没人样,或者直接得不到答案而已。
听起来比较简单,其实做起来也不是很难(毕竟大部分代码都不是我写的)。
不过由于后续要使用dify框架,所以这里将检索系统封装为了一个http的api,便于后续的调用,使用的是fastapi。(主要是我感觉dify里面的代码执行应该是不允许搞这么复杂的,当然我也没仔细研究过)
输入llm
这个部分也比较简单,选择一个自己喜欢的模型,然后设置好prompt和参数就好了。
prompt可参考:
1 | 你是一个专业书籍问答助手,请严格基于用户提供的<上下文>回答问题。 |
实际上llm部分是在dify框架中完成的,所以要先启动dify,如何启动在前置准备章节中已经有详细描述,但是还有一个点没提到,那就是需要注册一个模型api平台的账号,这里我选择的是硅基流动,其实用deepseek或者豆包之类的平台也是一样的,只要它们有提供api的接口就可以。
硅基流动注册
注册只需要手机号验证就可以了(ps:我本来想用github登的,但是登完还是要手机号😓)
如果没有邀请码可以填我的:f1EqQpK5
双方都会获得免费的2000w tokens,我当时注册也是随便搜了一个邀请码就填上了。
注册成功之后在左侧的工具栏中有一个api密钥,新建一个,密钥描述随便写(当然填dify也可以)。
dify初始化
第一次进入dify会要求输入管理员账户,如果是自己用的话随便输一个也没事,有别人要用的话还是设置得复杂一点。
登录成功之后点击右上角的头像>设置>模型供应商,可以看到有很多家,选择硅基流动,输入之前新建的api密钥即可。
这就算初始化完成了。
dify_chatflow搭建
接下来根据之前的思路,也就是数据->检索->llm的流程搭建dify工作流,注意已经将检索系统封装为http的api并且在本地启动,并且数据也已经输入到数据库中。
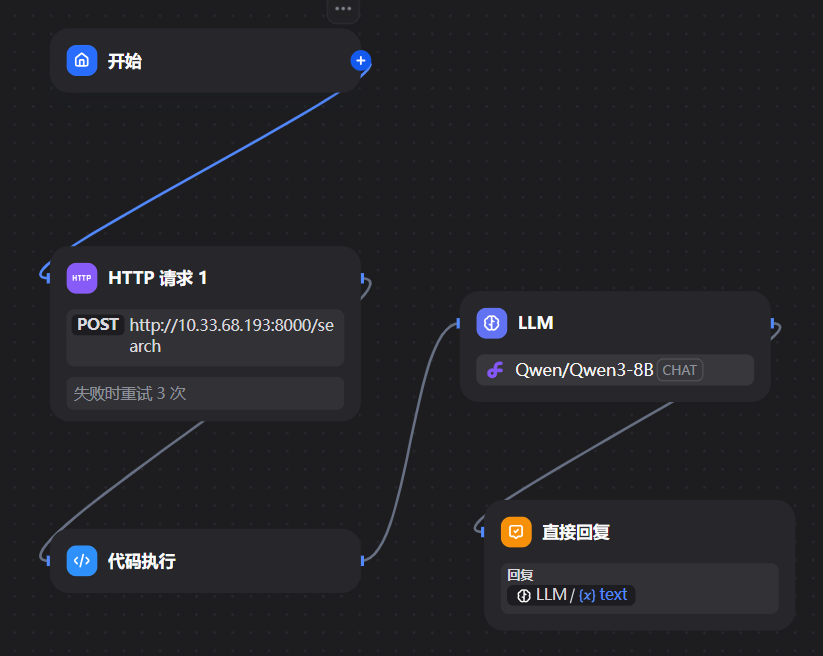
工作流的流程很简单,看看其内部构造
http请求
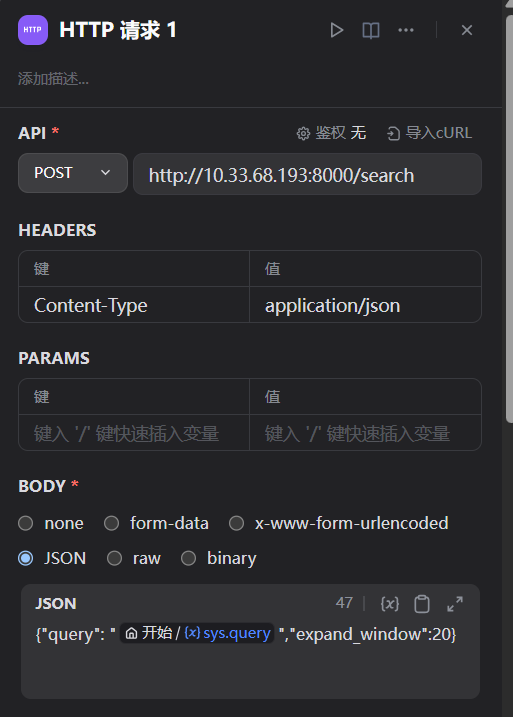
封装了search接口,query是用户在对话框的输入,expand_window是上下文的窗口大小,默认开启了上下文检索但是没有开启重排序,参数类型为json。
代码执行
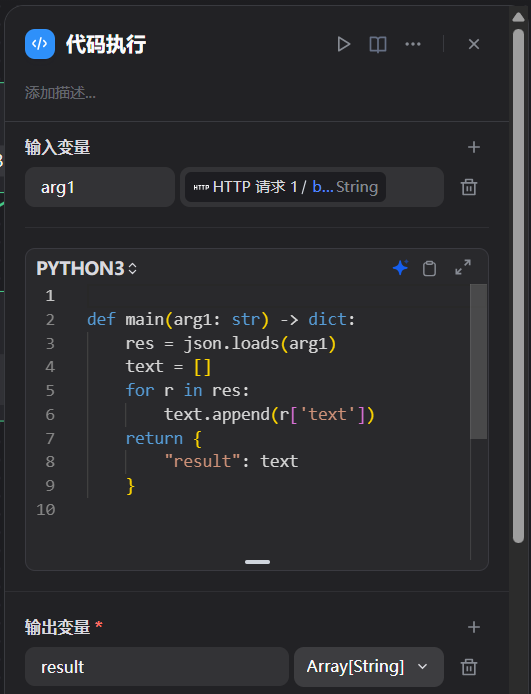
使用http请求的返回值作为输入,解析json,并且提取其中的text的值,返回值为list。
llm
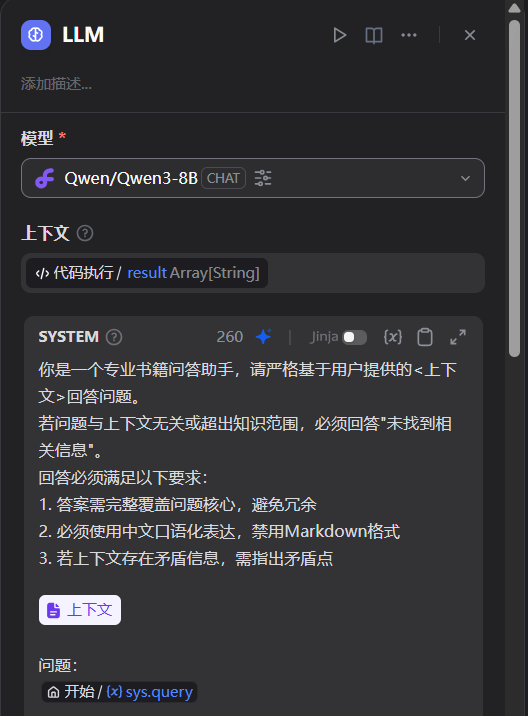
prompt在上文中已给出,使用的是千问8B的模型(因为不要钱),真好,也可以自己在主机上跑一个开源的大模型,但是我指定不行,等下笔记本烧了😓。
最后一个选直接回复即可,以llm的输出作为输入。
对于小段文本的测试效果还不错,但是没有使用指标进行度量。其实是可以对性能进行评估的,但是我比较懒,课设的话没必要纠结太多(
而且如果要人工评估的话就要打标签,要用ai评估的话好像也比较麻烦,还得跑很多轮。
dify_workflow搭建
和chatflow差不多,只是开始时需要输入,结束时需要输出。
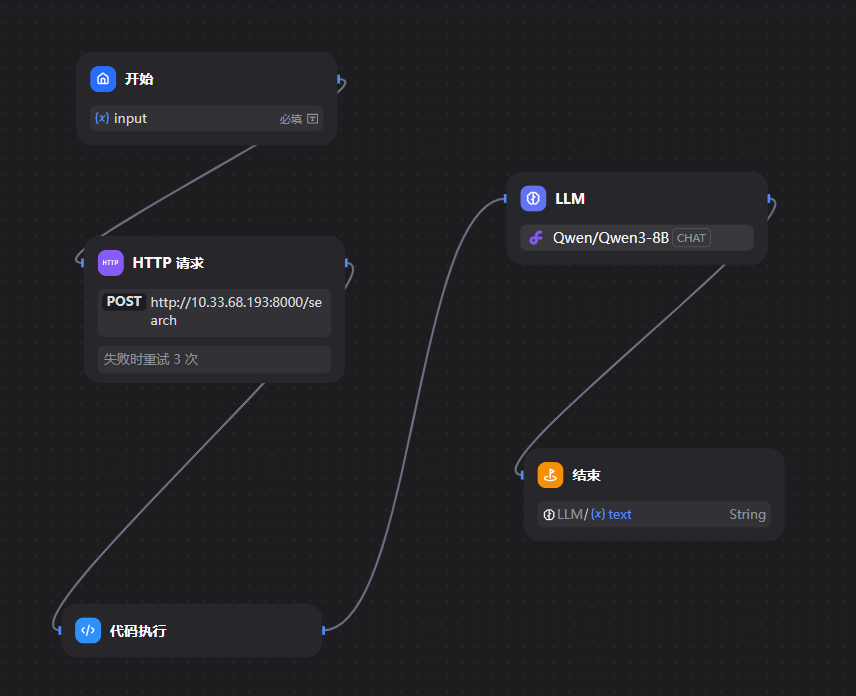
改进方案
可以改进的方向有很多
1、在分句和创建向量时使用更好的模型
2、额外安装一个索引数据库,在neo4j中只存放索引的索引,可以有效提高查询的效率。
3、额外安装一个缓存数据库,如redis,也可以有效提高查询效率。
4、搭建检索系统时可以进行加权,对不同的权值进行调整
5、使用付费的高级llm和更加高级、专业的prompt
6、优化数据结构,例如在搭建的过程中我其实想给出每段文章的页码,但是这样的话要对数据结构进行修改,所以就没有做了
后续补充
今天想起来写报告的时候突然发现项目起不来了,一查才发现原来hugging face一直是被ban的,所以在import 模型之前就要先换源。(昨天梯子发力了我说,这都能跑起来)
1 | import os |
然后又发现报告里的检测评估居然是强制要求,所以只能跑个评测集了😭😭😭。
rag评估
虽然有搜索到开源的评估方法,比如RAGAS,但是发现这个是要有标准答案的。我哪知道标准答案是啥,所以就废弃这个选项吧,只看看跑出来的答案有没有个人样就好了。
所以以下内容大部分是关于如何调用dify的api在后端运行工作流以及其中的一些坑点。
ragas评估时所需的数据结构如下
1 | data = { |
当然我不是按照这个来的,正如我之前所说,我根本没有标准答案,不过我发现其他的都是可以得到的。
数据生成
首先使用ai生成100个问题,别管对不对了,总不能手写100个问题吧。
然后调用dify的后端进行工作流调用,关于调用的细节在api文档中已经给出,范例如下:
1 | test_datas = [] |
API KEY是用于识别工作流的,通过这个接口就可以在python代码中运行工作流而不是通过web端。如果不想通过python也可以发布工作流之后批量运行工作流。但是我没试过。
从提前准备好的问题文件中读取问题,然后调用dify的api执行,执行完成之后再输入文件,就可以得到所有问题的答案,而检索到的文档可以在调用之前封装的http的api的过程中也输入文件,这样一来,最后再合并成一个文件,就可以得到只缺少标准答案的文件了😊😊😊🍾🍾🍾
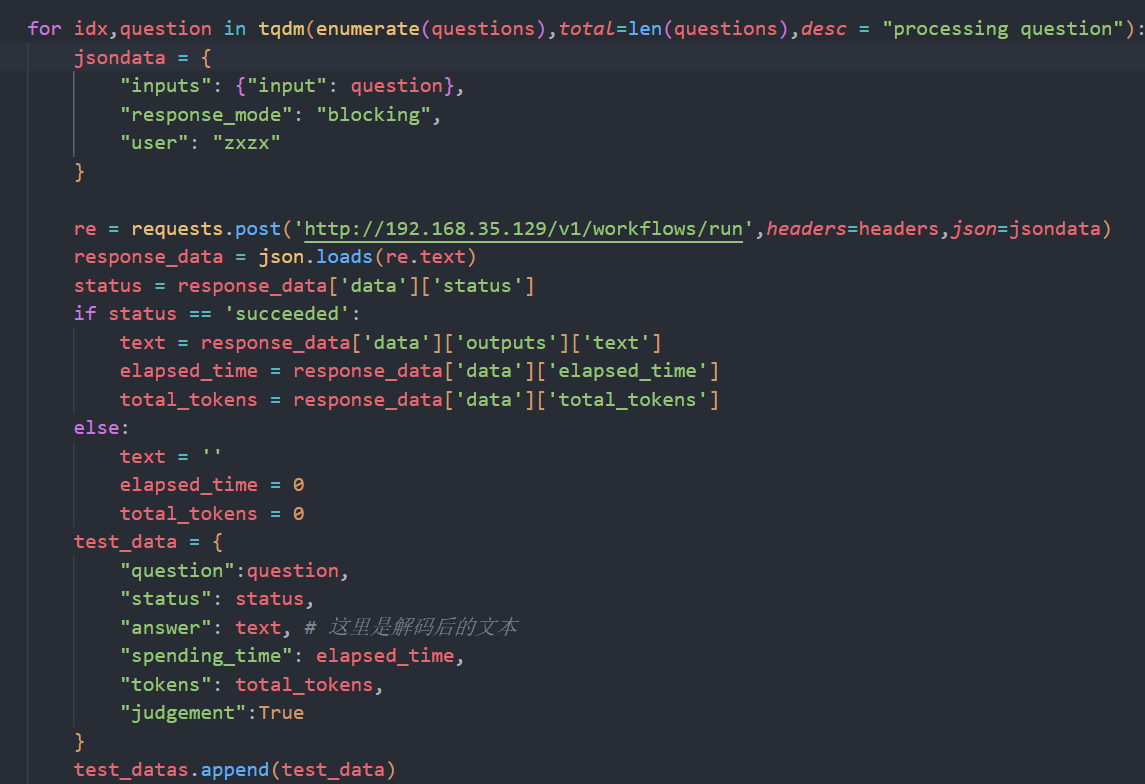
具体代码如上,毫无技术可见的request,但是需要注意的是,最好每次执行循环就把返回包保存一次,不然如果中途崩了就会发现白跑了半个小时。
数据分析
由于没有标准答案,所以只是计算了一下答案的平均查询时间和平均长度,没有对rag模型作量化的评估,有待补充。虽然我肯定是懒得再做了。
源代码
评测集的问题和答案都已经更新到仓库中。
1 | https://github.com/zx2023qj/rag_model |